Python机器学习(python简介篇)
1.Python 数据类型
Python 内置的常用数据类型共有6中:
数字(Number)、布尔值(Boolean)、字符串(String)、元组(Tuple)、列表(List)、字典(Dictionary)。
数字:常用的数字类型包括整型数(Integer)、长整型(Long)、浮点数(Float)、复杂型数(Complex)。
10、100、-100都是整型数;-0.1、10.01是浮点数。
布尔值:True代表真,False代表假。
字符串:在Python里,字符串的表示使用成对的英文单引号,双引号进行表示,‘abc’或“123”。
元组:使用一组小括号()表示,(1,‘abc’,0.4)是一个包含三个元素的元组。假设上例的这个元组叫做t,那么t[0]=1,t[1]='abc'。默认索引的起始值为0,不是1。
列表:使用一对中括号[ ]来组织数据,[1,‘abc’,0.4]。需要注意的是Python允许在访问列表时同时修改列表里的数据,而元组则不然。
字典:包括多组键(key):值(value),Python使用大括号{ }来容纳这些键值对,{1:‘1’,‘abc’:0.1,0.4:80},假设上例字典为变量d,那么d[1]='1',d['abc']=0.1
2.Python 流程控制
比较常见的包括分支语句(if)和循环控制(for)
分支语句语法结构:
if布尔值/表达式:
else:
或者
if布尔值/表达式:
elif布尔值/表达式:
else:
代码1:分支语句代码样例:
=====》
b=True
if b:
print("It's True!")
else:
print('It's False!")
=====》
It's True!
=====》
b=False
c=True
if b:
print("b is True!")
elif c:
print('c is True!")
else:
print("both are False")
=====》
c is True!
循环控制语法结构:
for 临时变量 in 可遍历数据结构(列表、元组、字典)
执行语句
代码2:循环语句代码样例:
=====》
d={1:'1','abc':0.1,0.4:80}
for k in d:
print(k,":",d[k])
=====》
1:1
abc:0.1
0.4:80
1.3 Python函数模块设计
Python采用def关键字来定义一个函数:
代码3:函数定义和调用代码样例:
=====》
def foo(x):
return x**2
print(foo(8.0))
=====》
64.0
1.4 Python编程库(包)的导入
代码4:程序库/工具包导入代码示例
=====》
import math
#调用math包下的函数exp求自然指数
print(math.exp(2))
#2.从(from)math工具包里指定导入exp函数
from math import exp
print(exp(2))
#3.从(from)math工具包里指定导入exp函数,并且对exp重新命名为ep
from math import exp as ep
print(ep(2))
=====》
7.38905609893065
7.38905609893065
7.38905609893065
1.5 Python基础综合实践
代码5:良/恶性乳腺癌肿瘤预测代码样例
=====》
import pandas as pd
#调用pandas工具包的read_csv函数/模块,传入训练文件地址参数,获得返回的数据并且存至变量df_train
df_train=pd.read_csv('breast-cancer-train.csv')
#调用pandas工具包的read_csv函数/模块,传入测试文件地址参数,获得返回的数据并且存至变量df_test
df_test=pd.read_csv('breast-cancer-test.csv')
#选取‘肿块厚度’(Clump Thickness)与‘细胞大小’(Cell Size)作为特征,构建测试集中的正负分类样本
df_test_negative=df_test.loc[df_test['Type']==0][['Clump Thickness','Cell Size']]
df_test_positive=df_test.loc[df_test['Type']==1][['Clump Thickness','Cell Size']]
#导入matplotlib工具包中pyplot并命名为plt
import matplotlib.pyplot as plt
#matplotlib.pyplot.scatter(x,y,s=None,c=None,marker=None)
#x,y接收array。表示x轴和y轴对应的数据。无默认
#s接收数值或者一维的array。指定点的大小,若传入一维array,则表示每个点的大小。默认为None
#c接收颜色或者一维的array。指定点的颜色,若传入一维array,则表示每个点的颜色。默认为None
#marker接收特定string。表示绘制的点的类型。默认为None
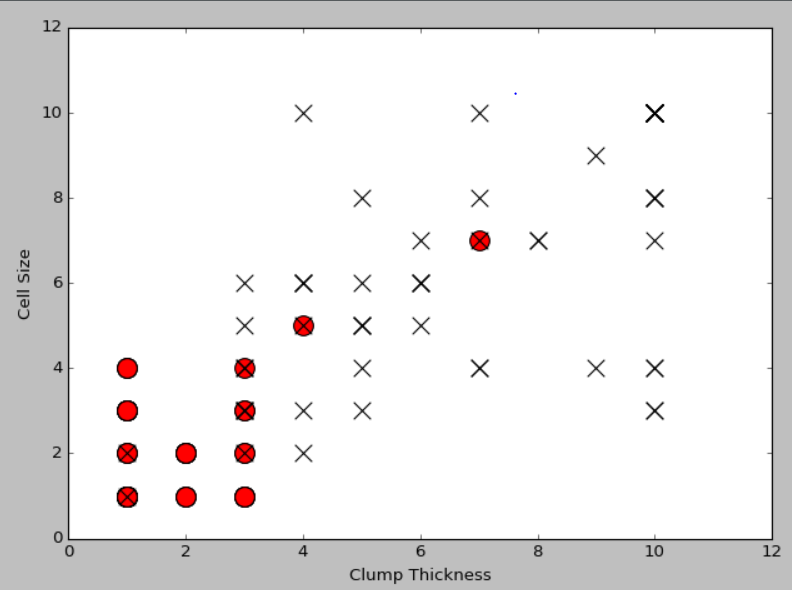
#绘制良性肿瘤样本点,标记为红色的o
plt.scatter(df_test_negative['Clump Thickness'],df_test_negative['Cell Size'],marker='o',s=200,c='red')
#绘制恶性肿瘤样本点,标记为黑色的x
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=150,c='black')
#绘制x,y轴的说明
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
#显示图
plt.show()
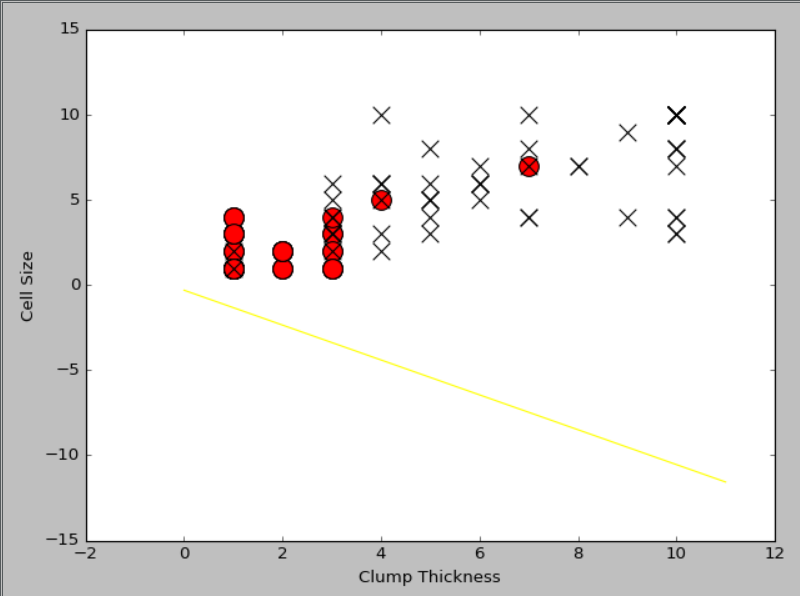
import numpy as np
#利用numpy中的random函数随机采样直线的截距和系数
intercept=np.random.random([1])
# print(intercept)#[0.79195932]
coef=np.random.random([2])
# print(coef)#[0.37965899 0.47387532]
lx=np.arange(0,12)
# print(lx)#[ 0 1 2 3 4 5 6 7 8 9 10 11]
ly=(-intercept-lx*coef[0])/coef[1]
# print(ly)
# [-1.09996728 -1.60387435 -2.10778142 -2.61168849 -3.11559556 -3.61950262
# # -4.12340969 -4.62731676 -5.13122383 -5.6351309 -6.13903797 -6.64294503]
#绘制一条随机直线
plt.plot(lx,ly,c='yellow')
plt.scatter(df_test_negative['Clump Thickness'],df_test_negative['Cell Size'],marker='o',s=200,c='red')
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=150,c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()
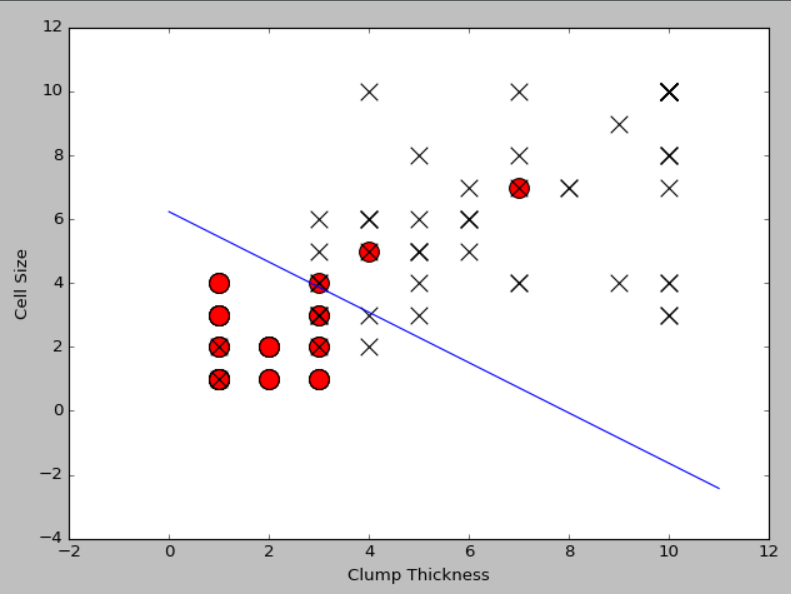
#导入sklearn中的逻辑斯蒂回归分类器
from sklearn.linear_model import LogisticRegression
lr=LogisticRegression()
#使用前10条训练样本学习直线的系数和截距
lr.fit(df_train[['Clump Thickness','Cell Size']][:10],df_train['Type'][:10])
print('Testing accuracy (10 training samples):',lr.score(df_test[['Clump Thickness','Cell Size']],df_test['Type']))
intercept=lr.intercept_
coef=lr.coef_[0,:]
#原本这个分类面应该是lx*coef[0]+ly*coef[1]+intercept=0,映射到2维平面上之后,应该是:
ly=(-intercept-lx*coef[0])/coef[1]
plt.plot(lx,ly,c='green')
plt.scatter(df_test_negative['Clump Thickness'],df_test_negative['Cell Size'],marker='o',s=200,c='red')
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=150,c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()

lr=LogisticRegression()
#使用所有的训练样本学习直线的系数和截距
lr.fit(df_train[['Clump Thickness','Cell Size']],df_train['Type'])
print('Testing accuracy (all training samples):',lr.score(df_test[['Clump Thickness','Cell Size']],df_test['Type']))
intercept=lr.intercept_
coef=lr.coef_[0,:]
#原本这个分类面应该是lx*coef[0]+ly*coef[1]+intercept=0,映射到2维平面上之后,应该是:
ly=(-intercept-lx*coef[0])/coef[1]
plt.plot(lx,ly,c='blue')
plt.scatter(df_test_negative['Clump Thickness'],df_test_negative['Cell Size'],marker='o',s=200,c='red')
plt.scatter(df_test_positive['Clump Thickness'],df_test_positive['Cell Size'],marker='x',s=150,c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()
Testing accuracy (all training samples): 0.9371428571428572
Python机器学习(python简介篇)的更多相关文章
- Python机器学习(基础篇---监督学习(线性分类器))
监督学习经典模型 机器学习中的监督学习模型的任务重点在于,根据已有的经验知识对未知样本的目标/标记进行预测.根据目标预测变量的类型不同,我们把监督学习任务大体分为分类学习与回归预测两类.监督学习任务的 ...
- Python机器学习(基础篇---监督学习(k近邻))
K近邻 假设我们有一些携带分类标记的训练样本,分布于特征空间中,对于一个待分类的测试样本点,未知其类别,按照‘近朱者赤近墨者黑’,我们需要寻找与这个待分类的样本在特征空间中距离最近的k个已标记样本作为 ...
- Python机器学习(基础篇---监督学习(集成模型))
集成模型 集成分类模型是综合考量多个分类器的预测结果,从而做出决策. 综合考量的方式大体分为两种: 1.利用相同的训练数据同时搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数的原则作出最终的 ...
- Python机器学习(基础篇---监督学习(朴素贝叶斯))
朴素贝叶斯 朴素贝叶斯分类器的构造基础是贝叶斯理论.采用概率模型来表述,定义x=<x1,x2,...,xn>为某一n维特征向量,y∈{c1,c2,...ck}为该特征向量x所有k种可能的类 ...
- Python机器学习(基础篇---监督学习(支持向量机))
支持向量机(分类) 支持向量机分类器根据训练样本的分布,搜索所有可能的线性分类器中最佳的那个.我们会发现决定其直线位置的样本并不是所有训练数据,而是其中的两个空间间隔最小的两个不同类别的数据点,而我们 ...
- 机器学习1—简介及Python机器学习环境搭建
简介 前置声明:本专栏的所有文章皆为本人学习时所做笔记而整理成篇,转载需授权且需注明文章来源,禁止商业用途,仅供学习交流.(欢迎大家提供宝贵的意见,共同进步) 正文: 机器学习,顾名思义,就是研究计算 ...
- python机器学习简介
目录 一:学习机器学习原因和能够解决的问题 二:为什么选择python作为机器学习的语言 三:机器学习常用库简介 四:机器学习流程 机器学习是一门多领域交叉学科,涉及概率论.统计学.逼近论.凸分析 ...
- Python学习【第一篇】Python简介
Python简介 Python前世今生 Python是著名的“龟叔”Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言. 现在,全世界差不多有600多种编 ...
- Python之路(第一篇):Python简介和基础
一.开发简介 1.开发: 开发语言: 高级语言:python.JAVA.PHP.C#..ruby.Go-->字节码 低级语言: ...
随机推荐
- 微信、qq二次分享
前言 我们平时做微信分享的时候,一般分享出来的页面都是一个简单的html页面,不会加入框架之类的东西.所以当我们在分享出来的页面里面再次进行分享的时候,由于我们没有配置分享的标题.描述这些东西,分享出 ...
- nc(NetCat)命令
瑞士军刀netcat官网:http://netcat.sourceforge.net/ 安装:yum install -y nc查询:rpm -q nc 语法:nc [-hlnruz][-g<网 ...
- [Linux] 文档编辑搜索
vim filename press / type words which you want to search press Enter Q: How can I search only for wo ...
- 使用pyinstaller打包多个py文件为一个EXE文件
1. 安装pyinstaller. pip install pyinstaller !!!!64位win7上打包后始终不能用,提示找不到ldap模块,换了32位win7就好了.!!!!(代码中涉及ld ...
- 找到多个与名为“Home”的控制器匹配的类型
“/”应用程序中的服务器错误. 找到多个与名为“Home”的控制器匹配的类型.如果为此请求(“{controller}/{action}/{id}”)提供服务的路由没有指定命名空间以搜索与此请求相匹配 ...
- [bzoj P2726] [SDOI2012]任务安排
[bzoj P2726] [SDOI2012]任务安排 Time Limit: 10 Sec Memory Limit: 128 MB Submit: 1204 Solved: 349[Submit] ...
- maven打jar包 没有主属性清单
使用mvn clean package命令打包,java -jar 命令运行时,提示:“jar 包没有主属性清单”.修改pom文件后解决: <build> <plugins> ...
- 多线程之interrupt
1.interrupt()作为中断程序,并不会直接终止运行,而是设置中断状态,由线程自己处理中断.可以选择终止线程.等待新任务或继续执行. 2.interrupt()经常用于中断处于堵塞状态的的线程, ...
- CentOS 7系统上制作Clonezilla(再生龙)启动U盘并克隆双系统
笔记本安装的是双系统:Win7 64位,CentOS 7 64位. 政采就是个巨大的坑,笔记本标配的是5400转的机械硬盘,开机时间常常要一至两分钟,软件运行起来时各种数据的读写也非常慢,忍无可忍,决 ...
- mysql 执行sql流程
客户端发送sql 语句后的堆栈 #0 0x0000000100370565 in do_command(THD*) at percona-server-Percona-Server-5.6.37-82 ...