spark中的RDD以及DAG
今天,我们就先聊一下spark中的DAG以及RDD的相关的内容
1.DAG:有向无环图:有方向,无闭环,代表着数据的流向,这个DAG的边界则是Action方法的执行
2.如何将DAG切分stage,stage切分的依据:有宽依赖的时候要进行切分(shuffle的时候,
也就是数据有网络的传递的时候),则一个wordCount有两个stage,
一个是reduceByKey之前的,一个事reduceByKey之后的(图1),
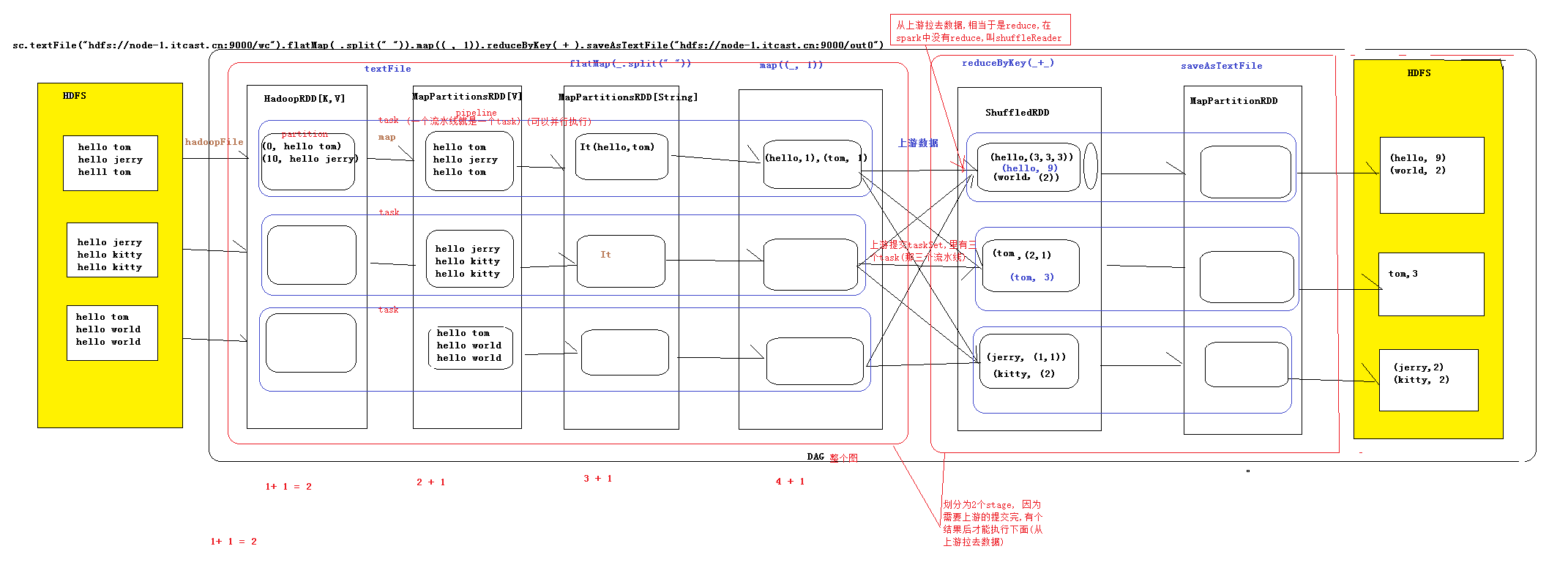
则我们可以这样的理解,当我们要进行提交上游的数据的时候,
此时我们可以认为提交的stage,但是严格意义上来讲,我们提交的是Task
sets(Task的集合),这些Task可能业务逻辑相同,就是处理的数据不同
3.流程
构建RDD形成DAG遇到Action的时候,前面的stage先提交,提交完成之后再交给
下游的数据,在遇到TaskScheduler,这个时候当我们遇到Action的方法的时候,我们
就会让Master决定让哪些Worker来执行这个调度,但是到了最后我们真正的传递的
时候,我们用的是Driver给Worker传递数据(其实是传递到Excutor里面,这个里面执行
真正的业务逻辑),Worker中的Excutor只要启动,则此后就和Master没有多大关系了
4.宽窄依赖
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)以及
宽依赖(wide dependency).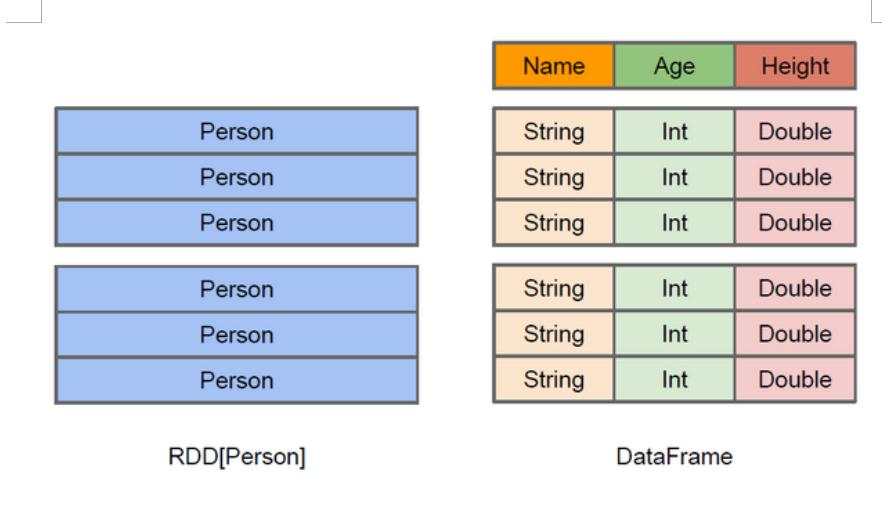

窄分区的划分依据,如果后面的一个RDD,前面的一个RDD有一个唯一对应的RDD,
则此时就是窄依赖,就相当于一次函数,y对应于一个x,而宽依赖则是类似于,前面的
一个RDD,则此时一个RDD对应多个RDD,就相当于二次函数,一个y对应多个x的值
5.DAG的生成
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成
DAG,根据RDD的之间的依赖关系的不同将DAG划分为不同的stage,对于窄依赖,
partition的转换处理在stage中完成计算,对于宽依赖,由于有shuffle的存在,只能在
partentRDD处理完成后,才能开始接下来的计算,因此宽依赖是划分stage的依据
一般我们认为join是宽依赖,但是对于已经分好区的join来说,我们此时可以认为这个
时候的join是窄依赖
spark中的RDD以及DAG的更多相关文章
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- Spark中的RDD和DataFrame
什么是DataFrame 在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格. RDD和DataFrame的区别 DataFrame与RDD的主要区别在 ...
- 浅谈大数据神器Spark中的RDD
1.究竟什么是RDD呢? 有人可能会回答是:Resilient Distributed Dataset.没错,的确是如此.但是我们问这个实际上是想知道RDD到底是个什么东西?以及它到底能干嘛?好的,有 ...
- Spark中的RDD操作简介
map(func) 对数据集中的元素逐一处理,变为新的元素,但一个输入元素只能有一个输出元素 scala> pairData.collect() res6: Array[Int] = Array ...
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark 核心概念RDD
文章正文 RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此, ...
- Spark学习之RDD编程总结
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称 RDD).RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外 ...
- Spark学习笔记——RDD编程
1.RDD——弹性分布式数据集(Resilient Distributed Dataset) RDD是一个分布式的元素集合,在Spark中,对数据的操作就是创建RDD.转换已有的RDD和调用RDD操作 ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
随机推荐
- Smile with face. Smile with mind.
Smile with face. Smile with mind.微笑不仅是挂在脸上的,更是发自心底的.
- sublime介绍常用插件和快捷键
简介 Sublime Text是由程序员Jon Skinner于2008年1月份所开发出来的,它最初被设计为一个具有丰富扩展功能的Vim. 是一个跨平台的编辑器,同时支持Windows.Linux.M ...
- Ubuntu18.04中使用中文输入法
如何在ubuntu18.04中设置使用中文输入法 ubuntu 在最新的版本中已经可以不用用户自己单独去下载中文输入法使用了,本次使用为 ubuntu18.04LTS版本(登陆是界面选择的是ubunt ...
- [转]用jwplayer+Nginx搭建视频点播服务器,解决拖动加载慢的问题
flv视频可以采用两种方式发布: 一.普通的HTTP下载方式 二.基于Flash Media Server或Red5服务器的rtmp/rtmpt流媒体方式. 多数知名视频网站都采用的是前一种方式. 两 ...
- python 爬poj.org的题目
主要是正则表达式不熟练,基础知识不扎实,函数也不怎么会用,下次再深入了解这3个函数吧. 主要是一个翻页的功能,其实,就是通过一个url替换一下数字,然后得到一个新的url,再找这个新的链接的信息. # ...
- css术语和概念
.vocabulary{ height:99px; color:transparent; } 属性 上面示意css代码中的height和color就是属性. 值 上面的99px就是值 整数值: ...
- libtool: Version mismatch error. 解决方法
在编译一个软件的时候,在 ./configure 和 make 之后可能会出现如下错误: libtool: Version mismatch error. This is libtool 2.4. ...
- Laravel5 构造器高级查询条件写法
<?php #DB 高级查询 // select * from table where A and B or C $all_data = DB::table("shopnc_goods ...
- Linux内存管理 —— 内核态和用户态的内存分配方式
1. 使用buddy系统管理ZONE我的这两篇文章buddy系统和slab分配器已经分析过buddy和slab的原理和源码,因此一些细节不再赘述.所有zone都是通过buddy系统管理的,buddy ...
- IIS配置MIME类型
有时候我们上传的视频,如果IIS上没有配置此格式是播放不了的.这个时候需要你在IIS上添加这个类型才能播放. MIME类型 ①打开你的IIS,点你的网站 ②双击 MIME类型 ③右键-->添加 ...