GBDT的数学原理
一、GBDT的原理
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力较强的算法。
GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类。
GBDT的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合。业界中,Facebook使用其来自动发现有效的特征、特征组合,来作为LR模型中的特征,以提高CTR预估(Click-Through Rate Prediction)的准确性(详见参考文献5、6);GBDT在淘宝的搜索及预测业务上也发挥了重要作用(详见参考文献7)。
提升树利用加法模型和前向分步算法实现学习的优化过程。当损失函数时平方损失和指数损失函数时,每一步的优化很简单,如平方损失函数学习残差回归树。

但对于一般的损失函数,往往每一步优化没那么容易,如上图中的绝对值损失函数和Huber损失函数。针对这一问题,Freidman提出了梯度提升算法:利用最速下降的近似方法,即利用损失函数的负梯度在当前模型的值,作为回归问题中提升树算法的残差的近似值,拟合一个回归树。(注:鄙人私以为,与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例)算法如下(截图来自《The Elements of Statistical Learning》):

算法步骤解释:
- 1、初始化,估计使损失函数极小化的常数值,它是只有一个根节点的树,即ganma是一个常数值。
- 2、
(a)计算损失函数的负梯度在当前模型的值,将它作为残差的估计
(b)估计回归树叶节点区域,以拟合残差的近似值
(c)利用线性搜索估计叶节点区域的值,使损失函数极小化
(d)更新回归树 - 3、得到输出的最终模型 f(x)
二、GBDT的参数设置
1、推荐GBDT树的深度:6;(横向比较:DecisionTree/RandomForest需要把树的深度调到15或更高)
2、【问】xgboost/gbdt在调参时为什么树的深度很少就能达到很高的精度?
用xgboost/gbdt在在调参的时候把树的最大深度调成6就有很高的精度了。但是用DecisionTree/RandomForest的时候需要把树的深度调到15或更高。用RandomForest所需要的树的深度和DecisionTree一样我能理解,因为它是用bagging的方法把DecisionTree组合在一起,相当于做了多次DecisionTree一样。但是xgboost/gbdt仅仅用梯度上升法就能用6个节点的深度达到很高的预测精度,使我惊讶到怀疑它是黑科技了。请问下xgboost/gbdt是怎么做到的?它的节点和一般的DecisionTree不同吗?
【答】
(1)Boosting主要关注降低偏差(bais),因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差(variance),因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。
(2)随机森林(random forest)和GBDT都是属于集成学习(ensemble learning)的范畴。集成学习下有两个重要的策略Bagging和Boosting。
Bagging算法是这样做的:每个分类器都随机从原样本中做有放回的采样,然后分别在这些采样后的样本上训练分类器,然后再把这些分类器组合起来。简单的多数投票一般就可以。其代表算法是随机森林。Boosting的意思是这样,他通过迭代地训练一系列的分类器,每个分类器采用的样本分布都和上一轮的学习结果有关。其代表算法是AdaBoost, GBDT。
(3)其实就机器学习算法来说,其泛化误差可以分解为两部分,偏差(bias)和方差(variance)。这个可由下图的式子导出(这里用到了概率论公式D(X)=E(X^2)-[E(X)]^2)。偏差指的是算法的期望预测与真实预测之间的偏差程度,反应了模型本身的拟合能力;方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。这个有点儿绕,不过你一定知道过拟合。
如下图所示,当模型越复杂时,拟合的程度就越高,模型的训练偏差就越小。但此时如果换一组数据可能模型的变化就会很大,即模型的方差很大。所以模型过于复杂的时候会导致过拟合。
当模型越简单时,即使我们再换一组数据,最后得出的学习器和之前的学习器的差别就不那么大,模型的方差很小。还是因为模型简单,所以偏差会很大。
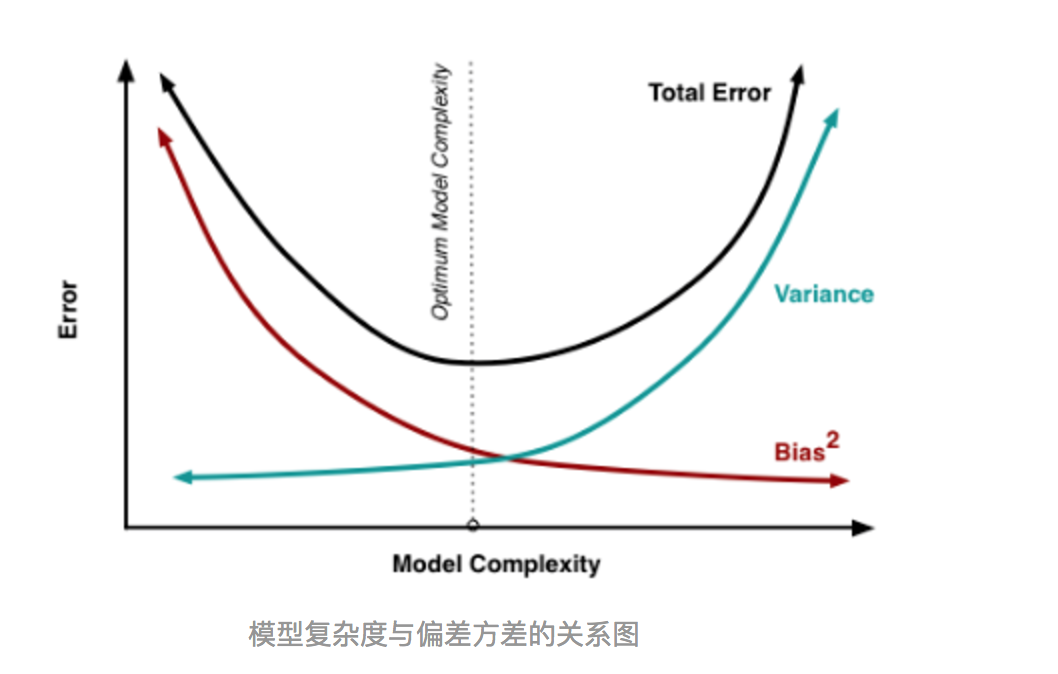
也就是说,当我们训练一个模型时,偏差和方差都得照顾到,漏掉一个都不行。
对于Bagging算法来说,由于我们会并行地训练很多不同的分类器的目的就是降低这个方差(variance) ,因为采用了相互独立的基分类器多了以后,h的值自然就会靠近.所以对于每个基分类器来说,目标就是如何降低这个偏差(bias),所以我们会采用深度很深甚至不剪枝的决策树。
对于Boosting来说,每一步我们都会在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
三、参考文献
1、http://www.jianshu.com/p/005a4e6ac775
GBDT的数学原理的更多相关文章
- 机器学习系列------1. GBDT算法的原理
GBDT算法是一种监督学习算法.监督学习算法需要解决如下两个问题: 1.损失函数尽可能的小,这样使得目标函数能够尽可能的符合样本 2.正则化函数对训练结果进行惩罚,避免过拟合,这样在预测的时候才能够准 ...
- OpenGL坐标变换及其数学原理,两种摄像机交互模型(附源程序)
实验平台:win7,VS2010 先上结果截图(文章最后下载程序,解压后直接运行BIN文件夹下的EXE程序): a.鼠标拖拽旋转物体,类似于OGRE中的“OgreBites::CameraStyle: ...
- RSA加密数学原理
RSA加密数学原理 */--> *///--> *///--> UP | HOME RSA加密数学原理 Table of Contents 1 引言 2 RSA加密解密过程 2.1 ...
- PCA的数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维 数据的 ...
- PCA数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- 【机器学习笔记之七】PCA 的数学原理和可视化效果
PCA 的数学原理和可视化效果 本文结构: 什么是 PCA 数学原理 可视化效果 1. 什么是 PCA PCA (principal component analysis, 主成分分析) 是机器学习中 ...
- word2vec 数学原理
word2vec 是 Google 于 2013 年推出的一个用于获取词向量的开源工具包.我们在项目中多次使用到它,但囿于时间关系,一直没仔细探究其背后的原理. 网络上 <word2vec 中的 ...
- 非对称加密技术- RSA算法数学原理分析
非对称加密技术,在现在网络中,有非常广泛应用.加密技术更是数字货币的基础. 所谓非对称,就是指该算法需要一对密钥,使用其中一个(公钥)加密,则需要用另一个(私钥)才能解密. 但是对于其原理大部分同学应 ...
- PCA的数学原理(转)
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
随机推荐
- curl的POST请求,封装方法
//POST请求//参数1是请求的url//参数2是发送的数据的数组//参数3是其他POST选项public static function POST($url, array $post = arra ...
- [数据结构] 2.7 Heap 堆
* 注: 本文/本系列谢绝转载,如有转载,本人有权利追究相应责任. 1.堆是什么? (如图所示是一个小堆) 1)堆是一颗完全二叉树,它的最后一层不是满的,其他每一层都是满的,最后一层从左到右也没有空隙 ...
- Kotlin 随笔小计
最近准备学Kotlin 现在Kotlin也能支持IOS开发了,准备后面买个Mac也能进行IOS开发 当然目标还是看着能不能把一些小的Android项目重构下 也算是定个目标吧,由于沉迷吃鸡,日志都没怎 ...
- .NetCore WebApi 添加 Log4Net
一 .配置 1.vs2019 创建一个.net core web程序,选择webapi 2.项目中添加一个配置文件:添加--新建项--XML文件,命名为log4net.config 我使用的是log4 ...
- Genymotion下载及安装
引用https://blog.csdn.net/yht2004123/article/details/80146989 一.注册\登录 打开Genymotion官网,https://www.genym ...
- Java集合框架相关知识整理
1.常见的集合有哪些? Collection接口和Map接口是所有集合框架的父接口 Collection接口的子接口包括:Set接口和List接口 Map接口的实现类主要有:HashMap ...
- 通过 txt 文件批量导入需要批量处理的数据的标识字段
前言 在一些工作中,可能需要对数据库中的一些数据(批量)进行处理(修改或者查询),而数据的来源是你的同事,换句话说就是这批数据不可能通过某些查询条件查出来, 而这批数据又比较多,比如几百.几千甚至几万 ...
- 强力推荐!那些你不能错过的 GitHub 插件和工具
以代码托管平台起家的 GitHub 网站,已然成为全球程序员工作和生活中不可或缺的一份子.从优秀的企业,到优秀的程序员,都将自己最优秀的代码作品存放在这片开源净土里,供彼此学习交流.\\LS--201 ...
- 答题卡作文模块的一种方法-VSTO
在开始做之前,首先百度了Word有没有简单的生成方法,果然有--页面布局->稿纸设置->方格式稿纸 效果如下图所示.很规范,但是不是答题卡所需要的,因为这样会把所有页面都设置为这样的稿纸. ...
- List Except 失效 差集失效
https://www.cnblogs.com/benhua/p/6805192.html