最小生成树之Kruskal(克鲁斯卡尔)算法
学习最小生成树算法之前我们先来了解下下面这些概念:
树(Tree):如果一个无向连通图中不存在回路,则这种图称为树。
生成树 (Spanning Tree):无向连通图G的一个子图如果是一颗包含G的所有顶点的树,则该子图称为G的生成树。生成树是连通图的极小连通子图。这里所谓极小是指:若在树中任意增加一条边,则将出现一条回路;若去掉一条边,将会使之变成非连通图。
最小生成树(Minimum Spanning Tree,MST):或者称为最小代价树Minimum-cost Spanning Tree:对无向连通图的生成树,各边的权值总和称为生成树的权,权最小的生成树称为最小生成树。常用于网络构建等建设性问题的优化。
构成生成树的准则有三条:
1、 必须只使用该网络中的边来构造最小生成树。
2、必须使用且仅使用n-1条边来连接网络中的n个顶点
3、不能使用产生回路的边。
构造最小生成树的算法主要有:克鲁斯卡尔(Kruskal)算法和普利姆(Prim)算法他们都遵循以上准则。
克鲁斯卡尔算法的基本思想是以边为主导地位,始终选择当前可用(所选的边不能构成回路)的最小权植边。所以Kruskal算法的第一步是给所有的边按照从小到大的顺序排序。这一步可以直接使用库函数qsort或者sort。接下来从小到大依次考察每一条边(u,v)。
具体实现过程如下:
1、设一个有n个顶点的连通网络为G(V,E),最初先构造一个只有n个顶点,没有边的非连通图T={V,空},图中每个顶点自成一格连通分量。
2、在E中选择一条具有最小权植的边时,若该边的两个顶点落在不同的连通分量上,则将此边加入到T中;否则,即这条边的两个顶点落到同一连通分量 上,则将此边舍去(此后永不选用这条边),重新选择一条权植最小的边。
3、如此重复下去,直到所有顶点在同一连通分量上为止。
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set; public class Kruskal {
private final List<Edge> edgeList;
private final int n;//总顶点数 private Set<Edge> T = new HashSet<>();//生成树的边集
private Map pntAndNode = new HashMap(); public Set<Edge> getT() {
buildMST();
return T;
} public Kruskal(List<Edge> edgeList, int n) {
this.edgeList = edgeList;
//为每个顶点建立一个并查集的点
for (Edge edge : edgeList) {
pntAndNode.put(edge.getStart(), new UnionFind.UFNode());
pntAndNode.put(edge.getEnd(), new UnionFind.UFNode());
}
this.n = n;
} public static void main(String[] args) {
List<Edge> edgeList = build();
Kruskal obj = new Kruskal(edgeList, 5);
// obj.buildMST();
for (Edge e : obj.getT()) {
System.out.println(e);
}
} private static List<Edge> build() {
List<Edge> l = new ArrayList<>();
l.add(new Edge("C", "D", 1));
l.add(new Edge("C", "A", 1));
l.add(new Edge("C", "E", 8));
l.add(new Edge("A", "B", 3));
l.add(new Edge("D", "E", 3));
l.add(new Edge("B", "C", 5));
l.add(new Edge("B", "E", 6));
l.add(new Edge("B", "D", 7));
l.add(new Edge("A", "D", 2));
l.add(new Edge("A", "E", 9)); return l;
} /*构建MST的核心方法*/
private void buildMST() {
Collections.sort(edgeList);//排序
//迭代
for (Edge e : edgeList) {
if (!ok(e))
continue;
//确认过了,就把边都加入
T.add(e); if (T.size() == n - 1)
return;//生成树的边数==总顶点数-1 =》 所有点都已经连接
}
} //并查集中查询e 的起点和终点是否在一个集中
private boolean ok(Edge e) {
UnionFind.UFNode x = (UnionFind.UFNode) pntAndNode.get(e.getStart());
UnionFind.UFNode y = (UnionFind.UFNode) pntAndNode.get(e.getEnd());
if (UnionFind.find(x) != UnionFind.find(y)) {//在不同的集中
UnionFind.union(x, y);//合并并返回true
return true;
}
return false;
} }
最关键的地方在于“连通分量的查询和合并”,需要知道任意两个点是否在同一连通分量中,还需要合并两个连通分量。这个问题正好可以用并查集完美的解决
并查集(Union-Find set)这个数据结构可以方便快速的解决这个问题。基本的处理思想是:初始时把每个对象看作是一个单元素集合;然后依次按顺序读入联通边,将连通边中的两个元素合并。在此过程中将重复使用一个搜索(Find)运算,确定一个集合在那个集合中。当读入一个连通边(u,v)时,先判断u和v是否在同一个集合中,如果是则不用合并;如果不是,则用一个合并(Union)运算把u、v所在集合合并,使得这两个集合中的任意两个元素都连通。因此并查集在处理时,主要用到搜索和合并两个运算。
为了方便并查集的描述与实现,通常把先后加入到一个集合中的元素表示成一个树结构,并用根结点的序号来表示这个集合。因此定义一个parent[n]的数组,parent[i]中存放的就是结点i所在的树中结点i的父亲节点的序号。例如,如果parent[4]=5,就是说4号结点的父亲结点是5号结点。约定:如果i的父结点(即parent[i])是负数,则表示结点i就是它所在的集合的根结点,因为集合中没有结点的序号是负的;并且用负数的绝对值作为这个集合中所含结点的个数。例如,如果parent[7]=-4,说明7号结点就是它所在集合的根结点,这个集合有四个元素。初始时结点的parent值为-1(每个结点都是根结点,只包含它自己一个元素)。
实现并查集数据结构主要有2个函数。
import java.util.HashSet;
import java.util.Set; public class UnionFind { public static UFNode find(UFNode x) {
UFNode p = x;
Set<UFNode> path = new HashSet<UFNode>();
// 记录向上追溯的路径上的点
while (p.parent != null) {
path.add(p);
p = p.parent;
}
// 这些点的parent全部指向这个集的代表
for (UFNode ppp : path) {
ppp.parent = p;
}
// root
return p; } public static void union(UFNode x, UFNode y) {
find(y).parent = find(x);
} public static class UFNode {
UFNode parent;
}
}
最后贴出边集的代码
/**
* 边 的封装
* 边集可以用来表示图
*/
public class Edge<T> implements Comparable<Edge> {
private T start;
private T end;
private int distance; public Edge(T start, T end, int distance) {
this.start = start;
this.end = end;
this.distance = distance;
} public T getStart() {
return start;
} public void setStart(T start) {
this.start = start;
} public T getEnd() {
return end;
} public void setEnd(T end) {
this.end = end;
} public int getDistance() {
return distance;
} public void setDistance(int distance) {
this.distance = distance;
} @Override
public String toString() {
return start + "->" + end + ":" + distance;
} @Override
public int compareTo(Edge obj) {
int targetDis = obj.getDistance();
return distance > targetDis ? 1 : (distance == targetDis ? 0 : -1);
}
}
最后运行Kruskal类的结果为:
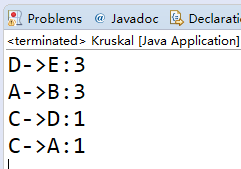
例题:POJ- 1287,蓝桥杯-城市建设。
最小生成树之Kruskal(克鲁斯卡尔)算法的更多相关文章
- 经典问题----最小生成树(kruskal克鲁斯卡尔贪心算法)
题目简述:假如有一个无向连通图,有n个顶点,有许多(带有权值即长度)边,让你用在其中选n-1条边把这n个顶点连起来,不漏掉任何一个点,然后这n-1条边的权值总和最小,就是最小生成树了,注意,不可绕成圈 ...
- 最小生成树——Kruscal(克鲁斯卡尔算法)
一.核心思想 将输入的数据由小到大进行排序,再使用并查集算法(传送门)将每个点连接起来,同时求和. 个人认为这个算法比较偏向暴力,有些题可能会超时. 二.例题 洛谷-P3366 题目地址:ht ...
- 贪心算法(Greedy Algorithm)之最小生成树 克鲁斯卡尔算法(Kruskal's algorithm)
克鲁斯卡尔算法(Kruskal's algorithm)是两个经典的最小生成树算法的较为简单理解的一个.这里面充分体现了贪心算法的精髓.大致的流程能够用一个图来表示.这里的图的选择借用了Wikiped ...
- 贪心算法(Greedy Algorithm)最小生成树 克鲁斯卡尔算法(Kruskal's algorithm)
克鲁斯卡尔算法(Kruskal's algorithm)它既是古典最低的一个简单的了解生成树算法. 这充分反映了这一点贪心算法的精髓.该方法可以通常的图被表示.图选择这里借用Wikipedia在.非常 ...
- 最小生成树---普里姆算法(Prim算法)和克鲁斯卡尔算法(Kruskal算法)
普里姆算法(Prim算法) #include<bits/stdc++.h> using namespace std; #define MAXVEX 100 #define INF 6553 ...
- 最小生成树--克鲁斯卡尔算法(Kruskal)
按照惯例,接下来是本篇目录: $1 什么是最小生成树? $2 什么是克鲁斯卡尔算法? $3 克鲁斯卡尔算法的例题 摘要:本片讲的是最小生成树中的玄学算法--克鲁斯卡尔算法,然后就没有然后了. $1 什 ...
- 最小生成树-克鲁斯卡尔算法(kruskal's algorithm)实现
算法描述 克鲁斯卡尔算法是一种贪心算法,因为它每一步都挑选当前最轻的边而并不知道全局路径的情况. 算法最关键的一个步骤是要判断要加入mst的顶点是否会形成回路,我们可以利用并查集的技术来做. 并查集的 ...
- prim算法,克鲁斯卡尔算法---最小生成树
最小生成树的一个作用,就是求最小花费.要在n个城市之间铺设光缆,主要目标是要使这 n 个城市的任意两个之间都可以通信,但铺设光缆的费用很高,且各个城市之间铺设光缆的费用不同,因此另一个目标是要使铺设光 ...
- 图->连通性->最小生成树(克鲁斯卡尔算法)
文字描述 上一篇博客介绍了最小生成树(普里姆算法),知道了普里姆算法求最小生成树的时间复杂度为n^2, 就是说复杂度与顶点数无关,而与弧的数量没有关系: 而用克鲁斯卡尔(Kruskal)算法求最小生成 ...
随机推荐
- 关于ArrayList的5道面试题
我以面试官的身份参加过很多Java的面试,以下是五个比较有技巧的问题,我发现有些初级到中级的Java研发人员在这些问题上没有完全弄明白,似懂非懂.所以我写了一篇相关的文章,帮助初级Java研发人员弄清 ...
- name属性作用+使用$.post()取代name属性在提交表单信息中的作用
name的用途 1)主要是用于获取提交表单的某表单域信息, 作为可与服务器交互数据的HTML元素的服务器端的标示,比如input.select.textarea.框架元素(iframe.frame. ...
- session会话管理
session会话和cookie一起被称为会话跟踪技术,主要通过保存在服务器端的session数据和客户端浏览器的cookie数据共同完成用户访问服务器的足迹记录. 1. 什么是会话 会话sessio ...
- 关于top命令的使用
在服务器运维过程中,我们有时需要知道当前状态下的系统运行性能,该如何获取呢?今天,咱们聊一下关于top这个小命令的一些知识. top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资 ...
- Java并发编程(五)锁的使用(下)
显式锁 上篇讲了使用synchronized关键字来定义锁,其实Java除了使用这个关键字外还可以使用Lock接口及其实现的子类来定义锁,ReentrantLock类是Lock接口的一个实现,Reen ...
- BZOJ_1407_[Noi2002]Savage_EXGCD
BZOJ_1407_[Noi2002]Savage_EXGCD Description Input 第1行为一个整数N(1<=N<=15),即野人的数目. 第2行到第N+1每行为三个整数C ...
- Windows上安装配置SSH教程(1)——知识点汇总
1.是什么SSH? 维基百科:https://zh.wikipedia.org/wiki/Secure_Shell 其他博客:http://www.ruanyifeng.com/blog/2011/1 ...
- 前端随笔 - JavaScript中的闭包
前阵子重新复习了一下js基础知识,第一篇博客就以分享闭包心得为开始吧. 首先,要理解闭包,就必须要了解一个概念:作用域链. 作用域链 作用域代表着可访问变量的集合,变量分为全局变量和局部变量两种,在函 ...
- MIP 与 AMP 合作进展(3月7日)
"到目前为止,全网通过 MIP 校验的网页已超10亿.除了代码和缓存, MIP 还想做更多来改善用户体验移动页面." 3月7日,MIP 项目负责人在首次 AMP CONF 上发言. ...
- 为自己搭建一个分布式 IM 系统二【从查找算法聊起】
前言 最近这段时间确实有点忙,这篇的目录还是在飞机上敲出来了的. 言归正传,上周更新了 cim 第一版:没想到反响热烈,最高时上了 GitHub Trending Java 版块的首位,一天收到了 3 ...