网卡的 Ring Buffer 详解
1. 网卡处理数据包流程
网卡处理网络数据流程图:
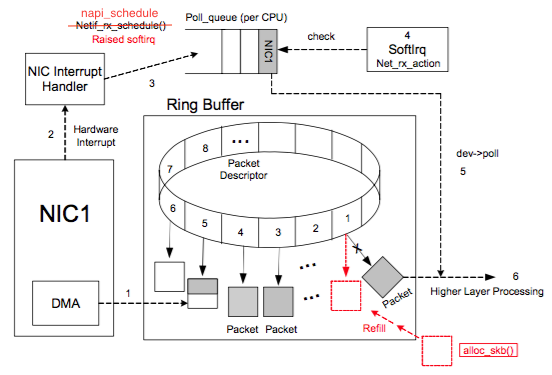
图片来自参考链接1
上图中虚线步骤的解释:
- DMA 将 NIC 接收的数据包逐个写入 sk_buff ,一个数据包可能占用多个 sk_buff , sk_buff 读写顺序遵循FIFO(先入先出)原则。
- DMA 读完数据之后,NIC 会通过 NIC Interrupt Handler 触发 IRQ (中断请求)。
- NIC driver 注册 poll 函数。
- poll 函数对数据进行检查,例如将几个 sk_buff 合并,因为可能同一个数据可能被分散放在多个 sk_buff 中。
- poll 函数将 sk_buff 交付上层网络栈处理。
完整流程:
- 系统启动时 NIC (network interface card) 进行初始化,系统分配内存空间给 Ring Buffer 。
- 初始状态下,Ring Buffer 队列每个槽中存放的 Packet Descriptor 指向 sk_buff ,状态均为 ready。
- DMA 将 NIC 接收的数据包逐个写入 sk_buff ,一个数据包可能占用多个 sk_buff ,sk_buff 读写顺序遵循FIFO(先入先出)原则。
- 被写入数据的 sk_buff 变为 used 状态。
- DMA 读完数据之后,NIC 会通过 NIC Interrupt Handler 触发 IRQ (中断请求)。
- NIC driver 注册 poll 函数。
- poll 函数对数据进行检查,例如将几个 sk_buff 合并,因为可能同一个数据可能被分散放在多个 sk_buff 中。
- poll 函数将 sk_buff 交付上层网络栈处理。
- poll 函数清理 sk_buff,清理 Ring Buffer 上的 Descriptor 将其指向新分配的 sk_buff 并将状态设置为 ready。
2. 多 CPU 下的 Ring Buffer 处理
因为分配给 Ring Buffer 的空间是有限的,当收到的数据包速率大于单个 CPU 处理速度的时候 Ring Buffer 可能被占满,占满之后再来的新数据包会被自动丢弃。
如果在多核 CPU 的服务器上,网卡内部会有多个 Ring Buffer,NIC 负责将传进来的数据分配给不同的 Ring Buffer,同时触发的 IRQ 也可以分配到多个 CPU 上,这样存在多个 Ring Buffer 的情况下 Ring Buffer 缓存的数据也同时被多个 CPU 处理,就能提高数据的并行处理能力。
当然,要实现“NIC 负责将传进来的数据分配给不同的 Ring Buffer”,NIC 网卡必须支持 Receive Side Scaling(RSS) 或者叫做 multiqueue 的功能。RSS 除了会影响到 NIC 将 IRQ 发到哪个 CPU 之外,不会影响别的逻辑了。数据处理过程跟之前描述的是一样的。
3. Ring Buffer 相关命令
在生产实践中,因 Ring Buffer 写满导致丢包的情况很多。当环境中的业务流量过大且出现网卡丢包的时候,考虑到 Ring Buffer 写满是一个很好的思路。
总结下 Ring Buffer 相关的命令:
3.1 网卡收到的数据包统计
[root@server-20.140.beishu.polex.io ~ ]$ ethtool -S em1 | more
NIC statistics:
rx_packets:
tx_packets:
rx_bytes:
tx_bytes:
rx_broadcast:
tx_broadcast:
rx_multicast:
tx_multicast:
RX 就是收到数据,TX 是发出数据。
3.2 带有 drop 字样的统计和 fifo_errors 的统计
[root@server-20.140.beishu.polex.io ~ ]$ ethtool -S em1 | grep -iE "error|drop"
rx_crc_errors: 0
rx_missed_errors: 0
tx_aborted_errors: 0
tx_carrier_errors: 0
tx_window_errors: 0
rx_long_length_errors: 0
rx_short_length_errors: 0
rx_align_errors: 0
dropped_smbus: 0
rx_errors: 0
tx_errors: 0
tx_dropped: 0
rx_length_errors: 0
rx_over_errors: 0
rx_frame_errors: 0
rx_fifo_errors: 79270
tx_fifo_errors: 0
tx_heartbeat_errors: 0
rx_queue_0_drops: 16669
rx_queue_1_drops: 21522
rx_queue_2_drops: 0
rx_queue_3_drops: 5678
rx_queue_4_drops: 5730
rx_queue_5_drops: 14011
rx_queue_6_drops: 15240
rx_queue_7_drops: 420
发送队列和接收队列 drop 的数据包数量显示在这里。并且所有 queue_drops 加起来等于 rx_fifo_errors。所以总体上能通过 rx_fifo_errors 看到 Ring Buffer 上是否有丢包。如果有的话一方面是看是否需要调整一下每个队列数据的分配,或者是否要加大 Ring Buffer 的大小。
3.3 查询 Ring Buffer 大小
[root@server-20.140.beishu.polex.io ~ ]$ ethtool -g em1
Ring parameters for em1:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
RX 和 TX 最大是 4096,当前值为 256 。队列越大丢包的可能越小,但数据延迟会增加。
3.4 调整 Ring Buffer 队列数量
[root@server-20.140.beishu.polex.io ~ ]$ ethtool -l em1
Channel parameters for em1:
Pre-set maximums:
RX:
TX:
Other:
Combined:
Current hardware settings:
RX:
TX:
Other:
Combined:
Combined = 8,说明当前 NIC 网卡会使用 8 个进程处理网络数据。
更改 eth0 网卡 Combined 的值:
ethtool -L eth0 combined
需要注意的是,ethtool 的设置操作可能都要重启一下才能生效。
3.4 调整 Ring Buffer 队列大小
查看当前 Ring Buffer 大小:
[root@server-20.140.beishu.polex.io ~ ]$ ethtool -g em1
Ring parameters for em1:
Pre-set maximums:
RX:
RX Mini:
RX Jumbo:
TX:
Current hardware settings:
RX:
RX Mini:
RX Jumbo:
TX:
看到 RX 和 TX 最大是 4096,当前值为 256。队列越大丢包的可能越小,但数据延迟会增加.
设置 RX 和 TX 队列大小:
ethtool -G em1 rx
ethtool -G em1 tx
3.5 调整 Ring Buffer 队列的权重
NIC 如果支持 mutiqueue 的话 NIC 会根据一个 Hash 函数对收到的数据包进行分发。能调整不同队列的权重,用于分配数据。
[root@server-20.140.beishu.polex.io ~ ]$ ethtool -x em1
RX flow hash indirection table for em1 with RX ring(s):
:
:
:
:
:
:
:
:
:
:
:
:
:
:
:
:
RSS hash key:
Operation not supported
我的 NIC 一共有 8 个队列,一共有 128 个不同的 Hash 值,上面就是列出了每个 Hash 值对应的队列是什么。最左侧 0 8 16 是为了能让你快速的找到某个具体的 Hash 值。比如 Hash 值是 76 的话我们能立即找到 72 那一行:”72: 4 4 4 4 4 4 4 4”,从左到右第一个是 72 数第 5 个就是 76 这个 Hash 值对应的队列是 4 。
设置 8 个队列的权重。加起来不能超过 128 。128 是 indirection table 大小,每个 NIC 可能不一样。
3.6 更改 Ring Buffer Hash Field
分配数据包的时候是按照数据包内的某个字段来进行的,这个字段能进行调整。
[root@server-20.140.beishu.polex.io ~ ]$ ethtool -n em1 rx-flow-hash tcp4
TCP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
L4 bytes & [TCP/UDP src port]
L4 bytes & [TCP/UDP dst port]
也可以设置 Hash 字段:查看 tcp4 的 Hash 字段。
ethtool -N em1 rx-flow-hash udp4 sdfn
sdfn 需要查看 ethtool 看其含义,还有很多别的配置值。
3.6 IRQ 统计
/proc/interrupts 能看到每个 CPU 的 IRQ 统计。一般就是看看 NIC 有没有支持 multiqueue 以及 NAPI 的 IRQ 合并机制是否生效。看看 IRQ 是不是增长的很快。
参考链接:
https://ylgrgyq.github.io/2017/07/23/linux-receive-packet-1/
网卡的 Ring Buffer 详解的更多相关文章
- 前端后台以及游戏中使用Google Protocol Buffer详解
前端后台以及游戏中使用Google Protocol Buffer详解 0.什么是protoBuf protoBuf是一种灵活高效的独立于语言平台的结构化数据表示方法,与XML相比,protoBuf更 ...
- 使用Squid做代理服务器,Squid单网卡透明代理配置详解(转)
使用Squid做代理服务器 说到代理服务器,我们最先想到的可能是一些专门的代理服务器网站,某些情况下,通过它们能加快访问互联网的速度.其实,在需要访问外部的局域网中,我们自己就能设置代理,把访问次数较 ...
- java NIO Buffer 详解(1)
1.java.io 最为核心的概念是流(stream),面向流的编程,要么输入流要么输出流,二者不可兼具: 2.java.nio 中拥有3个核心概念: Selector Channel, Buffe ...
- 10.Linux网卡的配置及详解
1.网卡配置文件在/etc/sysconfig/network-scripts/下: [root@oldboy network-scripts]# ls /etc/sysconfig/network- ...
- Potocol Buffer详解
protocol安装及使用 上一篇博文介绍了一个综合案例,这篇将详细介绍protocol buffer. 为什么使用protocol buffer? java默认序列化效率较低. apache的thr ...
- Protocol Buffer详解
1.Protocol Buffer 概念 Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 ...
- 网卡也能虚拟化?网卡虚拟化技术 macvlan 详解
本文首发于我的公众号 Linux云计算网络(id: cloud_dev),专注于干货分享,号内有 10T 书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫. 01 macv ...
- Java NIO中的Buffer 详解
Java NIO中的Buffer用于和NIO通道进行交互.如你所知,数据是从通道读入缓冲区,从缓冲区写入到通道中的.缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存.这块内存被包装成NIO ...
- mysql-5.7 innodb change buffer 详解
一.innodb change buffer 介绍: 1.innodb change buffer 是针对oltp场景下磁盘IO的一种优化(我也感觉这个不太像人话,但是它又非常的准确的说明 innod ...
随机推荐
- 优雅地实现CSS Animation delay心得
话不多说直接开讲: 1.需求: 等待元素A的动画加载完,再加载B元素的动画(下图中A为大熊猫,B为下方卡片) 先来看下最后的效果啦: 2.初始思路: 在B元素的动画属性上加上delay(延迟,使得这个 ...
- remove方法
1.jQuery的remove()方法 http://www.365mini.com/page/jquery-remove.htm ①返回值是jquery对象本身 所以可以做删除再添加的操作 // 移 ...
- 超实用的JavaScript代码段 Item5 --图片滑动效果实现
先上图 鼠标滑过那张图,显示完整的哪张图,移除则复位: 简单的CSS加JS操作DOM实现: <!doctype html> <html> <head> <me ...
- ES7 Async/Await 陷阱
什么是Async/Await ES6新增了Promise函数用于简化项目代码流程.然而在使用promise时,我们仍然要使用callback,并且并不知道程序要干什么,例如: function doS ...
- websocket(一)--握手
最近在琢磨怎么实现服务端的消息推送,因为以前都是通过客户端请求来获取信息的,如果需要实时信息就得轮询,比如通过ajax不停的请求. websocket相当于对HTTP协议进行了升级,客户端和服务端通过 ...
- 玩转web之ligerui(一)---ligerGrid重新指定url
请珍惜小编劳动成果,该文章为小编原创,转载请注明出处. 在特定情况下,我们需要重新指定ligerGrid的url来获取不同的数据,在这里我说一下我用的方法: 首先先定义一个全局变量,然后定义liger ...
- Log4j2中的同步日志与异步日志
1.背景 Log4j 2中记录日志的方式有同步日志和异步日志两种方式,其中异步日志又可分为使用AsyncAppender和使用AsyncLogger两种方式. 2.Log4j2中的同步日志 所谓同步日 ...
- registration_db.go
, atomic.LoadInt64(&p.peerInfo.lastUpdate)) if now.Sub(cur) > inactivityTimeout || p. ...
- 深入css布局篇(2) — 定位与浮动
深入css布局(2) - 定位与浮动 在css知识体系中,除了css选择器,样式属性等基础知识外,css布局相关的知识才是css比较核心和重要的点.今天我们来深入学习一下css布局相关的知识 ...
- eclipse 内存优化
eclipse.ini配置如下: -Dfile.encoding=UTF-8-Xms512m-Xmx512m-Xmn170m-Xverify:none 注意-Xmn是-Xmx的三分之一关系 可以根据自 ...