Sequoiadb该如何选择合适的SQL引擎
Sequoiadb作为一个文档型NoSQL数据既可以存储结构化数据也可以存储非结构化数据,对于非结构化数据只能使用原生的API进行查询,对结构化数据我们可以选择使用原生的API和开源SQL引擎,目前PostgresSQL,Hive,SparkSQL都可以作为Sequoiadb的SQL引擎,应用中该如何选择?

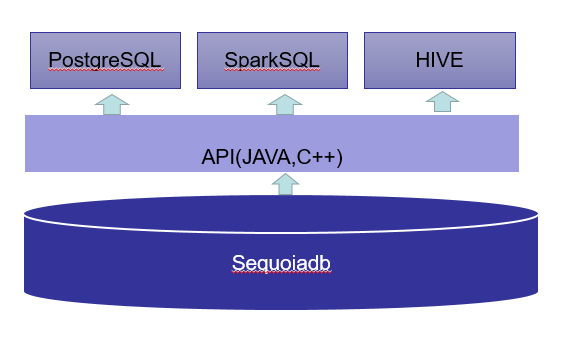
Sequoiadb该如何选择合适的SQL引擎的更多相关文章
- Mysql选择合适的存储引擎
Myisam:默认的mysql插件式存储引擎.如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性.并发性要求不是很高,那么选择这个存储引擎是非常合适的.Myisam是在we ...
- MySQL如何选择合适的引擎以及引擎的转换。
我们怎么选择合适的引擎?这里简单归纳一句话:"除非需要用到某些InnoDB不具备的特性,并且没有其他办法可以替代,否则都应该优先选择InnoDB引擎." 除非万不得已,否则不建议混 ...
- Android研究之为基于 x86 的 Android* 游戏选择合适的引擎具体解释
摘要 游戏开发者知道 Android 中蕴藏着巨大的机遇. 在 Google Play 商店的前 100 款应用中,约一半是游戏应用(在利润最高的前 100 款应用中.它们所占的比例超过 90% ...
- 为基于 x86 的 Android* 游戏选择合适的引擎
摘要 游戏开发者知道 Android 中蕴藏着巨大的机遇. 在 Google Play 商店的前 100 款应用中,约一半是游戏应用(在利润最高的前 100 款应用中.它们所占的比例超过 90%). ...
- 谈谈数据库中MyISAM与InnoDB区别 针对业务类型选择合适的表
MyISAM:这个是默认类型,它是基于传统的ISAM类型, ISAM是Indexed Sequential Access Method (有索引的顺序访问方法) 的缩写,它是存储记录和文件的标准方法. ...
- 六大主流开源SQL引擎
导读 本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以 ...
- 六大主流开源SQL引擎总结
本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以及2个 ...
- 重磅开源 KSQL:用于 Apache Kafka 的流数据 SQL 引擎 2017.8.29
Kafka 的作者 Neha Narkhede 在 Confluent 上发表了一篇博文,介绍了Kafka 新引入的KSQL 引擎——一个基于流的SQL.推出KSQL 是为了降低流式处理的门槛,为处理 ...
- 6大主流开源SQL引擎总结,遥遥领先的是谁?
根据 O’Reilly 2016年数据科学薪资调查显示,SQL 是数据科学领域使用最广泛的语言.大部分项目都需要一些SQL 操作,甚至有一些只需要SQL.本文就带你来了解这些主流的开源SQL引擎!背景 ...
随机推荐
- loj#6566. 月之都的密码
搜交互题搜到的... 竟然还有这么水的交互题,赶紧过了再说 交互库里有一个 $[1,n]$ 到 $[1,n]$ 的双射 你可以调用 $encode(k,a[])$ 询问左边的一个大小为 $k$ 的集合 ...
- [基本操作] kd 树
概念就不说了吧,网上教程满天飞 学了半天才知道,kd 树实质上只干了两件事情: 1.快速定位一个点 / 矩形 2.有理有据地优化暴力 第一点大概是可以来做二维平面上给点/矩形打标记的问题 第二点大概是 ...
- BZOJ5118:Fib数列2(O1快速模)
题意:输入N,输出fib(2^N)%1125899839733759.(P=1125899839733759是素数) 思路:欧拉降幂,因为可以表示为矩阵乘法,2^N在幂的位置,矩阵乘法也可以降幂,所以 ...
- BZOJ1280: Emmy卖猪pigs
BZOJ1280: Emmy卖猪pigs https://lydsy.com/JudgeOnline/problem.php?id=1280 分析: 这题感觉还好,因为是有时间顺序,所以拆点做最大流即 ...
- 洛谷 P3048 [USACO12FEB]牛的IDCow IDs
题目描述 Being a secret computer geek, Farmer John labels all of his cows with binary numbers. However, ...
- !heap 和 _HEAP_ENTRY
WinDBG提供了!heap命令帮助我们查找heap,同时我们也可以通过dt和MS SYMBOL来了解memory layout. 假设我们有下面一个小程序. int _tmain(int argc, ...
- Apache Htpasswd生成和验证密码
Assuming you create the password using the following command and "myPassword" as the passw ...
- [IIS] 不能加载类型System.ServiceModel.Activation.HttpModule
Could not load type ‘System.ServiceModel.Activation.HttpModule’ from assembly ‘System.ServiceModel, ...
- Python 中的0 和 1 的意思
Python程序语言指定任何非0和非空(null)值为true,0 或者 null为false,所以Python中的 1 代表 True,0代表False
- thrift rpc 使用常见问题解答和经验
Thrift是一个非常棒的工具,是Facebook的开源项目,目前的开发非常的活跃,由Apache管理,所以用的是Apache Software License,这非常重要,因为可以放心的对其修改并用 ...