Fasttext原理
fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。
序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。
fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
fasttext结构
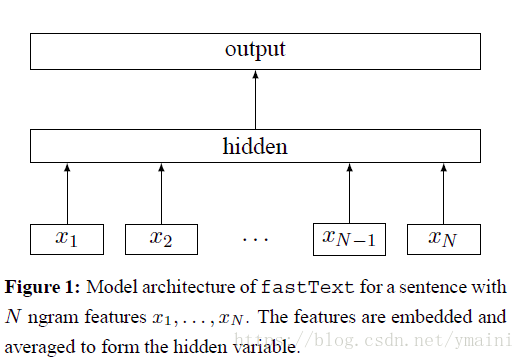
xi
- $X_i$: 一个句子的特征,初始值为随机生成(也可以采用预训练的词向量)
- hidden:$X_i$的平均值 x
- output: 样本标签
目标函数

N:样本个数
$y_n$:第n个样本对应的类别
f:损失函数softmaxt
$x_n$:第n个样本的归一化特征
A:权重矩阵(构建词,embedding)
B:权重举证(隐层到输出层)
词向量初始化
一个句子的embedding为[$iw_1,iw_2,....iw_n,ow_1,ow_2,...ow_s$]
$iw_i$:语料中出现的词,排在数组的前面
$ow_i$:n-gram或n-char特征
初始化为随机数, 如果提供预训练的词向量,对应的词采用预训练的词向量
hierarchical Softmax

当语料类别较多时,使用hierarchical Softmax(hs)减轻计算量
hs利用Huffman 树实现,词(生成词向量)或label(分类问题)作为叶子节点
根据词或label的count构建Huffman 树,则叶子到root一定存在一条路径
利用逻辑回归二分类计算loss
n-gram和n-char
asttext方法不同与word2vec方法,引入了两类特征并进行embedding。其中n-gram颗粒度是词与词之间,n-char是单个词之间。两类特征的存储均通过计算hash值的方法实现。
n-gram
示例: who am I? n-gram设置为2
n-gram特征有,who, who am, am, am I, I
n-char
示例: where, n=3, 设置起止符<, >
n-char特征有,<wh, whe, her, ere, er>
FastText词向量与word2vec对比
FastText= word2vec中 cbow + h-softmax的灵活使用
模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是
分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用;
模型的输入层:word2vec的输入层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容;
两者本质的不同,体现在 h-softmax的使用。
Word2vec的目的是得到词向量,该词向量 最终是在输入层得到,输出层对应的 h-softmax 也会生成一系列的向量,但最终都被抛弃,不会使用。
fasttext则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)。
Fasttext原理的更多相关文章
- 转:fastText原理及实践(达观数据王江)
http://www.52nlp.cn/fasttext 1条回复 本文首先会介绍一些预备知识,比如softmax.ngram等,然后简单介绍word2vec原理,之后来讲解fastText的原理,并 ...
- FastText算法原理解析
1. 前言 自然语言处理(NLP)是机器学习,人工智能中的一个重要领域.文本表达是 NLP中的基础技术,文本分类则是 NLP 的重要应用.fasttext是facebook开源的一个词向量与文本分类工 ...
- 超快的 FastText
Word2Vec 作者.脸书科学家 Mikolov 文本分类新作 fastText:方法简单,号称并不需要深度学习那样几小时或者几天的训练时间,在普通 CPU 上最快几十秒就可以训练模型,得到不错的结 ...
- [转] fastText
mark- from : https://www.jiqizhixin.com/articles/2018-06-05-3 fastText的起源 fastText是FAIR(Facebook AIR ...
- 模型介绍之FastText
模型介绍一: 1. FastText原理及实践 前言----来源&特点 fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新.但是它的优点也 ...
- FastText算法
转载自: https://www.cnblogs.com/huangyc/p/9768872.html 0. 目录 1. 前言 2. FastText原理 2.1 模型架构 2.2 层次SoftMax ...
- NLP系列文章:子词嵌入(fastText)的理解!(附代码)
1. 什么是fastText 英语单词通常有其内部结构和形成⽅式.例如,我们可以从"dog""dogs"和"dogcatcher"的字⾯上推 ...
- 层次softmax函数(hierarchical softmax)
一.h-softmax 在面对label众多的分类问题时,fastText设计了一种hierarchical softmax函数.使其具有以下优势: (1)适合大型数据+高效的训练速度:能够训练模型“ ...
- Task6.神经网络基础
BP: 正向计算loss,反向传播梯度. 计算梯度时,从输出端开始,前一层的梯度等于activation' *(与之相连的后一层的神经元梯度乘上权重的和). import torch from tor ...
随机推荐
- Cocos Creator学习二:查找节点和查找组件
1.目的:只有通过方便的获取节点对象以及组件,才能较好的进行逻辑控制. 2.通过 cc.find(节点全路径名称字符串) 获取节点. 3.通过getComponent获取组件(注意一个是类型,一个是类 ...
- jieba库的使用和好玩的词云
1.jieba库基本介绍 (1).jieba库概述 jieba是优秀的中文分词第三方库 - 中文文本需要通过分词获得单个的词语 - jieba是优秀的中文分词第三方库,需要额外安装 - ...
- js点击加载更多可以增加几条数据的显示
<div class="list"> <div class="one"> <div class="img" ...
- 【记录】【3】设置bing为chrome的默认搜索引擎
方法:设置→搜索→管理搜索引擎→其他搜索引擎→设置bing搜索的网址为 http://cn.bing.com/search?q=%s 注:search?q=%s 是必须的,否则无法将其设置为默认 ...
- 使用XStream解析复杂XML并插入数据库(一)
环境: Springboot+mysql 我只想说jpa真的超级好用,准备深入研究一下~ 导入依赖: <dependency> <groupId>org.projectlomb ...
- 采用Tensorflow内部函数直接对模型进行冻结
# enhance_raw.py # transform from single frame into multi-frame enhanced single raw from __future__ ...
- mysql 没有全外连接
真实测试过,没有测试过的别再坑人了.别随便乱写了.
- 八大排序算法——快速排序(动图演示 思路分析 实例代码Java 复杂度分析)
一.动图演示 二.思路分析 快速排序的思想就是,选一个数作为基数(这里我选的是第一个数),大于这个基数的放到右边,小于这个基数的放到左边,等于这个基数的数可以放到左边或右边,看自己习惯,这里我是放到了 ...
- java中线程的三种实现方式
一下记录下线程的3中实现方式:Thread,Runnable,Callable 不需要返回值时,建议使用Runnable:有返回值时建议使用Callable 代码如下所示: package com.f ...
- IDEA主类文件需要放置在SRC文件下,非包内
构建flash项目后,主类文件需要放置在src下,而不是在某个包内. 这样才会找到入口主类,然后有输出. 主类里面有引用其他类,需要使用 import * 全部引入.