SQL Server 索引碎片产生原理重建索引和重新组织索引
数据库存储本身是无序的,建立了聚集索引,会按照聚集索引物理顺序存入硬盘。既键值的逻辑顺序决定了表中相应行的物理顺序
多数情况下,数据库读取频率远高于写入频率,索引的存在 为了读取速度牺牲写入速度
页 为最小单位 8kb
区 物理连续的页(8页)的集合
内部碎片 数据库页内部产生的碎片,外部反之
碎片的产生:
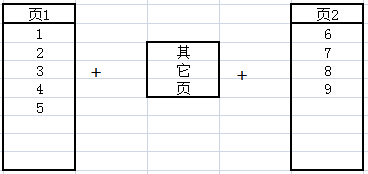
有一个表里有8条数据,已经将一页填满,这个时候要插入第九条数据,页也就分裂了。这就产生了内部碎片。如下图所示(excel示意一下 懒癌晚期)

注: 不会将9单独分到第二页,索引B+树存储,会让存储尽量平衡,以减少检索层级。
且一般情况下SQL Server数据库默认设置有20%的填充因子(可设置),既新建页80%存数据,20%为update和insert预留。
另外,在插入1~8之后 9之前,很可能数据库在这段时间有N多新增数据,也就是在物理结构上 页1 和 页2 无法连续。这就无法避免的产生了外部碎片。
查看碎片情况:
用到这个极重要的 sys.dm_db_index_physical_stats 动态函数,传闻数据库引擎在思考自己如何高效的查询数据的时候都要来这瞅瞅。
太高深的我并不会,目前我就看以下几个,其他参照MSDN
avg_fragmentation_in_percent =>当前索引碎片百分比 【如果碎片小于10%~20%,碎片不太可能会成为问题,如果索引碎片在20%~40%,碎片可能成为问题,但是可以通过索引重组来消除索引解决,大规模的碎片(当碎片大于40%),可能要求索引重建。】
avg_page_space_used_in_percent =>所有页中使用的可用数据存储空间的平均百分比
page_count =>索引或数据页的总数
select * from sys.dm_db_index_physical_stats(DB_ID() ,object_id('agent') ,NULL,NULL,NULL)
碎片的解决:
1.删除索引并重建
这种方式有如下缺点:
索引不可用:在删除索引期间,索引不可用。
阻塞:卸载并重建索引会阻塞表上所有的其他请求,也可能被其他请求所阻塞。
对于删除聚集索引,则会导致对应的非聚集索引重建两次(删除时重建,建立时再重建,因为非聚集索引中有指向聚集索引的指针)。
唯一性约束:用于定义主键或者唯一性约束的索引不能使用DROP INDEX语句删除。而且,唯一性约束和主键都可能被外键约束引用。在主键卸载之前,所有引用该主键的外键必须首先被删除。尽管可以这么做,但这是一种冒险而且费时的碎片整理方法。
基于以上原因,不建议在生产数据库,尤其是非空闲时间不建议采用这种技术。
2.使用DROP_EXISTING语句重建索引
为了避免重建两次索引,使用DROP_EXISTING语句重建索引,因为这个语句是原子性的,不会导致非聚集索引重建两次,但同样的,这种方式也会造成阻塞。
CREATE UNIQUE CLUSTERED INDEX IX_C1 ON t1(c1)
WITH (DROP_EXISTING = ON)
缺点:
阻塞:与卸载重建方法类似,这种技术也导致并面临来自其他访问该表(或该表的索引)的查询的阻塞问题。
使用约束的索引:与卸载重建不同,具有DROP_EXISTING子句的CREATE INDEX语句可以用于重新创建使用约束的索引。如果该约束是一个主键或与外键相关的唯一性约束,在CREATE语句中不能包含UNIQUE。
具有多个碎片化的索引的表:随着表数据产生碎片,索引常常也碎片化。如果使用这种碎片整理技术,表上所有索引都必须单独确认和重建。
3.使用ALTER INDEX REBUILD语句重建索引
使用这个语句同样也是重建索引,但是通过动态重建索引而不需要卸载并重建索引.是优于前两种方法的,但依旧会造成阻塞。可以通过ONLINE关键字减少锁,但会造成重建时间加长。
阻塞:这个依然有阻塞问题。
事务回滚:ALTER INDEX REBUILD完全是一个原子操作,如果它在结束前停止,所有到那时为止进行的碎片整理操作都将丢失,可以通过ONLINE关键字减少锁,但会造成重建时间加长。
4.使用ALTER INDEX REORGANIZE
这种方式不会重建索引,也不会生成新的页,仅仅是整理叶级数据,不涉及非叶级,当遇到加锁的页时跳过,所以不会造成阻塞。但同时,整理效果会差于前三种。
4种索引整理技术比较:
| 特性/问题 | 卸载并重建索引 | DROP_EXISTING | ALTER INDEX REBUILD | ALTER INDEX REORGANIZE |
| 在聚集索引碎片整理时,重建非聚集索引 | 两次 | 无 | 无 | 无 |
| 丢失索引 | 是 | 无 | 无 | 无 |
| 整理具有约束的索引的碎片 | 高度复杂 | 复杂性适中 | 简单 | 简单 |
| 同时进行多个索引的碎片整理 | 否 | 否 | 是 | 是 |
| 并发性 | 低 | 低 | 中等,取决于冰法用户活动 | 高 |
| 中途撤销 | 因为不使用事务,存在危险 | 进程丢失 | 进程丢失 | 进程被保留 |
| 碎片整理程度 | 高 | 高 | 高 | 中到低 |
| 应用新的填充因子 | 是 | 是 | 是 | 否 |
| 更新统计 | 是 | 是 | 是 | 否 |
参考: SQL Server索引的维护 - 索引碎片、填充因子 <第三篇>
msdn sys.dm_db_index_physical_stats (Transact-SQL)
SQL Server 索引碎片产生原理重建索引和重新组织索引的更多相关文章
- SQL Server调优系列进阶篇(如何维护数据库索引)
前言 上一篇我们研究了如何利用索引在数据库里面调优,简要的介绍了索引的原理,更重要的分析了如何选择索引以及索引的利弊项,有兴趣的可以点击查看. 本篇延续上一篇的内容,继续分析索引这块,侧重索引项的日常 ...
- SQL Server调优系列玩转篇三(利用索引提示(Hint)引导语句最大优化运行)
前言 本篇继续玩转模块的内容,关于索引在SQL Server的位置无须多言,本篇将分析如何利用Hint引导语句充分利用索引进行运行,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析. 闲 ...
- SQL server学习(四)T-SQL编程之事务、索引和视图
今天来分享下T-SQL高级编程中的事务.索引.视图,可以和之前的SQL server系列文章结合起来. 一.事务 事务(TRANSACTION)是作为单个逻辑工作单元执行的一系列操作,这些操作作为一个 ...
- SQL Server AlwaysOn架构及原理
SQL Server AlwaysOn架构及原理 SQL Server2012所支持的AlwaysOn技术集中了故障转移群集.数据库镜像和日志传送三者的优点,但又不相同.故障转移群集的单位是SQL实例 ...
- sql server mdf碎片级数据库修复,数据库碎片级提取
sql server mdf碎片级数据库修复,数据库碎片级提取 大家都知道MDF数据库文件一般都比较大,在磁盘中往往被存放到不连续的逻辑簇中,久而久之就形成了文件碎片,当文件被误删除或者格式化后, ...
- SQL SERVER大话存储结构(2)_非聚集索引如何查找到行记录
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有.望各位支持! 1 行记录如何存储 这里引入两个 ...
- SQL Server -- 回忆笔记(四):case函数,索引,子查询,分页查询,视图,存储过程
SQL Server知识点回忆篇(四):case函数,索引,子查询,分页查询,视图,存储过程 1. CASE函数(相当于C#中的Switch) then '未成年人' else '成年人' end f ...
- SQL Server 调优系列玩转篇三(利用索引提示(Hint)引导语句最大优化运行)
前言 本篇继续玩转模块的内容,关于索引在SQL Server的位置无须多言,本篇将分析如何利用Hint引导语句充分利用索引进行运行,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析. 闲 ...
- SQL Server数据库碎片整理
碎片产生 在SQL Server中,存储数据的最小单位是页,每一页所能容纳的数据为8060字节.而页的组织方式是通过B树结构 SQL Server向每个页内存储数据的最小单位是表的行(Row) ...
随机推荐
- 微信小程序实现图片是上传、预览功能
本文实例讲述了微信小程序实现图片上传.删除和预览功能的方法,分享给大家供大家参考,具体如下: 这里主要介绍一下微信小程序的图片上传图片删除和图片预览 1.可以调用相机也可以从本地相册选择 2.本地实现 ...
- Python内置函数(67)——zip
英文文档: zip(*iterables) Make an iterator that aggregates elements from each of the iterables. Returns ...
- BBS论坛(二十九)
29.帖子详情页布局 (1)front/hooks.py @bp.errorhandler def page_not_found(): return render_template('front/fr ...
- 源码安装zabbix_agent4.0.3
1.源码包下载地址:https://www.zabbix.com/download_sources 2.下载完后上传在任意目录用root用户创建以下脚本server_ip为服务端ip然后执行. gro ...
- C++版 - 剑指offer面试题38:数字在已排序数组中出现的次数
数字在已排序数组中出现的次数 提交网址: http://www.nowcoder.com/practice/70610bf967994b22bb1c26f9ae901fa2?tpId=13&t ...
- Unix程序员的Win10二三事
macOS延续自BSD Unix, Linux则是从内核开始重新编写但延续Unix使用方式的Unix.所以mac还有linux程序员,一般都算是*nix程序员,尽管其中还有不少的区别. Windows ...
- Spring Boot分布式系统实践【1】-架构设计
前言 [第一次尝试去写一个系列,肯定会有想不到的地方,欢迎大家留言指正] 本系列将介绍如果从零构建一套分布式系统.同时也是对自己过去工作的一个梳理过程. 本文先整理出构建系统的主要技术选型,以及技术框 ...
- 补习系列(6)- springboot 整合 shiro 一指禅
目标 了解ApacheShiro是什么,能做什么: 通过QuickStart 代码领会 Shiro的关键概念: 能基于SpringBoot 整合Shiro 实现URL安全访问: 掌握基于注解的方法,以 ...
- Java读取Excel指定列的数据详细教程和注意事项
本文使用jxl.jar工具类库实现读取Excel中指定列的数据. jxl.jar是通过java操作excel表格的工具类库,是由java语言开发而成的.这套API是纯Java的,并不依赖Windows ...
- springboot(五)过滤器和拦截器
前言 过滤器和拦截器二者都是AOP编程思想的提现,都能实现诸如权限检查.日志记录等.二者有一定的相似之处,不同的地方在于: Filter是servlet规范,只能用在Web程序中,而拦截器是Sprin ...