Hadoop学习笔记—8.Combiner与自定义Combiner
一、Combiner的出现背景
1.1 回顾Map阶段五大步骤
在第四篇博文《初识MapReduce》中,我们认识了MapReduce的八大步凑,其中在Map阶段总共五个步骤,如下图所示:
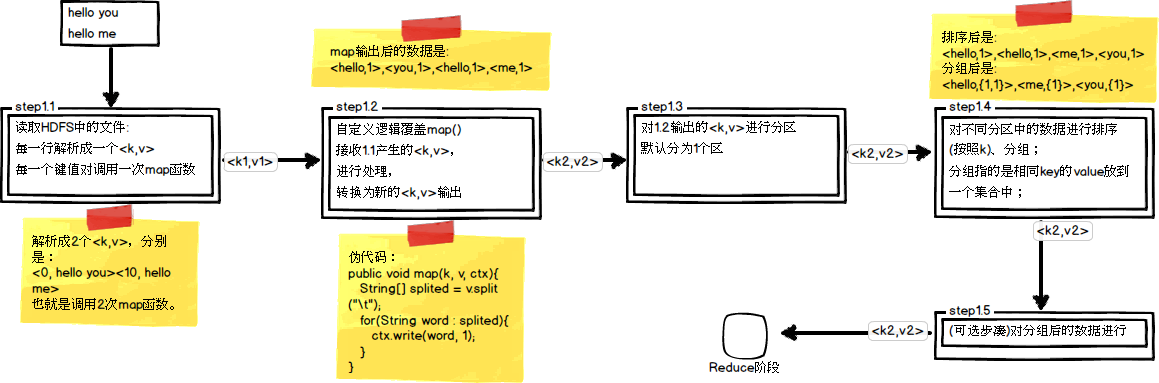
其中,step1.5是一个可选步骤,它就是我们今天需要了解的 Map规约 阶段。现在,我们再来看看前一篇博文《计数器与自定义计数器》中的第一张关于计数器的图:
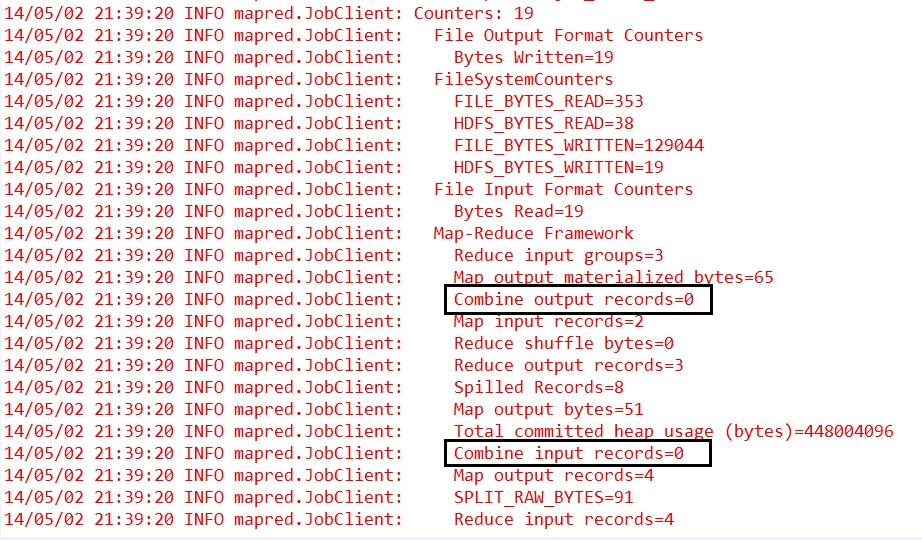
我们可以发现,其中有两个计数器:Combine output records和Combine input records,他们的计数都是0,这是因为我们在代码中没有进行Map阶段的规约操作。
1.2 为什么需要进行Map规约操作
众所周知,Hadoop框架使用Mapper将数据处理成一个个的<key,value>键值对,在网络节点间对其进行整理(shuffle),然后使用Reducer处理数据并进行最终输出。
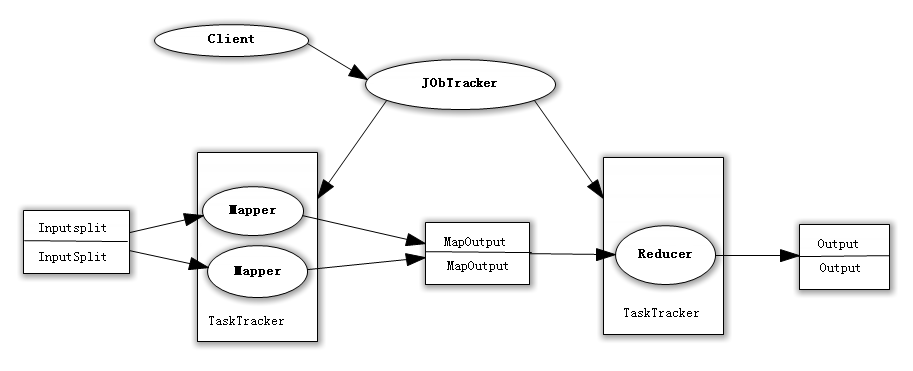
在上述过程中,我们看到至少两个性能瓶颈:
(1)如果我们有10亿个数据,Mapper会生成10亿个键值对在网络间进行传输,但如果我们只是对数据求最大值,那么很明显的Mapper只需要输出它所知道的最大值即可。这样做不仅可以减轻网络压力,同样也可以大幅度提高程序效率。
总结:网络带宽严重被占降低程序效率;
(2)假设使用美国专利数据集中的国家一项来阐述数据倾斜这个定义,这样的数据远远不是一致性的或者说平衡分布的,由于大多数专利的国家都属于美国,这样不仅Mapper中的键值对、中间阶段(shuffle)的键值对等,大多数的键值对最终会聚集于一个单一的Reducer之上,压倒这个Reducer,从而大大降低程序的性能。
总结:单一节点承载过重降低程序性能;
那么,有木有一种方案能够解决这两个问题呢?
二、初步探索Combiner
2.1 Combiner的横空出世
在MapReduce编程模型中,在Mapper和Reducer之间有一个非常重要的组件,它解决了上述的性能瓶颈问题,它就是Combiner。
PS:
①与mapper和reducer不同的是,combiner没有默认的实现,需要显式的设置在conf中才有作用。
②并不是所有的job都适用combiner,只有操作满足结合律的才可设置combiner。combine操作类似于:opt(opt(1, 2, 3), opt(4, 5, 6))。如果opt为求和、求最大值的话,可以使用,但是如果是求中值的话,不适用。
每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量,以提高网络IO性能,是MapReduce的一种优化手段之一,其具体的作用如下所述。
(1)Combiner最基本是实现本地key的聚合,对map输出的key排序,value进行迭代。如下所示:
map: (K1, V1) → list(K2, V2)
combine: (K2, list(V2)) → list(K2, V2)
reduce: (K2, list(V2)) → list(K3, V3)
(2)Combiner还有本地reduce功能(其本质上就是一个reduce),例如Hadoop自带的wordcount的例子和找出value的最大值的程序,combiner和reduce完全一致,如下所示:
map: (K1, V1) → list(K2, V2)
combine: (K2, list(V2)) → list(K3, V3)
reduce: (K3, list(V3)) → list(K4, V4)
PS:现在想想,如果在wordcount中不用combiner,那么所有的结果都是reduce完成,效率会相对低下。使用combiner之后,先完成的map会在本地聚合,提升速度。对于hadoop自带的wordcount的例子,value就是一个叠加的数字,所以map一结束就可以进行reduce的value叠加,而不必要等到所有的map结束再去进行reduce的value叠加。
2.2 融合Combiner的MapReduce
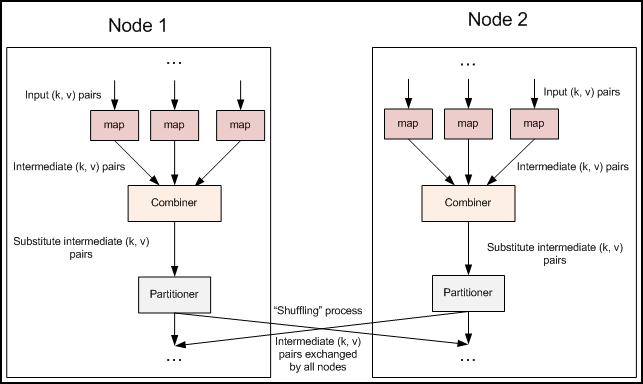
前面文章中的代码都忽略了一个可以优化MapReduce作业所使用带宽的步骤—Combiner,它在Mapper之后Reducer之前运行。Combiner是可选的,如果这个过程适合于你的作业,Combiner实例会在每一个运行map任务的节点上运行。Combiner会接收特定节点上的Mapper实例的输出作为输入,接着Combiner的输出会被发送到Reducer那里,而不是发送Mapper的输出。Combiner是一个“迷你reduce”过程,它只处理单台机器生成的数据。
2.3 使用MyReducer作为Combiner
在前面文章中的WordCount代码中加入以下一句简单的代码,即可加入Combiner方法:
// 设置Map规约Combiner
job.setCombinerClass(MyReducer.class);
还是以下面的文件内容为例,看看这次计数器会发生怎样的改变?
(1)上传的测试文件的内容
hello edison
hello kevin
(2)调试后的计数器日志信息
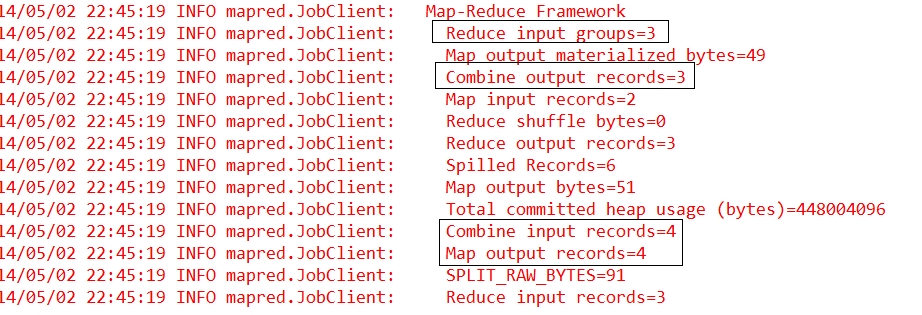
可以看到,原本都为0的Combine input records和Combine output records发生了改变。我们可以清楚地看到map的输出和combine的输入统计是一致的,而combine的输出与reduce的输入统计是一样的。由此可以看出规约操作成功,而且执行在map的最后,reduce之前。
三、自己定义Combiner
为了能够更加清晰的理解Combiner的工作原理,我们自定义一个Combiners类,不再使用MyReduce做为Combiners的类,具体的代码下面一一道来。
3.1 改写Mapper类的map方法
public static class MyMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
String line = value.toString();
String[] spilted = line.split(" ");
for (String word : spilted) {
context.write(new Text(word), new LongWritable(1L));
// 为了显示效果而输出Mapper的输出键值对信息
System.out.println("Mapper输出<" + word + "," + 1 + ">");
}
};
}
3.2 改写Reducer类的reduce方法
public static class MyReducer extends
Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(Text key,
java.lang.Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
// 显示次数表示redcue函数被调用了多少次,表示k2有多少个分组
System.out.println("Reducer输入分组<" + key.toString() + ",N(N>=1)>"); long count = 0L;
for (LongWritable value : values) {
count += value.get();
// 显示次数表示输入的k2,v2的键值对数量
System.out.println("Reducer输入键值对<" + key.toString() + ","
+ value.get() + ">");
}
context.write(key, new LongWritable(count));
};
}
3.3 添加MyCombiner类并重写reduce方法
public static class MyCombiner extends
Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(
Text key,
java.lang.Iterable<LongWritable> values,
org.apache.hadoop.mapreduce.Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
// 显示次数表示规约函数被调用了多少次,表示k2有多少个分组
System.out.println("Combiner输入分组<" + key.toString() + ",N(N>=1)>");
long count = 0L;
for (LongWritable value : values) {
count += value.get();
// 显示次数表示输入的k2,v2的键值对数量
System.out.println("Combiner输入键值对<" + key.toString() + ","
+ value.get() + ">");
}
context.write(key, new LongWritable(count));
// 显示次数表示输出的k2,v2的键值对数量
System.out.println("Combiner输出键值对<" + key.toString() + "," + count
+ ">");
};
}
3.4 添加设置Combiner的代码
// 设置Map规约Combiner
job.setCombinerClass(MyCombiner.class);
3.5 调试运行的控制台输出信息
(1)Mapper
Mapper输出<hello,>
Mapper输出<edison,>
Mapper输出<hello,>
Mapper输出<kevin,>
(2)Combiner
Combiner输入分组<edison,N(N>=)>
Combiner输入键值对<edison,>
Combiner输出键值对<edison,>
Combiner输入分组<hello,N(N>=)>
Combiner输入键值对<hello,>
Combiner输入键值对<hello,>
Combiner输出键值对<hello,>
Combiner输入分组<kevin,N(N>=)>
Combiner输入键值对<kevin,>
Combiner输出键值对<kevin,>
这里可以看出,在Combiner中进行了一次本地的Reduce操作,从而简化了远程Reduce节点的归并压力。
(3)Reducer
Reducer输入分组<edison,N(N>=)>
Reducer输入键值对<edison,>
Reducer输入分组<hello,N(N>=)>
Reducer输入键值对<hello,>
Reducer输入分组<kevin,N(N>=)>
Reducer输入键值对<kevin,>
这里可以看出,在对hello的归并上,只进行了一次操作就完成了。
那么,如果我们再来看看不添加Combiner时的控制台输出信息:
(1)Mapper
Mapper输出<hello,>
Mapper输出<edison,>
Mapper输出<hello,>
Mapper输出<kevin,>
(2)Reducer
Reducer输入分组<edison,N(N>=)>
Reducer输入键值对<edison,>
Reducer输入分组<hello,N(N>=)>
Reducer输入键值对<hello,>
Reducer输入键值对<hello,>
Reducer输入分组<kevin,N(N>=)>
Reducer输入键值对<kevin,>
可以看出,没有采用Combiner时hello都是由Reducer节点来进行统一的归并,也就是这里为何会有两次hello的输入键值对了。
总结:从控制台的输出信息我们可以发现,其实combine只是把两个相同的hello进行规约,由此输入给reduce的就变成了<hello,2>。在实际的Hadoop集群操作中,我们是由多台主机一起进行MapReduce的,如果加入规约操作,每一台主机会在reduce之前进行一次对本机数据的规约,然后在通过集群进行reduce操作,这样就会大大节省reduce的时间,从而加快MapReduce的处理速度。
参考资料
(1)万川梅、谢正兰,《Hadoop应用开发实战详解(修订版)》:http://item.jd.com/11508248.html
(2)Suddenly,《Hadoop日记Day17-计数器、map规约与分区学习》:http://www.cnblogs.com/sunddenly/p/4009568.html
(3)guoery,《MapReduce中Combiner的使用及误区》:http://blog.csdn.net/guoery/article/details/8529004
(4)iPolaris,《Hadoop中Combiner的使用》:http://blog.csdn.net/ipolaris/article/details/8723782
Hadoop学习笔记—8.Combiner与自定义Combiner的更多相关文章
- Hadoop学习笔记—9.Partitioner与自定义Partitioner
一.初步探索Partitioner 1.1 再次回顾Map阶段五大步骤 在第四篇博文<初识MapReduce>中,我们认识了MapReduce的八大步凑,其中在Map阶段总共五个步骤,如下 ...
- Hadoop学习笔记—7.计数器与自定义计数器
一.Hadoop中的计数器 计数器:计数器是用来记录job的执行进度和状态的.它的作用可以理解为日志.我们通常可以在程序的某个位置插入计数器,用来记录数据或者进度的变化情况,它比日志更便利进行分析. ...
- Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html Hadoop学习笔记—5.自定义类型处理手机上网日志 一.测试数据:手机上网日志 1.1 关于这 ...
- Hadoop学习笔记系列文章导航
一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼数成金成为当务之急.但数据增长 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记系列
Hadoop学习笔记系列 一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
随机推荐
- myeclipse一直卡在loading workbench解决方法
删除工作空间下.metadata中的org.eclipse.ui.workbench org.eclipse.ui.workbench.texteditor
- C++产生随机数
随机数 计算机的随机数都是由伪随机数,即是由小M多项式序列生成的,其中产生每个小序列都有一个初始值,即随机种子.(注意: 小M多项式序列的周期是65535,即每次利用一个随机种子生成的随机数的周期是6 ...
- POJ 3669 Meteor Shower【BFS】
POJ 3669 去看流星雨,不料流星掉下来会砸毁上下左右中五个点.每个流星掉下的位置和时间都不同,求能否活命,如果能活命,最短的逃跑时间是多少? 思路:对流星雨排序,然后将地图的每个点的值设为该点最 ...
- 数据结构0103汉诺塔&八皇后
主要是从汉诺塔及八皇后问题体会递归算法. 汉诺塔: #include <stdio.h> void move(int n, char x,char y, char z){ if(1==n) ...
- HTML基础知识
一个完美的web前端攻城狮,所具备的专业素养有:HTML5.XHTML.CSS3.JavaScript.JQuery.PS.PHP等.所以说,我要学的东西还有很多... 没别得,我也是一个H5的初学者 ...
- Can't load IA 32-bit .dll on a AMD 64-bit platform错误的解决
64位的系统,64位的myeclipse,64位的jdk,64位的tomcat,结果报错:Can't load IA 64-bit .dll on a AMD 32-bit platform,简直无语 ...
- Bug管理系统 BugFree
BugFree - 借鉴微软公司软件研发理念.免费且开放源代码.基于Web的精简版Bug管理系统 在线演示:http://www.bugfree.org.cn/demo/Login.php 其它项目管 ...
- ubuntu 16.04 Dockerfile 安装mysql
默认上MariaDB的包并没有在Ubuntu仓库中.要安装MariaDB,我们首先要设置MariaDB仓库. 配置MariaDB 仓库 # apt-get install software-prope ...
- redhat6 yum源配置
第一次接触redhat系统,安装软件时,发现没有ubuntu的apt-get包管理器,自带的yum包管理器又什么都找不到,网上搜了好久,终于把yum配置好了,感谢博主们- 使用redhat系统自带的y ...
- 用.net在画出镂空图片
最近的一个项目需要用到这个东西,冥思苦想了好几天.还是在同事的帮助下,完成此项难题,希望能够帮助以后的博友们 ! 废话不多说,先看看效果图吧. 首先写一下讲一下思路,首先画一张图,当你的背景,然后在图 ...