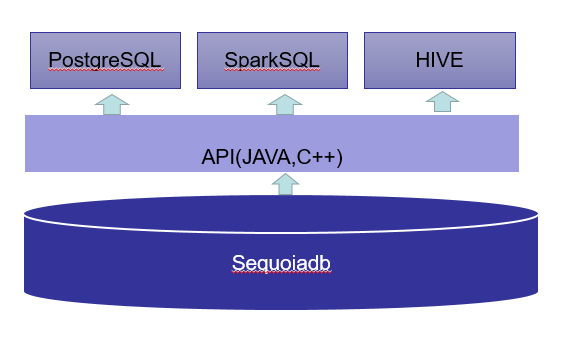
Sequoiadb该如何选择合适的SQL引擎
Sequoiadb作为一个文档型NoSQL数据既可以存储结构化数据也可以存储非结构化数据,对于非结构化数据只能使用原生的API进行查询,对结构化数据我们可以选择使用原生的API和开源SQL引擎,目前PostgresSQL,Hive,SparkSQL都可以作为Sequoiadb的SQL引擎,应用中该如何选择?

Sequoiadb该如何选择合适的SQL引擎的更多相关文章
- Mysql选择合适的存储引擎
Myisam:默认的mysql插件式存储引擎.如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性.并发性要求不是很高,那么选择这个存储引擎是非常合适的.Myisam是在we ...
- MySQL如何选择合适的引擎以及引擎的转换。
我们怎么选择合适的引擎?这里简单归纳一句话:"除非需要用到某些InnoDB不具备的特性,并且没有其他办法可以替代,否则都应该优先选择InnoDB引擎." 除非万不得已,否则不建议混 ...
- Android研究之为基于 x86 的 Android* 游戏选择合适的引擎具体解释
摘要 游戏开发者知道 Android 中蕴藏着巨大的机遇. 在 Google Play 商店的前 100 款应用中,约一半是游戏应用(在利润最高的前 100 款应用中.它们所占的比例超过 90% ...
- 为基于 x86 的 Android* 游戏选择合适的引擎
摘要 游戏开发者知道 Android 中蕴藏着巨大的机遇. 在 Google Play 商店的前 100 款应用中,约一半是游戏应用(在利润最高的前 100 款应用中.它们所占的比例超过 90%). ...
- 谈谈数据库中MyISAM与InnoDB区别 针对业务类型选择合适的表
MyISAM:这个是默认类型,它是基于传统的ISAM类型, ISAM是Indexed Sequential Access Method (有索引的顺序访问方法) 的缩写,它是存储记录和文件的标准方法. ...
- 六大主流开源SQL引擎
导读 本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以 ...
- 六大主流开源SQL引擎总结
本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以及2个 ...
- 重磅开源 KSQL:用于 Apache Kafka 的流数据 SQL 引擎 2017.8.29
Kafka 的作者 Neha Narkhede 在 Confluent 上发表了一篇博文,介绍了Kafka 新引入的KSQL 引擎——一个基于流的SQL.推出KSQL 是为了降低流式处理的门槛,为处理 ...
- 6大主流开源SQL引擎总结,遥遥领先的是谁?
根据 O’Reilly 2016年数据科学薪资调查显示,SQL 是数据科学领域使用最广泛的语言.大部分项目都需要一些SQL 操作,甚至有一些只需要SQL.本文就带你来了解这些主流的开源SQL引擎!背景 ...
随机推荐
- linux进程学习-创建新进程
init进程将系统启动后,init将成为此后所有进程的祖先,此后的进程都是直接或间接从init进程“复制”而来.完成该“复制”功能的函数有fork()和clone()等. 一个进程(父进程)调用for ...
- HTTP协议状态代码和错误状态含义的解释
面试互联网公司经常被问的就是HTTP协议的知识,甚至比TCP/IP问的还多,其中HTTP代码的知识也是开发过程中经常会接触的,今天学习所有 HTTP 状态代码及其定义. 代码 指示 2xx ...
- CodeSmith 基本语法(二)
CodeSmith之四 - 典型实例(四) CodeSmith API文档 (三) CodeSmith 基本语法(二) CodeSmith 图形界面基本操作(一) CodeSmith的C#语法与Asp ...
- 深入理解Spring IOC
转载自 http://www.cnblogs.com/xdp-gacl/p/4249939.html 学习过Spring框架的人一定都会听过Spring的IoC(控制反转) .DI(依赖注入)这两个概 ...
- c++11之二: 类成员变量初始化
在C++11中, 1.允许非静态成员变量的初始化有多种形式:初始化列表; 使用等号=或花括号{}进行就地的初始化. 可以为同一成员变量既声明就地的列表初始化,又在初始化列表中进行初始化,只不过初始化列 ...
- nginx与二级域名的绑定 nginx安装
nginx中文文档 http://www.nginx.cn/doc/ nginx 查看配置文件地址 http://blog.csdn.net/ljfrocky/article/details/5052 ...
- CPU 和 Linux 进程
进程与线程 进程应该是Linux中最重要的一个概念.进程运行在CPU上,是所有硬件资源分配的对象.Linux中用一个task_struct的结构来描述进程,描述了进程的各种信息.属性.资源. Linu ...
- Nginx解决错误413 Request Entity Too Large
最近一个项目当中,要求上传图片,并且限制图片大小,虽然在laravel当中已经添加了相关的表单验证来阻止文件过大的上传,然而当提交表单时,还没轮到laravel处理,nginx就先报错了.当你仔细看报 ...
- 蓝桥杯 算法训练 ALGO-146 4-2找公倍数
算法训练 4-2找公倍数 时间限制:1.0s 内存限制:256.0MB 查看参考代码 问题描述 这里写问题描述. 打印出1-1000所有11和17的公倍数. 样例输入 一个满足题 ...
- eval(function(p,a,c,k,e,r)解密程序
以eval(function(p,a,c,k,e,r){e=function(c)开头的js文件是经过加密的 使用下面方法可以对js文件进行加密.解密 步骤:1.新建html页面,内容如下列代码 2. ...