SQL Server 索引碎片产生原理重建索引和重新组织索引
数据库存储本身是无序的,建立了聚集索引,会按照聚集索引物理顺序存入硬盘。既键值的逻辑顺序决定了表中相应行的物理顺序
多数情况下,数据库读取频率远高于写入频率,索引的存在 为了读取速度牺牲写入速度
页 为最小单位 8kb
区 物理连续的页(8页)的集合
内部碎片 数据库页内部产生的碎片,外部反之
碎片的产生:
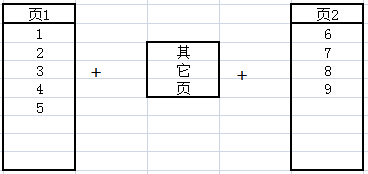
有一个表里有8条数据,已经将一页填满,这个时候要插入第九条数据,页也就分裂了。这就产生了内部碎片。如下图所示(excel示意一下 懒癌晚期)

注: 不会将9单独分到第二页,索引B+树存储,会让存储尽量平衡,以减少检索层级。
且一般情况下SQL Server数据库默认设置有20%的填充因子(可设置),既新建页80%存数据,20%为update和insert预留。
另外,在插入1~8之后 9之前,很可能数据库在这段时间有N多新增数据,也就是在物理结构上 页1 和 页2 无法连续。这就无法避免的产生了外部碎片。
查看碎片情况:
用到这个极重要的 sys.dm_db_index_physical_stats 动态函数,传闻数据库引擎在思考自己如何高效的查询数据的时候都要来这瞅瞅。
太高深的我并不会,目前我就看以下几个,其他参照MSDN
avg_fragmentation_in_percent =>当前索引碎片百分比 【如果碎片小于10%~20%,碎片不太可能会成为问题,如果索引碎片在20%~40%,碎片可能成为问题,但是可以通过索引重组来消除索引解决,大规模的碎片(当碎片大于40%),可能要求索引重建。】
avg_page_space_used_in_percent =>所有页中使用的可用数据存储空间的平均百分比
page_count =>索引或数据页的总数
select * from sys.dm_db_index_physical_stats(DB_ID() ,object_id('agent') ,NULL,NULL,NULL)
碎片的解决:
1.删除索引并重建
这种方式有如下缺点:
索引不可用:在删除索引期间,索引不可用。
阻塞:卸载并重建索引会阻塞表上所有的其他请求,也可能被其他请求所阻塞。
对于删除聚集索引,则会导致对应的非聚集索引重建两次(删除时重建,建立时再重建,因为非聚集索引中有指向聚集索引的指针)。
唯一性约束:用于定义主键或者唯一性约束的索引不能使用DROP INDEX语句删除。而且,唯一性约束和主键都可能被外键约束引用。在主键卸载之前,所有引用该主键的外键必须首先被删除。尽管可以这么做,但这是一种冒险而且费时的碎片整理方法。
基于以上原因,不建议在生产数据库,尤其是非空闲时间不建议采用这种技术。
2.使用DROP_EXISTING语句重建索引
为了避免重建两次索引,使用DROP_EXISTING语句重建索引,因为这个语句是原子性的,不会导致非聚集索引重建两次,但同样的,这种方式也会造成阻塞。
CREATE UNIQUE CLUSTERED INDEX IX_C1 ON t1(c1)
WITH (DROP_EXISTING = ON)
缺点:
阻塞:与卸载重建方法类似,这种技术也导致并面临来自其他访问该表(或该表的索引)的查询的阻塞问题。
使用约束的索引:与卸载重建不同,具有DROP_EXISTING子句的CREATE INDEX语句可以用于重新创建使用约束的索引。如果该约束是一个主键或与外键相关的唯一性约束,在CREATE语句中不能包含UNIQUE。
具有多个碎片化的索引的表:随着表数据产生碎片,索引常常也碎片化。如果使用这种碎片整理技术,表上所有索引都必须单独确认和重建。
3.使用ALTER INDEX REBUILD语句重建索引
使用这个语句同样也是重建索引,但是通过动态重建索引而不需要卸载并重建索引.是优于前两种方法的,但依旧会造成阻塞。可以通过ONLINE关键字减少锁,但会造成重建时间加长。
阻塞:这个依然有阻塞问题。
事务回滚:ALTER INDEX REBUILD完全是一个原子操作,如果它在结束前停止,所有到那时为止进行的碎片整理操作都将丢失,可以通过ONLINE关键字减少锁,但会造成重建时间加长。
4.使用ALTER INDEX REORGANIZE
这种方式不会重建索引,也不会生成新的页,仅仅是整理叶级数据,不涉及非叶级,当遇到加锁的页时跳过,所以不会造成阻塞。但同时,整理效果会差于前三种。
4种索引整理技术比较:
| 特性/问题 | 卸载并重建索引 | DROP_EXISTING | ALTER INDEX REBUILD | ALTER INDEX REORGANIZE |
| 在聚集索引碎片整理时,重建非聚集索引 | 两次 | 无 | 无 | 无 |
| 丢失索引 | 是 | 无 | 无 | 无 |
| 整理具有约束的索引的碎片 | 高度复杂 | 复杂性适中 | 简单 | 简单 |
| 同时进行多个索引的碎片整理 | 否 | 否 | 是 | 是 |
| 并发性 | 低 | 低 | 中等,取决于冰法用户活动 | 高 |
| 中途撤销 | 因为不使用事务,存在危险 | 进程丢失 | 进程丢失 | 进程被保留 |
| 碎片整理程度 | 高 | 高 | 高 | 中到低 |
| 应用新的填充因子 | 是 | 是 | 是 | 否 |
| 更新统计 | 是 | 是 | 是 | 否 |
参考: SQL Server索引的维护 - 索引碎片、填充因子 <第三篇>
msdn sys.dm_db_index_physical_stats (Transact-SQL)
SQL Server 索引碎片产生原理重建索引和重新组织索引的更多相关文章
- SQL Server调优系列进阶篇(如何维护数据库索引)
前言 上一篇我们研究了如何利用索引在数据库里面调优,简要的介绍了索引的原理,更重要的分析了如何选择索引以及索引的利弊项,有兴趣的可以点击查看. 本篇延续上一篇的内容,继续分析索引这块,侧重索引项的日常 ...
- SQL Server调优系列玩转篇三(利用索引提示(Hint)引导语句最大优化运行)
前言 本篇继续玩转模块的内容,关于索引在SQL Server的位置无须多言,本篇将分析如何利用Hint引导语句充分利用索引进行运行,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析. 闲 ...
- SQL server学习(四)T-SQL编程之事务、索引和视图
今天来分享下T-SQL高级编程中的事务.索引.视图,可以和之前的SQL server系列文章结合起来. 一.事务 事务(TRANSACTION)是作为单个逻辑工作单元执行的一系列操作,这些操作作为一个 ...
- SQL Server AlwaysOn架构及原理
SQL Server AlwaysOn架构及原理 SQL Server2012所支持的AlwaysOn技术集中了故障转移群集.数据库镜像和日志传送三者的优点,但又不相同.故障转移群集的单位是SQL实例 ...
- sql server mdf碎片级数据库修复,数据库碎片级提取
sql server mdf碎片级数据库修复,数据库碎片级提取 大家都知道MDF数据库文件一般都比较大,在磁盘中往往被存放到不连续的逻辑簇中,久而久之就形成了文件碎片,当文件被误删除或者格式化后, ...
- SQL SERVER大话存储结构(2)_非聚集索引如何查找到行记录
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有.望各位支持! 1 行记录如何存储 这里引入两个 ...
- SQL Server -- 回忆笔记(四):case函数,索引,子查询,分页查询,视图,存储过程
SQL Server知识点回忆篇(四):case函数,索引,子查询,分页查询,视图,存储过程 1. CASE函数(相当于C#中的Switch) then '未成年人' else '成年人' end f ...
- SQL Server 调优系列玩转篇三(利用索引提示(Hint)引导语句最大优化运行)
前言 本篇继续玩转模块的内容,关于索引在SQL Server的位置无须多言,本篇将分析如何利用Hint引导语句充分利用索引进行运行,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析. 闲 ...
- SQL Server数据库碎片整理
碎片产生 在SQL Server中,存储数据的最小单位是页,每一页所能容纳的数据为8060字节.而页的组织方式是通过B树结构 SQL Server向每个页内存储数据的最小单位是表的行(Row) ...
随机推荐
- [Swift]LeetCode920. 播放列表的数量 | Number of Music Playlists
Your music player contains N different songs and she wants to listen to L (not necessarily different ...
- Java数据结构和算法 - 哈希表
Q: 如何快速地存取员工的信息? A: 假设现在要写一个程序,存取一个公司的员工记录,这个小公司大约有1000个员工,每个员工记录需要1024个字节的存储空间,因此整个数据库的大小约为1MB.一般的计 ...
- 主机名变成bogon?连不上mysql?你需要看下这篇文章
通过navicat for mysql操作部署在虚拟机centos里面的mysql数据库时候总是出现类似于下面的提示信息: Can't connct to MySQL server on '*.*.* ...
- PyPI可以使用的几个国内源
参考 阿里云 http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 豆瓣(dou ...
- Netty(二) 从线程模型的角度看 Netty 为什么是高性能的?
前言 在之前的 SpringBoot 整合长连接心跳机制 一文中认识了 Netty. 但其实只是能用,为什么要用 Netty?它有哪些优势?这些其实都不清楚. 本文就来从历史源头说道说道. 传统 IO ...
- Python接口自动化
1.unittest单元测试框架&接口介绍 2.接口测试框架设计 3.接口的安全机制 4.Mock服务介绍&实现原理 5.Jenkins使用和配置 6 .发送邮箱设置
- 前端笔记之JavaScript(十)深入JavaScript节点&DOM&事件
一.DOM JavaScript语言核心.变量的定义.变量的类型.运算符.表达式.函数.if语句.for循环.算法等等.这些东西都属于语言核心,下次继续学习语言核心就是面向对象了.JavaScript ...
- CVE漏洞—PHPCMS2008 /type.php代码注入高危漏洞预警
11月4日,阿里云安全首次捕获PHPCMS 2008版本的/type.php远程GetShell 0day利用攻击,攻击者可以利用该漏洞远程植入webshell,导致文件篡改.数据泄漏.服务器被远程控 ...
- 图解ARP协议(三)ARP防御篇-如何揪出“内鬼”并“优雅的还手”
一.ARP防御概述 通过之前的文章,我们已经了解了ARP攻击的危害,黑客采用ARP软件进行扫描并发送欺骗应答,同处一个局域网的普通用户就可能遭受断网攻击.流量被限.账号被窃的危险.由于攻击门槛非常低, ...
- springboot情操陶冶-@ConfigurationProperties注解解析
承接前文springboot情操陶冶-@Configuration注解解析,本文将在前文的基础上阐述@ConfigurationProperties注解的使用 @ConfigurationProper ...