几幅手稿讲解CNN
学习深度神经网络方面的算法已经有一段时间了,对目前比较经典的模型也有了一些了解。这种曾经一度低迷的方法现在已经吸引了很多领域的目光,在几年前仅仅存在于研究者想象中的应用,近几年也相继被深度学习方法实现了。无论是对数据的分析或是生成,无论数据形式是图像、视频、音频、文本还是其它复杂维度,也无论是下棋、玩游戏还是无人驾驶汽车导航,似乎总有人会发掘出这种强大工具的新用途。人类刚刚将仿生学运用到“如何创造智能”这个问题上,就发现了光明的前景。
我把在组里介绍深度学习(Deep Learning)基础知识时画的几幅手稿分享出来,希望能帮助新人更快的了解这种方法。我在讲解的过程中参考了李宏毅老师的PPT(网络上他的PPT也有不止一个版本,YouTube也有视频教程),推荐读者结合起来阅读。
 任何一个算法都可以看作一个函数。输入
任何一个算法都可以看作一个函数。输入
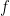
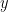
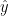
同时,函数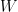
对于分类问题,函数
 在神经网络算法中,最基本的组成单位如图中左上所示,前一层神经元
在神经网络算法中,最基本的组成单位如图中左上所示,前一层神经元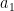
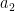
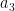
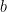
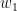
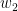
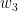

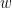

 卷积神经网络当中的“卷积”(convolution)与图像处理中的滤波器(filter)十分相似,只不过在滤波器中求和时输入元素与窗口元素是同向的,而在卷积计算中输入元素与窗口元素是反向的(注意公式中
卷积神经网络当中的“卷积”(convolution)与图像处理中的滤波器(filter)十分相似,只不过在滤波器中求和时输入元素与窗口元素是同向的,而在卷积计算中输入元素与窗口元素是反向的(注意公式中
在特征提取方面,卷积运算的作用与滤波器相同。如图中下方所示,假设在数轴上的输入数据是经过{2,-1,1}的一条曲线,与一个{1,-2,1}的核进行滤波(或者经过水平翻转后进行卷积),会得到一个比较大的输出(5),经过激活函数(actiation function)会产生一个十分接近于1的激活输出。这时,我们可以说输入
 计算机科学中的神经网络算法只是从仿生学上部分借鉴了人类大脑的结构。上面的截图来自CrashCourse的科普视频。在大脑的神经元(Neuron)中,输入信号经过树突(dendrite)传入,然后再从轴突(Axon)传递出去。在神经元内部,信息以电信号方式传递,在神经元之间则以化学信号传递。在传递的过程中,信号的强度和速度是一定的,但频率是可变的。所以信号的强弱(比如痛感、情绪等)是以信号频率的高低来区分的。另外神经元之间的连接是多对多的,即一个神经元可以有多个输入和输出。
计算机科学中的神经网络算法只是从仿生学上部分借鉴了人类大脑的结构。上面的截图来自CrashCourse的科普视频。在大脑的神经元(Neuron)中,输入信号经过树突(dendrite)传入,然后再从轴突(Axon)传递出去。在神经元内部,信息以电信号方式传递,在神经元之间则以化学信号传递。在传递的过程中,信号的强度和速度是一定的,但频率是可变的。所以信号的强弱(比如痛感、情绪等)是以信号频率的高低来区分的。另外神经元之间的连接是多对多的,即一个神经元可以有多个输入和输出。
与之相比,神经网络算法一般没有信号频率的概念,即每个节点只向外产生一次激活(RNN递归计算的节点可以看作展开成一条节点链,但是链上每个节点依然只经过一次计算)。而且,目前的算法大多是严格按层级进行计算,并不像生物体神经元那样在三维空间中呈现纷繁复杂的结构。
 在神经网络中,层与层之间的连接分为全连通(fully-connected)与局部连通(local connected)两种。一些比较古老的文献认为局部连通的计算形式可以用卷积的形式来表示,所以错误地把这种经过简化计算的局部连通网络称为卷积网络。局部连通与全连通相比,参数数量要少得多,所以在过去计算机性能不佳时是一个比较有效的性能优化有段。但与此同时,局部连通也不可避免地引入了只有相邻节点(
在神经网络中,层与层之间的连接分为全连通(fully-connected)与局部连通(local connected)两种。一些比较古老的文献认为局部连通的计算形式可以用卷积的形式来表示,所以错误地把这种经过简化计算的局部连通网络称为卷积网络。局部连通与全连通相比,参数数量要少得多,所以在过去计算机性能不佳时是一个比较有效的性能优化有段。但与此同时,局部连通也不可避免地引入了只有相邻节点(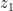

对于一个机器学习算法来说(也可以推广到其他领域的算法),最关键的三点是模型、数据和误差函数。模型即确定输入、参数与输出之间的关系;数据即我设计的模型是针对什么样的数据,期望得到什么样的输出;误差函数是评价一个算法好坏的关键,需要用明确的表达式合理地衡量实际输出与理想输出之间的差异。前文说过,寻找一个最优函数
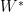
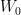
对于一个可微函数(误差函数),其上任意一点处的偏导大小代表该点处切线斜率大小,方向(正负号)代表这条切线是向上还是向下的。因为我们需要在变量
网络上有很多关于梯度下降法的介绍,这里不再赘述。推荐阅读An overview of gradient descent optimization algorithms来了解一些常用的梯度方法。
 这张图来自李宏毅老师的PPT,是为了说明可能会造成训练收敛缓慢的原因。在函数平缓的区域,由于偏导本身数值很小,会导致参数的更新量也很小,这时就需要比较大的步长。在鞍点时,某一轴上是极小点,但在其他轴上并不是极小点,但由于误差函数形式的原因(比如涉及到对误差取偶数次幂),会表现为在鞍点周围误差都大于鞍点,所以使得训练过程误“收敛”于鞍点。由于大量的局部极小点和鞍点的存在,深度神经网络训练的调参也是一个十分精细的工作。关于在鞍点方面的分析,请参考Identifying and attacking the saddle point problem in high-dimensional non-convex optimization。
这张图来自李宏毅老师的PPT,是为了说明可能会造成训练收敛缓慢的原因。在函数平缓的区域,由于偏导本身数值很小,会导致参数的更新量也很小,这时就需要比较大的步长。在鞍点时,某一轴上是极小点,但在其他轴上并不是极小点,但由于误差函数形式的原因(比如涉及到对误差取偶数次幂),会表现为在鞍点周围误差都大于鞍点,所以使得训练过程误“收敛”于鞍点。由于大量的局部极小点和鞍点的存在,深度神经网络训练的调参也是一个十分精细的工作。关于在鞍点方面的分析,请参考Identifying and attacking the saddle point problem in high-dimensional non-convex optimization。
 深度神经网络一般用反向传播训练方法(Back Propagation)来迭代地更新参数。上图是以线性网络为例解释BP的计算过程,公式应该可以自明,我就不用文字赘述了。对于卷积网络,其实计算过程是相同的,只不过把偏导项之间的乘法替换为卷积(卷积核在水平和竖直翻转之后的卷积)。推荐阅读Backpropagation in Convolutional Neural Network了解CNN中BP算法的细节。
深度神经网络一般用反向传播训练方法(Back Propagation)来迭代地更新参数。上图是以线性网络为例解释BP的计算过程,公式应该可以自明,我就不用文字赘述了。对于卷积网络,其实计算过程是相同的,只不过把偏导项之间的乘法替换为卷积(卷积核在水平和竖直翻转之后的卷积)。推荐阅读Backpropagation in Convolutional Neural Network了解CNN中BP算法的细节。
 当训练结果不好时,可能会有两种结果,欠拟合与过拟合。欠拟合是指模型不足以对训练集产生比较高的分类精度,从误差-迭代曲线上表现为无论是训练期间还是测试期间,误差都比较高。这说明模型对特征的提取不够,不足以用来描述样本间的差异。这时一般需要优化方法来解决这个问题,比如改变激活函数、误差函数,或者换一种梯度下降方法(以及调整梯度方法的参数)。过拟合是指模型对训练集有比较高的分类精度,但对测试集表现不佳,从误差-迭代曲线上表现为在训练期间误差能够收敛到一个较小值,但测试期间误差却比较大。这说明模型过分地依赖训练样本的特征,对没有遇见过新样本不知所措,缺乏泛化能力。这时需要正则化方法来提高模型对一般性样本的适应性,比如Dropout和Batch Normalization。
当训练结果不好时,可能会有两种结果,欠拟合与过拟合。欠拟合是指模型不足以对训练集产生比较高的分类精度,从误差-迭代曲线上表现为无论是训练期间还是测试期间,误差都比较高。这说明模型对特征的提取不够,不足以用来描述样本间的差异。这时一般需要优化方法来解决这个问题,比如改变激活函数、误差函数,或者换一种梯度下降方法(以及调整梯度方法的参数)。过拟合是指模型对训练集有比较高的分类精度,但对测试集表现不佳,从误差-迭代曲线上表现为在训练期间误差能够收敛到一个较小值,但测试期间误差却比较大。这说明模型过分地依赖训练样本的特征,对没有遇见过新样本不知所措,缺乏泛化能力。这时需要正则化方法来提高模型对一般性样本的适应性,比如Dropout和Batch Normalization。
误差不收敛的一个更常见的原因——尤其是在一个新模型刚刚建立时——是梯度消失或梯度爆炸。在网络中缺少比较可靠的正则化技术时,在网络不断迭代训练的过程中(甚至第二次迭代开始)会发现新样本产生的误差梯度在反向传播的过程中越来越小(或越来越大),有时呈现每一两层就减小(或增大)一个数量级。梯度趋向消失时,无论训练多久,会发现最浅层(前一两层)的参数与初始值并没有太大变化,这就使得浅层的存在失去了意义,而且这也会使训练过程变得非常缓慢。梯度爆炸时,仅仅几次迭代之后就会发现某一层所有节点的输出都变成了1(或者十分接近于1),这时网络也就失去了分类的能力。
 既然已经知道网络的输入和参数会影响最终输出的误差,那么也就可以假设我们可以在一个三维坐标上画出三者的关系。如图中所示,当参数(parameter)固定时,每输入不同的样本(sample),就会产生不同的误差(loss),因为真实样本
既然已经知道网络的输入和参数会影响最终输出的误差,那么也就可以假设我们可以在一个三维坐标上画出三者的关系。如图中所示,当参数(parameter)固定时,每输入不同的样本(sample),就会产生不同的误差(loss),因为真实样本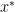
在训练模型时,一般会将训练集等分为若干小集合(mini-batch),一次将一个mini-batch输入网络,计算完所有mini-batch后——如果觉得网络精度还达不到要求——将所有样本随机排序,再分割为若干mini-batch进行训练。这个过程可以看作在sample轴上随机跳跃,在parameter轴上逐步前进地搜索,能够尽可能地保证搜索到的最低点是所有样本的最低点。
 特征提取是一个分类器的核心,深度学习的优势就在于它能自动从原始数据提炼出特征,并以层级的逻辑组合这些特征来描述原始样本。我在最后一幅图中用一个简单的例子来说明CNN的层级结构是如何解决图像分类问题的。
特征提取是一个分类器的核心,深度学习的优势就在于它能自动从原始数据提炼出特征,并以层级的逻辑组合这些特征来描述原始样本。我在最后一幅图中用一个简单的例子来说明CNN的层级结构是如何解决图像分类问题的。
假设我们需要用机器视觉方法对图A(两个三角形构成松树的形状)和图B(两个三角形构成钻石的形状)进行区分。在神经网络方法出现之前,一种比较可行的方法是通过图像处理中的直线检测方法找到图像中所有直线,然后通过直线参数之间的关系来确定如下判断规则:如果下面的三角形尖角朝上,即为松树;如果尖角朝下,即为钻石。经过细致的调参,这个算法应该已经可以完美解决区分图A与图B的问题了。如果现在又来了一副图C(也许是两个三角形水平排列构成小山的形状,也可能根本不包含三角形),需要用之前的算法来同时区分这三幅图片,怎么办?
好在我们可以用CNN来解决这个问题。首先需要注意,我在这一小节所指“卷积”实际上是滤波操作,因为卷积涉及翻转,不利用直观理解。假设我们训练好的网络有两层隐层,第一层包含两个节点(图中第二列蓝色图形,分别为一条左斜线与一条右斜线),第二层包含四个节点(图中第四列蓝色图形,分别为一条水平线,一条竖直线,一条左斜线与一条右斜线)。图A经过第一隐层,得到图中第三列黑色的图形。黑色的圆点代表原始图像中对某个卷积核激活值高的区域,白色代表激活值低的区域。图A松树左侧的两条斜边经过“左斜线”卷积核计算得到位于图像左侧的两个黑色圆点,其他区域都不符合“左斜线”这个特征,所以输出值全部忽略为0。同时,只有松树右侧的两条斜边会对“右斜线”卷积核产生高激活(得到两个位于右侧的黑色圆点),其他区域产生的激活都为0。同理,图B钻石图像经过“左斜线”与“右斜线”卷积核产生两幅不同的图像(一副在左上和右下有黑点,一副在右上和左下有黑点)。这时,第一层的计算就完成了。
与一般的CNN模型一样,我们把第一层的结果(图中第三列)输入第二隐层之前要缩小一下图像的尺度。经过缩小之后(你可以眯起眼睛离屏幕稍远些观察),第三列的四个图形分别变成了一条在左侧的竖线,一条在右侧的竖线,一条右斜线和一条左斜线。现在,我们拿第二层的四个卷积核(第四列蓝色图形)来对这四个结果进行卷积再求和。为了简化,如果在图像中存在一个区域使其与某卷积核的激活输出值较高,就将该卷积核的对应输出记为1;如果不存在这样的一个区域即记为0。这样,图中第三列第一个图像对四个卷积核分别产生
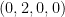

如果有新的样本加入,我们只需要改变一下图例中的卷积核数目和形状(或者甚至不对网络做任何修改)也能够轻松地实现分类。当然,CNN方法在实际运用时是不需要人为地设计卷积核的,而是依靠对样本的训练逐渐构造的。
其实,作为一个尚未成熟的工具,深度学习的优点与缺点同样明显。其优点毋庸置疑,是推动其在各领域蔓延的高分类精度,确切地说是它能够自主归纳特征,免去了过去慢慢手工筛选特征来提高精度的过程。深度学习方法的缺点也十分致命,即训练结果完全的不可预测性。在训练完成、进行测试之前,即便是有经验的工程师也难以给出其精度的界,更无法预知训练后的参数会变成什么样。虽然这种说法对于一个机器学习方法来说有些苛刻,毕竟在数值计算领域有很多迭代算法也会因为微小的参数变化而难以收敛。但是作为一个参数量级惊人的算法,人类对其参数含义的解读也是困难的。其在多个领域的广泛运用产生的一个结果是,参数的不可预测性会带来其行为的不可预测性。虽然技术的推广者经常会如何保证甚至如何吹嘘他们训练出来的模型在很多条件下都有很高的精度(或者说,执行设计者所期望的行为),但更有可能的是,吹牛的人并不知道模型究竟为什么会在特定条件下产生特定的结果。作为一个“黑盒”算法,其对外的表征是高分通过所有测试,但对于测试内容没有考虑到的情况才是值得担心的。一个廉价而高效的工具在市场上的阻力是比较小的,那么比市场上现有算法更复杂更强大的算法势必会被不断推出。如果我们能够假定“智能”只是一个不断收集和处理数据的过程,那么我们也可以说《终结者》所描述的世界也并纯粹的想象了。
原文来自:http://johnhany.net/2017/08/deep-learning-intro-hand-scripts-for-cnn/
几幅手稿讲解CNN的更多相关文章
- 【深度学习篇】---CNN和RNN结合与对比,实例讲解
一.前述 CNN和RNN几乎占据着深度学习的半壁江山,所以本文将着重讲解CNN+RNN的各种组合方式,以及CNN和RNN的对比. 二.CNN与RNN对比 1.CNN卷积神经网络与RNN递归神经网络直观 ...
- 使用Keras进行深度学习:(二)CNN讲解及实践
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 现今最主流的处理图像数据的技术当属深度神经网络了,尤其是卷积神经网 ...
- Kafka学习笔记(3)----Kafka的数据复制(Replica)与Failover
1. CAP理论 1.1 Cosistency(一致性) 通过某个节点的写操作结果对后面通过其他节点的读操作可见. 如果更新数据后,并发访问的情况下可立即感知该更新,称为强一致性 如果允许之后部分或全 ...
- Mybatis系列全解(八):Mybatis的9大动态SQL标签你知道几个?提前致女神!
封面:洛小汐 作者:潘潘 2021年,仰望天空,脚踏实地. 这算是春节后首篇 Mybatis 文了~ 跨了个年感觉写了有半个世纪 ... 借着女神节 ヾ(◍°∇°◍)ノ゙ 提前祝男神女神们越靓越富越嗨 ...
- 循环神经网络LSTM RNN回归:sin曲线预测
摘要:本篇文章将分享循环神经网络LSTM RNN如何实现回归预测. 本文分享自华为云社区<[Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测 丨[百变AI秀]& ...
- 论文翻译:2022_PACDNN: A phase-aware composite deep neural network for speech enhancement
论文地址:PACDNN:一种用于语音增强的相位感知复合深度神经网络 引用格式:Hasannezhad M,Yu H,Zhu W P,et al. PACDNN: A phase-aware compo ...
- cnn(卷积神经网络)比较系统的讲解
本文整理了网上几位大牛的博客,详细地讲解了CNN的基础结构与核心思想,欢迎交流. [1]Deep learning简介 [2]Deep Learning训练过程 [3]Deep Learning模型之 ...
- 机器不学习:CNN入门讲解-为什么要有最后一层全连接
哈哈哈,又到了讲段子的时间 准备好了吗? 今天要说的是CNN最后一层了,CNN入门就要讲完啦..... 先来一段官方的语言介绍全连接层(Fully Connected Layer) 全连接层常简称为 ...
- CNN入门讲解-为什么要有最后一层全连接?
原文地址:https://baijiahao.baidu.com/s?id=1590121601889191549&wfr=spider&for=pc 今天要说的是CNN最后一层了,C ...
随机推荐
- synchronized关键字的作用域
转自:http://www.cnblogs.com/devinzhang/archive/2011/12/14/2287675.html 1.synchronized关键字的作用域有二种: 1)是某个 ...
- git branch简单使用
1,branch的建立及使用git clone user@192.168.0.136:/media/projiect/omap4/nexttab/kernel kernel/android3.0/ ...
- VS连接SQL Server数据库,增删改查详细教程(C#代码)_转载
工具: 1.Visual Studio (我使用的是vs2013) 2.SQL Server (我使用的是sql server2008) 操作: 1.打开SQL Server,打开后会看到数据库的初 ...
- elementary os变成mac风(笔记)
sudo add-apt-repository ppa:philip.scott/elementary-tweaks && sudo apt-get update sudo apt-g ...
- java 多线程学习笔记(一) -- 计算密集型任务
最近在看<Java虚拟机并发编程>,在此记录一些重要的东东. 线程数的确定:1. 获取系统可用的处理器核心数:int numOfCores = Runtime.getRuntime().a ...
- uva 1153 顾客是上帝(贪心)
uva 1153 顾客是上帝(贪心) 有n个工作,已知每个工作需要的时间q[i]和截止时间d[i](必须在此前完成),最多能完成多少个工作?工作只能串行完成,第一项任务开始的时间不早于时刻0. 这道题 ...
- Filter的使用及其生命周期介绍
一.Filter 1. Filter简介 > Filter翻译为中文是过滤器的意思. > Filter是JavaWeb的三大web组件之一:Servlet.Filter.Listener ...
- ByteBuffer flip描述
# 关于flip ByteBuffer 的filp函数, 将缓冲区的终止位置limit设置为当前位置, 缓冲区的游标position(当前位置)重设为0. 比如 我们有初始化一个ByteBuffer ...
- @Transactional之Spring事务深入理解
Spring支持两种事务方式: 编程式事务:使用的是TransactionTemplate(或者org.springframework.transaction.PlatformTransac ...
- Sequence( 分块+矩阵快速幂 )
题目链接 #include<bits/stdc++.h> using namespace std; #define e exp(1) #define pi acos(-1) #define ...