ID 生成器 雪花算法
https://blog.csdn.net/wangming520liwei/article/details/80843248
ID 生成器 雪花算法
我们的业务需求中通常有需要一些唯一的ID,来记录我们某个数据的标识:
某个用户的ID
某个订单的单号
某个信息的ID
看图理解
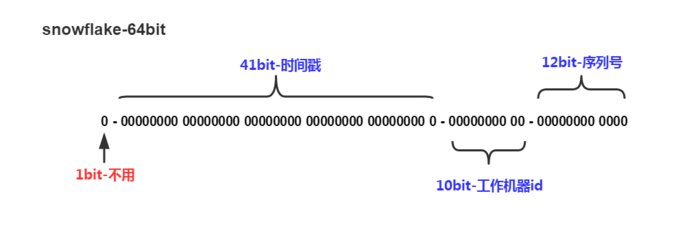
详细的看代码注释
1bit:一般是符号位,不做处理
41bit:用来记录时间戳,这里可以记录69年,如果设置好起始时间比如今年是2018年,那么可以用到2089年,到时候怎么办?要是这个系统能用69年,我相信这个系统早都重构了好多次了。
10bit:10bit用来记录机器ID,总共可以记录1024台机器,一般用前5位代表数据中心,后面5位是某个数据中心的机器ID
12bit:循环位,用来对同一个毫秒之内产生不同的ID,12位可以最多记录4095个,也就是在同一个机器同一毫秒最多记录4095个,多余的需要进行等待下毫秒。
- public class SnowflakeIdWorker {
- /**
- * 雪花算法解析 结构 snowflake的结构如下(每部分用-分开):
- * 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
- * 第一位为未使用,接下来的41位为毫秒级时间(41位的长度可以使用69年),然后是5位datacenterId和5位workerId(10
- * 位的长度最多支持部署1024个节点) ,最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
- *
- * 一共加起来刚好64位,为一个Long型。(转换成字符串长度为18)
- *
- */
- // ==============================Fields===========================================
- /** 开始时间截 (2015-01-01) */
- private final long twepoch = 1489111610226L;
- /** 机器id所占的位数 */
- private final long workerIdBits = 5L;
- /** 数据标识id所占的位数 */
- private final long dataCenterIdBits = 5L;
- /** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
- private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
- /** 支持的最大数据标识id,结果是31 */
- private final long maxDataCenterId = -1L ^ (-1L << dataCenterIdBits);
- /** 序列在id中占的位数 */
- private final long sequenceBits = 12L;
- /** 机器ID向左移12位 */
- private final long workerIdShift = sequenceBits;
- /** 数据标识id向左移17位(12+5) */
- private final long dataCenterIdShift = sequenceBits + workerIdBits;
- /** 时间截向左移22位(5+5+12) */
- private final long timestampLeftShift = sequenceBits + workerIdBits + dataCenterIdBits;
- /** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
- private final long sequenceMask = -1L ^ (-1L << sequenceBits);
- /** 工作机器ID(0~31) */
- private long workerId;
- /** 数据中心ID(0~31) */
- private long dataCenterId;
- /** 毫秒内序列(0~4095) */
- private long sequence = 0L;
- /** 上次生成ID的时间截 */
- private long lastTimestamp = -1L;
- // ==============================Constructors=====================================
- /**
- * 构造函数
- * @param workerId 工作ID (0~31)
- * @param dataCenterId 数据中心ID (0~31)
- */
- public SnowflakeIdWorker(long workerId, long dataCenterId) {
- if (workerId > maxWorkerId || workerId < 0) {
- throw new IllegalArgumentException(String.format("workerId can't be greater than %d or less than 0", maxWorkerId));
- }
- if (dataCenterId > maxDataCenterId || dataCenterId < 0) {
- throw new IllegalArgumentException(String.format("dataCenterId can't be greater than %d or less than 0", maxDataCenterId));
- }
- this.workerId = workerId;
- this.dataCenterId = dataCenterId;
- }
- // ==============================Methods==========================================
- /**
- * 获得下一个ID (该方法是线程安全的)
- * @return SnowflakeId
- */
- public synchronized long nextId() {
- long timestamp = timeGen();
- // 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
- if (timestamp < lastTimestamp) {
- throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
- }
- // 如果是同一时间生成的,则进行毫秒内序列
- // sequenceMask 为啥是4095 2^12 = 4096
- if (lastTimestamp == timestamp) {
- // 每次+1
- sequence = (sequence + 1) & sequenceMask;
- // 毫秒内序列溢出
- if (sequence == 0) {
- // 阻塞到下一个毫秒,获得新的时间戳
- timestamp = tilNextMillis(lastTimestamp);
- }
- }
- // 时间戳改变,毫秒内序列重置
- else {
- sequence = 0L;
- }
- // 上次生成ID的时间截
- lastTimestamp = timestamp;
- // 移位并通过或运算拼到一起组成64位的ID
- // 为啥时间戳减法向左移动22 位 因为 5位datacenterid
- // 为啥 datCenterID向左移动17位 因为 前面有5位workid 还有12位序列号 就是17位
- //为啥 workerId向左移动12位 因为 前面有12位序列号 就是12位
- System.out.println(((timestamp - twepoch) << timestampLeftShift) //
- | (dataCenterId << dataCenterIdShift) //
- | (workerId << workerIdShift) //
- | sequence);
- return ((timestamp - twepoch) << timestampLeftShift) //
- | (dataCenterId << dataCenterIdShift) //
- | (workerId << workerIdShift) //
- | sequence;
- }
- /**
- * 阻塞到下一个毫秒,直到获得新的时间戳
- * @param lastTimestamp 上次生成ID的时间截
- * @return 当前时间戳
- */
- protected long tilNextMillis(long lastTimestamp) {
- long timestamp = timeGen();
- while (timestamp <= lastTimestamp) {
- timestamp = timeGen();
- }
- return timestamp;
- }
- /**
- * 返回以毫秒为单位的当前时间
- * @return 当前时间(毫秒)
- */
- protected long timeGen() {
- return System.currentTimeMillis();
- }
- // ==============================Test=============================================
- /** 测试 */
- public static void main(String[] args) {
- System.out.println(System.currentTimeMillis());
- SnowflakeIdWorker idWorker = new SnowflakeIdWorker(1, 1);
- long startTime = System.nanoTime();
- for (int i = 0; i < 50000; i++) {
- long id = idWorker.nextId();
- System.out.println(id);
- }
- System.out.println((System.nanoTime() - startTime) / 1000000 + "ms");
- }
- }
因为机器的原因会发生时间回拨,我们的雪花算法是强依赖我们的时间的,如果时间发生回拨,有可能会生成重复的ID
普通的算法会直接抛出异常,这里我们可以对其进行优化,一般分为两个情况:
如果时间回拨时间较短,比如配置5ms以内,那么可以直接等待一定的时间,让机器的时间追上来。
如果时间的回拨时间较长,我们不能接受这么长的阻塞等待,那么又有两个策略:
直接拒绝,抛出异常,打日志,通知RD时钟回滚。
利用扩展位,上面我们讨论过不同业务场景位数可能用不到那么多,那么我们可以把扩展位数利用起来了,比如当这个时间回拨比较长的时候,我们可以不需要等待,直接在扩展位加1。2位的扩展位允许我们有3次大的时钟回拨,一般来说就够了,如果其超过三次我们还是选择抛出异常,打日志。
ID 生成器 雪花算法的更多相关文章
- 唯一ID生成器--雪花算法
在微服务架构,分布式系统中的操作会有一些全局性ID的需求,所以我们不能用数据库本身的自增功能来产生主键值,只能由程序来生成唯一的主键值.我们采用的是twitter的snokeflake(雪花)算法. ...
- 生成主键ID,唯一键id,分布式ID生成器雪花算法代码实现
工具类: package com.ihrm.common.utils; import java.lang.management.ManagementFactory; import java.net. ...
- ID生成 雪花算法
/** * ID生成 雪花算法 */ public class SnowFlake { public static SnowFlake getInstance() { return Singleton ...
- 分布式ID的雪花算法及坑
分布式ID生成是目前系统的常见刚需,其中以Twitter的雪花算法(Snowflake)比较知名,有Java等各种语言的版本及各种改进版本,能生成满足分布式ID,返回ID为Long长整数 但是这里有一 ...
- 全局ID生成--雪花算法
分布式ID常见生成策略: 分布式ID生成策略常见的有如下几种: 数据库自增ID. UUID生成. Redis的原子自增方式. 数据库水平拆分,设置初始值和相同的自增步长. 批量申请自增ID. 雪花算法 ...
- 适用于分布式ID的雪花算法
基于Java实现的适用于分布式ID的雪花算法工具类,这里存一下日后好找 /** * 雪花算法生成ID */ public class SnowFlakeUtil { private final sta ...
- 分布式ID生成 - 雪花算法
雪花算法是一种生成分布式全局唯一ID的经典算法,关于雪花算法的解读网上多如牛毛,大多抄来抄去,这里请参考耕耘的小象大神的博客ID生成器,Twitter的雪花算法(Java) 网上的教程一般存在两个问题 ...
- 生成ID之雪花算法
package com.shopping.test; /** * SnowFlake的结构如下(每部分用-分开):<br> * 0 - 0000000000 0000000000 0000 ...
- 全局ID生成--雪花算法改进版
存在的问题 时间回拨问题:由于机器的时间是动态的调整的,有可能会出现时间跑到之前几毫秒,如果这个时候获取到了这种时间,则会出现数据重复 机器id分配及回收问题:目前机器id需要每台机器不一样,这样的方 ...
随机推荐
- 前端特效demo | 值得收藏的6个 HTML5 Canvas 实用案例
HTML5 动画在Canvas 上得到了充分的发挥,我们 VIP 视频也分享过很多相关的动画特效制作视频,这次给大家带来 6 款超炫酷的HTML5 canvas 动画的 demo,一起来看看吧~ 文内 ...
- Python03(Linux和Python简介)
Trainning-day02回顾1.rmdir : 删除空文件夹2.rm :删除文件或者文件夹 -r 删除目录以及其内容 -i 删除前的提示 -f 强制删除3.通配符 * 匹配任意多个任意字符 ?匹 ...
- js中bind的用法,及与call和apply的区别
call和apply的使用和区别不再做阐述,可以参考我的另一篇随笔<JavaScript中call和apply方法的使用>(https://www.cnblogs.com/lcr-smg/ ...
- [转载] java多线程总结(一)
转载自:http://www.cnblogs.com/lwbqqyumidi/p/3804883.html 作者:Windstep 多线程作为Java中很重要的一个知识点,在此还是有必要总结一下的. ...
- 安装mysql5.5遇到的狗屁问题,最后还是细心一下就好
首先巩固下自己已经遗忘了一年的Mysql数据库和navicat可视化数据库,安装数据库没有具体要求直接点下一步就好,我第一次安装提示服务器名无效,后来发现了原因,mysql服务压根没有启动,也就是更直 ...
- Python 语法1
函数的定义: """ def 函数名(): 函数内容,函数内容, 函数内容,函数内容, """ ////////////////////// ...
- 关于cordova+vue打包apk文件无法访问数据接口
作为一个cordova小白,我按照官方文档和网上资料完成了讲vue文件打包到cordova中并打包成apk文件,完成了一个简单app的制作,当我正陶醉于可以自己完成一个app的时候突然发现,我的app ...
- python第一条代码
#!usr/bin/env python #-*-coding:utf-8 -*- print("hello,world")
- 聊一聊 redux 异步流之 redux-saga
让我惊讶的是,redux-saga 的作者竟然是一名金融出身的在一家房地产公司工作的员工(让我想到了阮老师...),但是他对写代码有着非常浓厚的热忱,喜欢学习和挑战新的事物,并探索新的想法.恩,牛逼的 ...
- windows下配置maven
首先下载好maven的压缩包,然后解压到某个目录下,我解压到了D盘 打开readme.txt 1.2步已经完成,第3步的意思是让我们把bin所在的路径添加到系统变量的path中去 第4步意思是确保的你 ...