spark中的RDD以及DAG
今天,我们就先聊一下spark中的DAG以及RDD的相关的内容
1.DAG:有向无环图:有方向,无闭环,代表着数据的流向,这个DAG的边界则是Action方法的执行
2.如何将DAG切分stage,stage切分的依据:有宽依赖的时候要进行切分(shuffle的时候,
也就是数据有网络的传递的时候),则一个wordCount有两个stage,
一个是reduceByKey之前的,一个事reduceByKey之后的(图1),
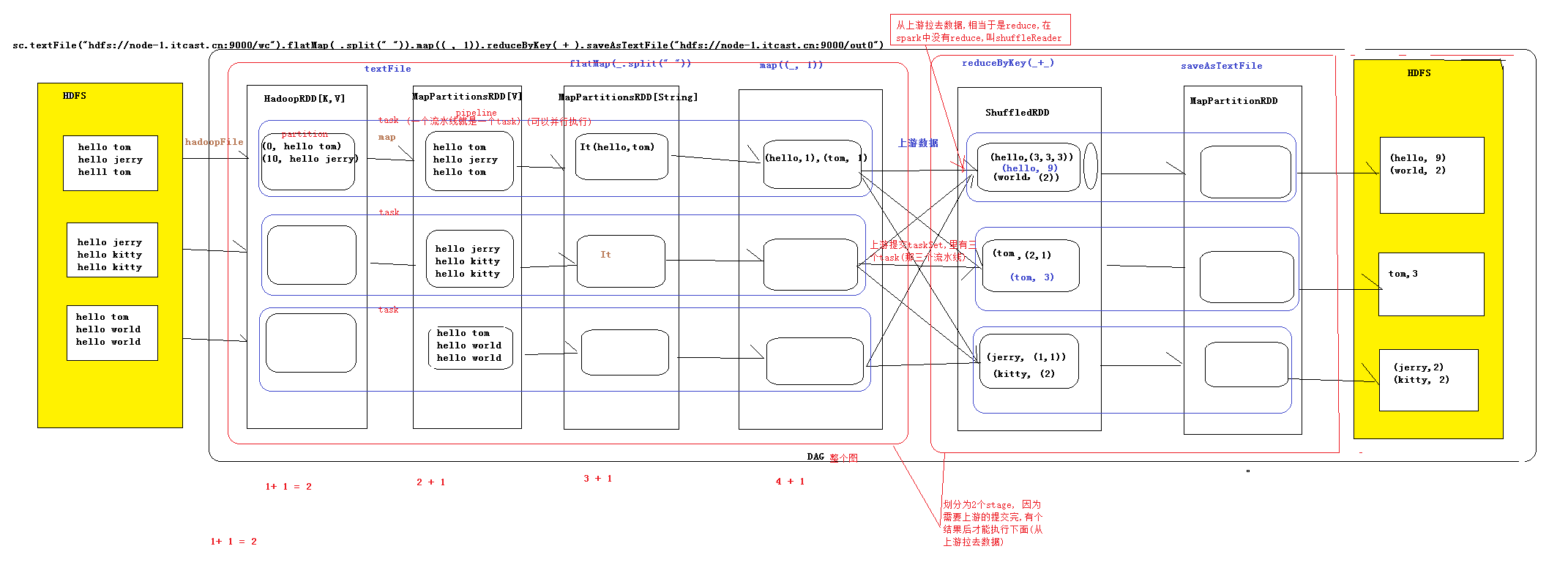
则我们可以这样的理解,当我们要进行提交上游的数据的时候,
此时我们可以认为提交的stage,但是严格意义上来讲,我们提交的是Task
sets(Task的集合),这些Task可能业务逻辑相同,就是处理的数据不同
3.流程
构建RDD形成DAG遇到Action的时候,前面的stage先提交,提交完成之后再交给
下游的数据,在遇到TaskScheduler,这个时候当我们遇到Action的方法的时候,我们
就会让Master决定让哪些Worker来执行这个调度,但是到了最后我们真正的传递的
时候,我们用的是Driver给Worker传递数据(其实是传递到Excutor里面,这个里面执行
真正的业务逻辑),Worker中的Excutor只要启动,则此后就和Master没有多大关系了
4.宽窄依赖
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)以及
宽依赖(wide dependency).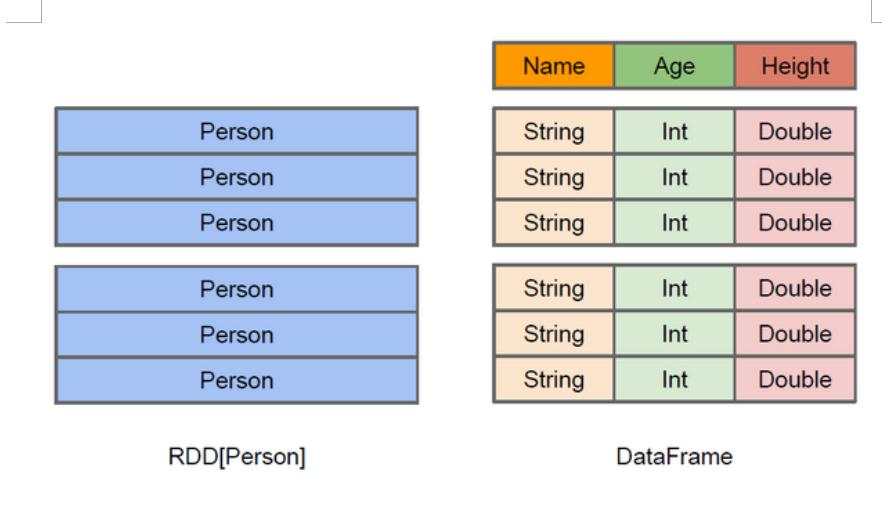

窄分区的划分依据,如果后面的一个RDD,前面的一个RDD有一个唯一对应的RDD,
则此时就是窄依赖,就相当于一次函数,y对应于一个x,而宽依赖则是类似于,前面的
一个RDD,则此时一个RDD对应多个RDD,就相当于二次函数,一个y对应多个x的值
5.DAG的生成
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成
DAG,根据RDD的之间的依赖关系的不同将DAG划分为不同的stage,对于窄依赖,
partition的转换处理在stage中完成计算,对于宽依赖,由于有shuffle的存在,只能在
partentRDD处理完成后,才能开始接下来的计算,因此宽依赖是划分stage的依据
一般我们认为join是宽依赖,但是对于已经分好区的join来说,我们此时可以认为这个
时候的join是窄依赖
spark中的RDD以及DAG的更多相关文章
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- Spark中的RDD和DataFrame
什么是DataFrame 在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格. RDD和DataFrame的区别 DataFrame与RDD的主要区别在 ...
- 浅谈大数据神器Spark中的RDD
1.究竟什么是RDD呢? 有人可能会回答是:Resilient Distributed Dataset.没错,的确是如此.但是我们问这个实际上是想知道RDD到底是个什么东西?以及它到底能干嘛?好的,有 ...
- Spark中的RDD操作简介
map(func) 对数据集中的元素逐一处理,变为新的元素,但一个输入元素只能有一个输出元素 scala> pairData.collect() res6: Array[Int] = Array ...
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark 核心概念RDD
文章正文 RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此, ...
- Spark学习之RDD编程总结
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称 RDD).RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外 ...
- Spark学习笔记——RDD编程
1.RDD——弹性分布式数据集(Resilient Distributed Dataset) RDD是一个分布式的元素集合,在Spark中,对数据的操作就是创建RDD.转换已有的RDD和调用RDD操作 ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
随机推荐
- jQuery 浮动导航菜单(购物网站商品类型)
单页面网页内容较多,页面长度较大,需要方便快速的在页面的不同位置进行定位,所以浮动菜单逐渐流行了起来,如下图 男装.女装.美妆等. 这种菜单功能分为两部分: 1.点击菜单项,网页滚动到对应位置,可简单 ...
- Mac 下显示隐藏文件或文件夹
Mac 操作系统 隐藏显示文件 显示:defaults write com.apple.finder AppleShowAllFiles -bool true 隐藏:defaults write co ...
- SharePoint 2010 技术参数(整理)
今天整理一些 SharePoint 2010 的技术参数,其内容都来自 SharePoint-Sandbox 网站. 有些参数值是硬性的,比如列表单条记录的尺寸:而有些是为了使用和性能考虑的推荐值. ...
- ES7的Async/Await的简单理解
Async/Await 的个人见解 正文: async,顾名思义,一个异步执行的功能,而 await 则是配合 async 使用的另一个关键字,也是闻字识其意,就是叫你等待啦! 二者配合食用效果更佳哦 ...
- Linux CentOS下部署Java Web项目
本文讲解如何在Linux CentOS下部署Java Web项目的步骤. 一.环境准备: (1)Linux CentOS (2)apache-tomcat-9.0.10 (3)XShell 二.启动t ...
- iBrand 教程:Git 软件安装过程截图
下载 教程中使用的相关软件下载网盘: https://pan.baidu.com/s/1bqVD5MJ 密码:4lku 安装 请右键 以管理员身份运行 进行软件安装,安装过程如下: 使用 安装完成后, ...
- IDEA中git的配置与使用
IDEA中git的配置与使用 1.介绍 git是目前非常流行的版本管理管理软件,因其具有分布式特点,越来越受到企业的欢迎.IDEA作为一款优秀的开发软件,其内部也提供了对git的支持. 2.下载并安装 ...
- UESTC 757 棋盘
虽然是水题,但是还是很interesting的.(大概就是我最晚出这个题了... 博弈感觉就是靠yy能力啊.这题是对称性. 最后的必败态是白色格子对称的,一旦对称形成,对手怎么选,跟随就好,对手无法摆 ...
- 预处理-04-#if defined和#if !defined
因为对于一个大程序而言,我们可能要定义很多常量( 不管是放在源文件还是头文件 ),那么我们有时考虑定义某个常量时,我们就必须返回检查原来此常量是否定义,但这样做很麻烦. if defined 宏正是为 ...
- MAC卸载/删除 Parallels Desktop虚拟机的方法
一些MAC用户在自己的电脑上安装了虚拟机之后,想要将它卸载,但是不知道该怎么做.今天小编就为大家带来了这个问题的解决方法. 解决方案(删除/卸载虚拟机 (VM): 1.启动Parallels Desk ...