ID 生成器 雪花算法
https://blog.csdn.net/wangming520liwei/article/details/80843248
ID 生成器 雪花算法
我们的业务需求中通常有需要一些唯一的ID,来记录我们某个数据的标识:
某个用户的ID
某个订单的单号
某个信息的ID
看图理解
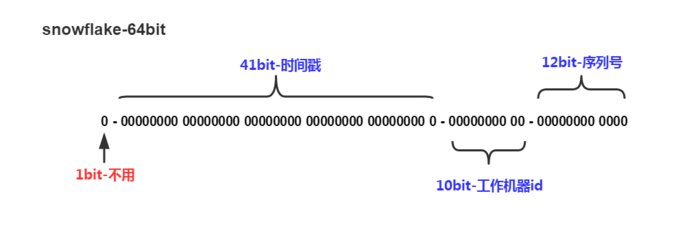
详细的看代码注释
1bit:一般是符号位,不做处理
41bit:用来记录时间戳,这里可以记录69年,如果设置好起始时间比如今年是2018年,那么可以用到2089年,到时候怎么办?要是这个系统能用69年,我相信这个系统早都重构了好多次了。
10bit:10bit用来记录机器ID,总共可以记录1024台机器,一般用前5位代表数据中心,后面5位是某个数据中心的机器ID
12bit:循环位,用来对同一个毫秒之内产生不同的ID,12位可以最多记录4095个,也就是在同一个机器同一毫秒最多记录4095个,多余的需要进行等待下毫秒。
- public class SnowflakeIdWorker {
- /**
- * 雪花算法解析 结构 snowflake的结构如下(每部分用-分开):
- * 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
- * 第一位为未使用,接下来的41位为毫秒级时间(41位的长度可以使用69年),然后是5位datacenterId和5位workerId(10
- * 位的长度最多支持部署1024个节点) ,最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
- *
- * 一共加起来刚好64位,为一个Long型。(转换成字符串长度为18)
- *
- */
- // ==============================Fields===========================================
- /** 开始时间截 (2015-01-01) */
- private final long twepoch = 1489111610226L;
- /** 机器id所占的位数 */
- private final long workerIdBits = 5L;
- /** 数据标识id所占的位数 */
- private final long dataCenterIdBits = 5L;
- /** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
- private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
- /** 支持的最大数据标识id,结果是31 */
- private final long maxDataCenterId = -1L ^ (-1L << dataCenterIdBits);
- /** 序列在id中占的位数 */
- private final long sequenceBits = 12L;
- /** 机器ID向左移12位 */
- private final long workerIdShift = sequenceBits;
- /** 数据标识id向左移17位(12+5) */
- private final long dataCenterIdShift = sequenceBits + workerIdBits;
- /** 时间截向左移22位(5+5+12) */
- private final long timestampLeftShift = sequenceBits + workerIdBits + dataCenterIdBits;
- /** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
- private final long sequenceMask = -1L ^ (-1L << sequenceBits);
- /** 工作机器ID(0~31) */
- private long workerId;
- /** 数据中心ID(0~31) */
- private long dataCenterId;
- /** 毫秒内序列(0~4095) */
- private long sequence = 0L;
- /** 上次生成ID的时间截 */
- private long lastTimestamp = -1L;
- // ==============================Constructors=====================================
- /**
- * 构造函数
- * @param workerId 工作ID (0~31)
- * @param dataCenterId 数据中心ID (0~31)
- */
- public SnowflakeIdWorker(long workerId, long dataCenterId) {
- if (workerId > maxWorkerId || workerId < 0) {
- throw new IllegalArgumentException(String.format("workerId can't be greater than %d or less than 0", maxWorkerId));
- }
- if (dataCenterId > maxDataCenterId || dataCenterId < 0) {
- throw new IllegalArgumentException(String.format("dataCenterId can't be greater than %d or less than 0", maxDataCenterId));
- }
- this.workerId = workerId;
- this.dataCenterId = dataCenterId;
- }
- // ==============================Methods==========================================
- /**
- * 获得下一个ID (该方法是线程安全的)
- * @return SnowflakeId
- */
- public synchronized long nextId() {
- long timestamp = timeGen();
- // 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
- if (timestamp < lastTimestamp) {
- throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
- }
- // 如果是同一时间生成的,则进行毫秒内序列
- // sequenceMask 为啥是4095 2^12 = 4096
- if (lastTimestamp == timestamp) {
- // 每次+1
- sequence = (sequence + 1) & sequenceMask;
- // 毫秒内序列溢出
- if (sequence == 0) {
- // 阻塞到下一个毫秒,获得新的时间戳
- timestamp = tilNextMillis(lastTimestamp);
- }
- }
- // 时间戳改变,毫秒内序列重置
- else {
- sequence = 0L;
- }
- // 上次生成ID的时间截
- lastTimestamp = timestamp;
- // 移位并通过或运算拼到一起组成64位的ID
- // 为啥时间戳减法向左移动22 位 因为 5位datacenterid
- // 为啥 datCenterID向左移动17位 因为 前面有5位workid 还有12位序列号 就是17位
- //为啥 workerId向左移动12位 因为 前面有12位序列号 就是12位
- System.out.println(((timestamp - twepoch) << timestampLeftShift) //
- | (dataCenterId << dataCenterIdShift) //
- | (workerId << workerIdShift) //
- | sequence);
- return ((timestamp - twepoch) << timestampLeftShift) //
- | (dataCenterId << dataCenterIdShift) //
- | (workerId << workerIdShift) //
- | sequence;
- }
- /**
- * 阻塞到下一个毫秒,直到获得新的时间戳
- * @param lastTimestamp 上次生成ID的时间截
- * @return 当前时间戳
- */
- protected long tilNextMillis(long lastTimestamp) {
- long timestamp = timeGen();
- while (timestamp <= lastTimestamp) {
- timestamp = timeGen();
- }
- return timestamp;
- }
- /**
- * 返回以毫秒为单位的当前时间
- * @return 当前时间(毫秒)
- */
- protected long timeGen() {
- return System.currentTimeMillis();
- }
- // ==============================Test=============================================
- /** 测试 */
- public static void main(String[] args) {
- System.out.println(System.currentTimeMillis());
- SnowflakeIdWorker idWorker = new SnowflakeIdWorker(1, 1);
- long startTime = System.nanoTime();
- for (int i = 0; i < 50000; i++) {
- long id = idWorker.nextId();
- System.out.println(id);
- }
- System.out.println((System.nanoTime() - startTime) / 1000000 + "ms");
- }
- }
因为机器的原因会发生时间回拨,我们的雪花算法是强依赖我们的时间的,如果时间发生回拨,有可能会生成重复的ID
普通的算法会直接抛出异常,这里我们可以对其进行优化,一般分为两个情况:
如果时间回拨时间较短,比如配置5ms以内,那么可以直接等待一定的时间,让机器的时间追上来。
如果时间的回拨时间较长,我们不能接受这么长的阻塞等待,那么又有两个策略:
直接拒绝,抛出异常,打日志,通知RD时钟回滚。
利用扩展位,上面我们讨论过不同业务场景位数可能用不到那么多,那么我们可以把扩展位数利用起来了,比如当这个时间回拨比较长的时候,我们可以不需要等待,直接在扩展位加1。2位的扩展位允许我们有3次大的时钟回拨,一般来说就够了,如果其超过三次我们还是选择抛出异常,打日志。
ID 生成器 雪花算法的更多相关文章
- 唯一ID生成器--雪花算法
在微服务架构,分布式系统中的操作会有一些全局性ID的需求,所以我们不能用数据库本身的自增功能来产生主键值,只能由程序来生成唯一的主键值.我们采用的是twitter的snokeflake(雪花)算法. ...
- 生成主键ID,唯一键id,分布式ID生成器雪花算法代码实现
工具类: package com.ihrm.common.utils; import java.lang.management.ManagementFactory; import java.net. ...
- ID生成 雪花算法
/** * ID生成 雪花算法 */ public class SnowFlake { public static SnowFlake getInstance() { return Singleton ...
- 分布式ID的雪花算法及坑
分布式ID生成是目前系统的常见刚需,其中以Twitter的雪花算法(Snowflake)比较知名,有Java等各种语言的版本及各种改进版本,能生成满足分布式ID,返回ID为Long长整数 但是这里有一 ...
- 全局ID生成--雪花算法
分布式ID常见生成策略: 分布式ID生成策略常见的有如下几种: 数据库自增ID. UUID生成. Redis的原子自增方式. 数据库水平拆分,设置初始值和相同的自增步长. 批量申请自增ID. 雪花算法 ...
- 适用于分布式ID的雪花算法
基于Java实现的适用于分布式ID的雪花算法工具类,这里存一下日后好找 /** * 雪花算法生成ID */ public class SnowFlakeUtil { private final sta ...
- 分布式ID生成 - 雪花算法
雪花算法是一种生成分布式全局唯一ID的经典算法,关于雪花算法的解读网上多如牛毛,大多抄来抄去,这里请参考耕耘的小象大神的博客ID生成器,Twitter的雪花算法(Java) 网上的教程一般存在两个问题 ...
- 生成ID之雪花算法
package com.shopping.test; /** * SnowFlake的结构如下(每部分用-分开):<br> * 0 - 0000000000 0000000000 0000 ...
- 全局ID生成--雪花算法改进版
存在的问题 时间回拨问题:由于机器的时间是动态的调整的,有可能会出现时间跑到之前几毫秒,如果这个时候获取到了这种时间,则会出现数据重复 机器id分配及回收问题:目前机器id需要每台机器不一样,这样的方 ...
随机推荐
- idea构建spark开发环境,并本地运行wordcount
1.首先现在idea,官网:https://www.jetbrains.com/idea/ 2.安装jdk1.8,scala2.11 3.下载idea后,需要在idea中安装scala的插件,安装的方 ...
- CC2640蓝牙芯片开发备记
server ,characteristic UUID ,handle sever ,一个工程里可以有多个服务,按键服务,心率计服务,马达服务. characteristic , 一个服务可以有多个的 ...
- matlab程序设计
一.M文件 1.脚本文件 (1)英文字母开头命名 (2)所产生的所有变量驻留在base workspace,只要不用clear,就只有关闭MATLAB,才会被删除 2.函数文件 (1)function ...
- python学习笔记3-函数
一.函数高级特性 1)列表生成式,列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式. eg: >>> list(r ...
- windows.h详解
参考 http://blog.csdn.net/fengningning/article/details/2306650?locationNum=1&fps=1 windows.h解构 刚开头 ...
- Linux运维工程师应具备哪些技能?
对于我们这些刚入门的运维小白来说,极强的好奇心总会驱使我们去涉猎各种技术,弄到最后很可能该学的知识半懵半解,知识体系混乱,学习毫无章法.因此,我们学习 时要有一个明确的目标和知识体系(也是我学习的 ...
- ASP.NET MVC学习中记录下使用JavaScript和CSS层叠样式表的经历
首先我是想要在ASP.NET MVC 5.0中使用从jQuery之家下载下来的插件. 在下载了许多我觉得好用方便的插件之后,我在VS2017中新建了一个项目叫MVCTest,然后选择MVC模板,等待自 ...
- 用http请求一直失败,用https开头就ok了
今天晚上在调试新浪的程序,发现之前一直可以用的接口,有时候就会失败, 各项参数全部仔细核对,都没有发现任何不同之处,真是奇了怪了. 后来一看,post 的部分,之前是用 http:// 开头的,但是此 ...
- 常用git操作命令
查看远程仓库 ->$ git remote -v 如果你本地有一个项目,想把他放到远程git服务器上,那就用上面的命令把项目 add 到远程服务器 ->$ git remote a ...
- vue 父子组件通信
算是初学vue,整理一下父子组件通信笔记. 父组件通过 prop 给子组件下发数据,子组件通过事件给父组件发送消息. 一.父组件向子组件下发数据: 1.在子组件中显式地用props选项声明它预期的数据 ...