Storm入门(二)集群环境安装
1.集群规划
storm版本的变更:
storm0.9.x storm0.10.x storm1.x
上面这些版本里面storm的核心源码是由Java+clojule组成的。
storm2.x
后期这个版本就是全部用java重写了。
(阿里在很早的时候就对storm进行了重写,提供了jstorm,后期jstorm也加入到apache storm,负责使用java对storm进行重写,这就是storm2.x版本的由来。)
注意:
在storm0.10.x的版本中,storm集群只支持一个nimbus节点,主节点是存在单点问题。
在storm1.x以后,storm集群可以支持多个nimbus节点,其中有一个为leader,负责真正运行,其余的为offline。
1.1服务器
3台Centos6.8服务器,各服务器需要启动的服务如下。
192.168.137.180 storm-cluster-64bit-1 内存1G
Nimbus:负责分发代码,监控代码的执行。
UI:可以查看集群的信息以及topology的运行情况。
logviewer:因为主节点会有多个,有时候也需要查看主节点的日志信息。
Zookeeper
192.168.137.181 storm-cluster-64bit-2 内存1G
Nimbus:负责分发代码,监控代码的执行。
Supervisor:负责产生worker进程,执行任务。
logviewer:可以通过webui界面查看topology的运行日志。
Zookeeper
192.168.137.182 storm-cluster-64bit-3 内存1G
Supervisor:负责产生worker进程,执行任务。
logviewer:可以通过webui界面查看topology的运行日志。
Zookeeper
1.2安装包
zookeeper-3.4.5.tar.gz
apache-storm-1.1.0.tar.gz
2.搭建Zookeeper集群

3台服务器同时执行以下操作。
(1)解压和重命名
tar -zxvf zookeeper-3.4.5.tar.gz
mv zookeeper-3.4.5 /usr/local/zookeeper
(2)修改环境变量
vi /etc/profile export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=.:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH source /etc/profile
(3)到zookeeper下修改配置文件
cd /usr/local/zookeeper/conf
mv zoo_sample.cfg zoo.cfg 修改conf: vi zoo.cfg 修改两处 dataDir=/usr/local/zookeeper/data
最后面添加
server.0=192.168.137.180:2888:3888
server.1=192.168.137.181:2888:3888
server.2=192.168.137.182:2888:3888
(4)创建服务器标识配置文件
cd /usr/local/zookeeper/
创建文件夹:mkdir data
cd data
创建文件myid并填写内容为0:vi myid (内容为服务器标识 : 0)
其他两个服务器的值修改为1和2
(5)启动zookeeper
执行:zkServer.sh start (注意这里3台机器都要进行启动)
状态:zkServer.sh status(在三个节点上检验zk的mode,一个leader和俩个follower)
停止:zkServer.sh stop
启动验证:输入jps,存在 QuorumPeerMain 进程的话,就说明 Zookeeper 启动成功了。
3.安装Storm依赖库
需要在Nimbus和Supervisor机器上安装Storm的依赖库Python2.6.6。
我的Centos6.8系统自带了Python2.6.6,所以省略安装。
4.解压安装Storm
(1)解压Storm(1台服务器执行)
tar -zxvf apache-storm-1.1.0.tar.gz
mv apache-storm-1.1.0 /usr/local/storm
(2)配置环境变量(3台服务器同时执行)
vi /etc/profile
export STORM_HOME=/usr/local/storm
export PATH=.:$STORM_HOME/bin:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH
source /etc/profile
(3)修改storm.yaml配置文件(1台服务器执行)
Storm发行版本解压目录下有一个conf/storm.yaml文件,用于配置Storm。
vim /usr/local/storm/conf/storm.yaml
1) storm.zookeeper.servers: Storm集群使用的Zookeeper集群地址,其格式如下:
storm.zookeeper.servers:
- "storm-cluster-64bit-1"
- "storm-cluster-64bit-2"
- "storm-cluster-64bit-3"
如果Zookeeper集群使用的不是默认端口,那么还需要storm.zookeeper.port选项。
2) storm.local.dir: Nimbus和Supervisor进程用于存储少量状态,如jars、confs等的本地磁盘目录,需要提前创建该目录并给以足够的访问权限。然后在storm.yaml中配置该目录,
如:mkdir -p /usr/local/storm/data
storm.local.dir: "/usr/local/storm/data"
3) nimbus.seeds: Storm集群Nimbus机器地址,各个Supervisor工作节点需要知道哪个机器是Nimbus,以便下载Topologies的jars、confs等文件,如:
nimbus.seeds: ["storm-cluster-64bit-1","storm-cluster-64bit-2"]
注意:nimbus.seeds指定的时候最好指定主机名,否则在webui界面查询的时候会重复显示节点信息。
4) supervisor.slots.ports: 对于每个Supervisor工作节点,需要配置该工作节点可以运行的worker数量。每个worker占用一个单独的端口用于接收消息,该配置选项即用于定义哪些端口是可被worker使用的。默认情况下,每个节点上可运行4个workers,分别在6700、6701、6702和6703端口,如:
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
【注意:yaml文件的格式,属性必须顶格,缩进只能使用空格,一点不能使用制表符。】
5)把修改后的storm目录拷贝到其他所有主从节点【主从节点配置完全一样】
scp -rq /usr/local/storm 192.168.137.181:/usr/local
scp -rq /usr/local/storm 192.168.137.182:/usr/local
6)修改/etc/hosts文件
加上下面的设置。
192.168.137.180 storm-cluster-64bit-1
192.168.137.181 storm-cluster-64bit-2
192.168.137.182 storm-cluster-64bit-3
(4)启动storm各个服务进程
最后一步,启动Storm的所有后台进程。和Zookeeper一样,Storm也是快速失败(fail-fast)的系统,这样Storm才能在任意时刻被停止,并且当进程重启后被正确地恢复执行。这也是为什么Storm不在进程内保存状态的原因,即使Nimbus或Supervisors被重启,运行中的Topologies不会受到影响。
192.168.137.180
nimbus:setsid storm nimbus &
ui:setsid storm ui &
logviewer:setsid storm logviewer &
192.168.137.181
nimbus:setsid storm nimbus
logviewer:setsid storm logviewer &
supervisor:setsid storm supervisor &
192.168.137.182
logviewer:setsid storm logviewer &
supervisor:setsid storm supervisor &
需要到/usr/local/storm/logs目录下查看各个进程是否成功启动。也可以jps查看。
(5)访问storm的ui界面来查看集群信息
注意:如果8080端口被占用,可以修改storm.yaml文件。最完整的属性配置在storm-core.jar中的defaults.yaml文件中。
ui.port: 8081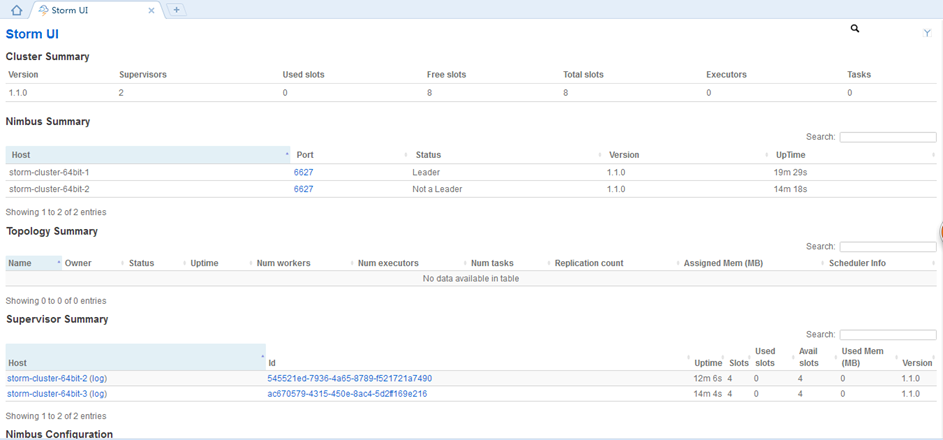
需要在本地windows配置hosts文件,不然无法查询logs。
C:\Windows\System32\drivers\etc\hosts
192.168.137.180 storm-cluster-64bit-1
192.168.137.181 storm-cluster-64bit-2
192.168.137.182 storm-cluster-64bit-3
至此,Storm集群已经部署、配置完毕,可以向集群提交拓扑运行了。
Storm入门(二)集群环境安装的更多相关文章
- Ubuntu 下 Neo4j单机安装和集群环境安装
1. Neo4j简介 Neo4j是一个用Java实现的.高性能的.NoSQL图形数据库.Neo4j 使用图(graph)相关的概念来描述数据模型,通过图中的节点和节点的关系来建模.Neo4j完全兼容A ...
- zookeeper集群环境安装配置
众所周知,Zookeeper有三种不同的运行环境,包括:单机环境.集群环境和集群伪分布式环境 在此介绍的是集群环境的安装配置 一.下载: http://apache.fayea.com/zookeep ...
- Hadoop集群环境安装
转载请标明出处: http://blog.csdn.net/zwto1/article/details/45647643: 本文出自:[zhang_way的博客专栏] 工具: 虚拟机virtual ...
- 大数据集群环境 zookeeper集群环境安装
大数据集群环境 zookeeper集群环境准备 zookeeper集群安装脚本,如果安装需要保持zookeeper保持相同目录,并且有可执行权限,需要准备如下 编写脚本: vi zkInstall.s ...
- 入门-k8s集群环境搭建(二)
对于 Kubernetes 初学者,在搭建K8S集群时,推荐在阿里云或腾讯云采购如下配置:(您也可以使用自己的虚拟机.私有云等您最容易获得的 Linux 环境) 至少2台 2核4G 的服务器 Cent ...
- Storm系列(一)集群的安装配置
安装前说明: 必须先安装zookeeper集群 该Storm集群由三台机器构成,主机名分别为chenx01,chenx02,chenx03,对应的IP分别为192.168.1.110,192.168. ...
- Percona XtraDB Cluster(PXC) -集群环境安装
Percona XtraDB Cluster(PXC) ---服务安装篇 1.测试环境搭建: Ip 角色 OS PXC-version 172.16.40.201 Node1 Redhat/C ...
- 大数据高可用集群环境安装与配置(09)——安装Spark高可用集群
1. 获取spark下载链接 登录官网:http://spark.apache.org/downloads.html 选择要下载的版本 2. 执行命令下载并安装 cd /usr/local/src/ ...
- 大数据高可用集群环境安装与配置(07)——安装HBase高可用集群
1. 下载安装包 登录官网获取HBase安装包下载地址 https://hbase.apache.org/downloads.html 2. 执行命令下载并安装 cd /usr/local/src/ ...
随机推荐
- UML第二次作业
一.plant UML语法学习小结 1.类之间的关系 使用.. 来代替 -- 可以得到点 线. 在这些规则下,也可以绘制下列图形 @startumlClass01 <|-- Class02 Cl ...
- 4.29 初始mysql
- 如何在eclipse中快速debug到想要的参数条件场景下
前言 俗话说,工欲善其事必先利其器. 对于我们经常使用的开发工具多一些了解,这也是对我们自己工作效率的一种提升. 场景 作为开发,我们经常会遇到各种bug,大部分的bug很明确,我们直接可以打断点定位 ...
- JVM 学习(一)反射、垃圾回收、异常处理--- 2019年4月
1.JVM 基础知识点 JVM 虚拟机包含了:自动内存管理器.垃圾回收(垃圾回收调优). 执行顺序:Java 代码 --- .class 字节码文件(加载到虚拟机中) --- Java 类放在方法区中 ...
- React教程(一) React介绍与搭建
React的介绍: React来自于Facebook公司的开源项目 React 可以开发单页面应用 spa(单页面应用) react 组件化模块化 开发模式 React通过对DOM的模拟(虚拟dom) ...
- 在Linux系统配置Nodejs环境的最简单步骤,部署多个thinkjs(nodejs)项目
发现一台服务器部署管理多个nodejs服务,可以采用二级域名weekly.mwcxs.top,也可以采用固定后缀www.mwcxs.top/weekly的方式,本文先从固定后缀的方式部署管理多个nod ...
- .NET Core开发者的福音之玩转Redis的又一傻瓜式神器推荐
作者:依乐祝 原本链接:https://www.cnblogs.com/yilezhu/p/9947905.html 引子 为什么写这篇文章呢?因为.NET Core的生态越来越好了!之前玩转.net ...
- 1.6部署到CentOS「深入浅出ASP.NET Core系列」
希望给你3-5分钟的碎片化学习,可能是坐地铁.等公交,积少成多,水滴石穿,谢谢关注. 安装.NET Core 官方安装地址: https://www.microsoft.com/net/learn/d ...
- vs2017和vs2019专业版和企业版
步骤:打开vs2017,依次点击--->帮助----->注册产品 专业版: Professional: KBJFW-NXHK6-W4WJM-CRMQB-G3CDH 企业版: Enterpr ...
- asp.net mvc前台显示带htm标签的解决办法(Razor —@Html.Raw())
数据是从后台富文本编辑后丢在数据库后取出的,不加Html.Raw(),前台就会把Html标签一同显示