Python——正则表达式初步应用(一)
1、先附上转载(www.cnblogs.com/huxi)的一张图,有重要的参考价值,其含义大家请通过阅读来理解。
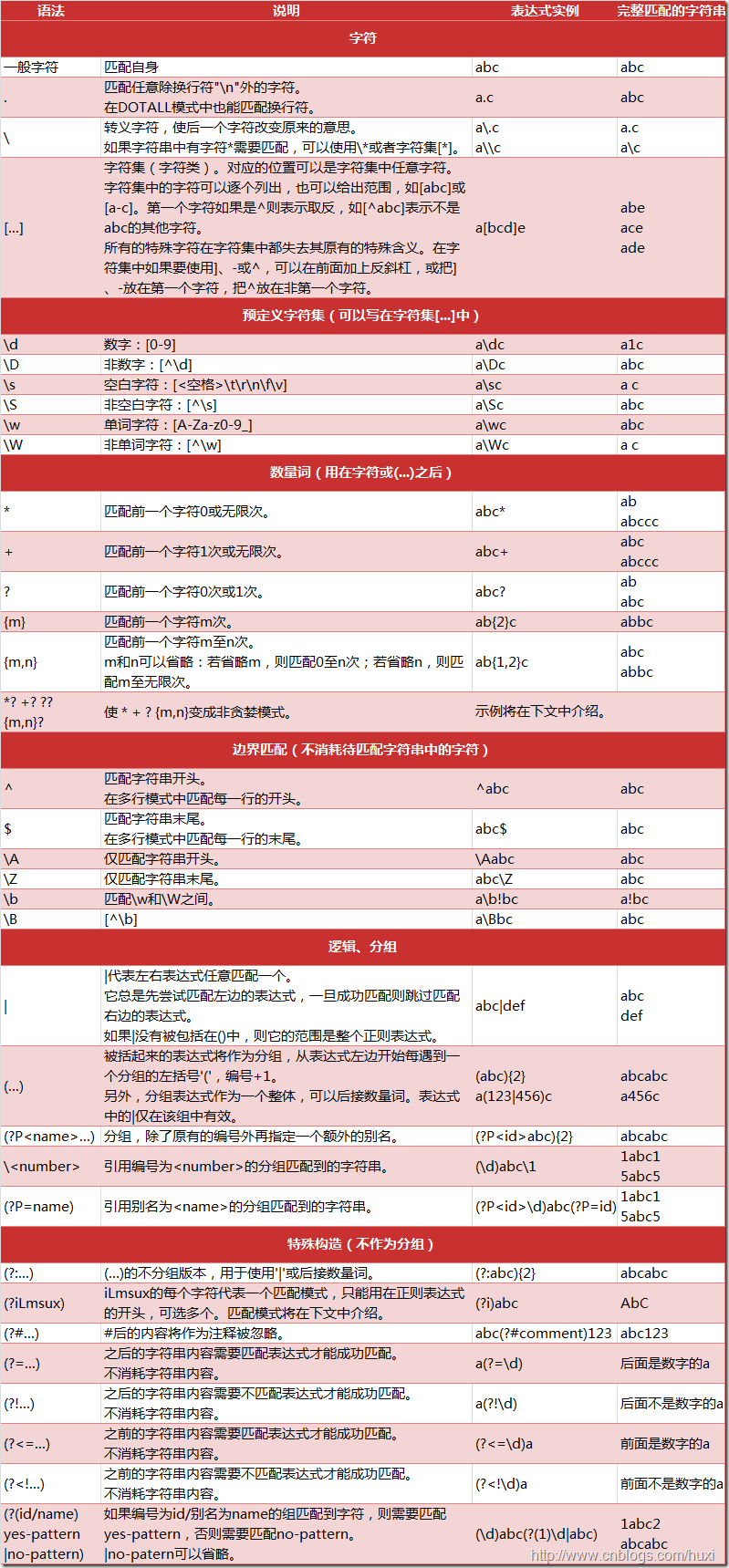
2、附上初步学习Python时编写的一个爬糗事百科段子的代码。
# -*- coding: utf-8 -*-
import urllib
import urllib.request
import re
import os
from os import makedirs if __name__ == '__main__':
print('Start getting data...')
for i in range(1,13):
url = 'https://www.qiushibaike.com/text/page/'+str(i)+'/'
#url = 'https://www.qiushibaike.com/text/page/1/'
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36 QIHU 360SE'
headers = {'User-Agent':user_agent}
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
#print(response)
content = response.read()
content = content.decode('utf8')
#print(content) last step proves to be necessary
'''这里是本片内容表述的重点'''
patternArticleNum =re.compile('(?<=<a href="/article/)[1-9][0-9]{7,}(?=" target=")',re.S)
patternArticle =re.compile('<div class="content">\s<span>(.*?)\s</span>',re.S)
#print(re.findall(pattern,content))
itemsArticleNum = re.findall(patternArticleNum,content)
lenItemsArticleNum =len(itemsArticleNum)
#print(lenItemsArticleNum)
itemsArticle = re.findall(patternArticle,content)
#itemsArticle = itemsArticle.encode('utf8')
#lenItemsArticle = len(itemsArticle)
#print(lenItemsArticle)
#items = re.split(pattern,content)
#print(items) type(item)=tuple
#print(itemsArticleNum[0])
print(itemsArticle)
path = 'qiubai'
if not os.path.exists(path):
os.makedirs(path)
while lenItemsArticleNum > -1:
lenItemsArticleNum = lenItemsArticleNum - 1
file_path = path + '/' + itemsArticleNum[lenItemsArticleNum]+ '.txt'
f = open(file_path,'w')
itemsArticle[lenItemsArticleNum] = itemsArticle[lenItemsArticleNum].replace('\n','').replace('<br/>','').replace('\u261e','') .replace('\u261c','').replace('\u0ca5','').replace('\ufffc','').replace('\u26bd','').replace('\uff78','').replace('\uff9e','').replace('\uff6f','')
#itemsArticle[lenItemsArticleNum] = str(str(itemsArticle[lenItemsArticleNum]).encode('gb2312')
f.write(itemsArticle[lenItemsArticleNum])
f.close()
#file_path = path + '/' + item[0]+ '.txt'
#for itemArticle in itemsArticle:
# print(itemsArticle)
print('Data acquireing compnished...')
3、查看网页源代码,发现我们所需要的内容具备如下的结构:
<a href="/article/119488591" target="_blank" class="contentHerf" onclick="_hmt.push(['_trackEvent','web-list-content','chick'])">
<div class="content">
<span> 今天看见的新闻:古有凿壁偷光,今有男子凿壁偷窥。杭州闸弄口派出所接到一名年轻姑娘报警,称隔壁男子在墙上挖了一个洞偷窥她。据民警介绍,男子自己交代,他是看到姑娘后起了歹念,洞是用手抠出来的…… </span> </div>
标黄的使我们关注的两部分内容,一是文章编号,提取后名为文本文件名称,二是段子内容,为文本文件内容。
4、如何提取文章编号:
patternArticleNum =re.compile('(?<=<a href="/article/)[1-9][0-9]{7,}(?=" target=")',re.S)
(?<=<a href="/article/):筛选前缀包含:<a href="/article的文本
[1-9][0-9]{7,} 筛选第一位是1-9,第二位是0-9,的,九位数及以上数字。{7,}表示匹配前一个字符7次及以上。
(?=" target=") 筛选后缀包含" target="的文本内容。
5、如何提取段子文本
<div class="content">\s<span>(.*?)\s</span>
<div class="content">\s<span> 筛选前缀包含<div class="content">\s<span>的文本,\s代表空白字符。
\s</span> 筛选后缀包含\s</span>的文本,
(.*?) 代表两者之间的所有字符,要用()括起来。
6、提取的公式
patternArticleNum =re.compile('(?<=<a href="/article/)[1-9][0-9]{7,}(?=" target=")',re.S)
itemsArticleNum = re.findall(patternArticleNum,content)
patternArticle =re.compile('<div class="content">\s<span>(.*?)\s</span>',re.S)
itemsArticle = re.findall(patternArticle,content)
需要调用re库,使用compile和正则表达式生成所需的pattern,利用re.findall在content内容里面匹配并读取出来。
备注1:content的获得:
(1)、根据Headers和User Agenturllib.request.Request()设置一个request。
(2)、用urllib.request.urlopen()根据这个request生成一个response。
(3)、最后用response.read()读取出来。
备注2:Python3.6中取消了urllib2,取而代之是自带的urllib.request。
Python——正则表达式初步应用(一)的更多相关文章
- 比较详细Python正则表达式操作指南(re使用)
比较详细Python正则表达式操作指南(re使用) Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式.Python 1.5之前版本则是通过 regex 模块提供 E ...
- Python 正则表达式入门(中级篇)
Python 正则表达式入门(中级篇) 初级篇链接:http://www.cnblogs.com/chuxiuhong/p/5885073.html 上一篇我们说在这一篇里,我们会介绍子表达式,向前向 ...
- Python正则表达式中的re.S
title: Python正则表达式中的re.S date: 2014-12-21 09:55:54 categories: [Python] tags: [正则表达式,python] --- 在Py ...
- Python 正则表达式入门(初级篇)
Python 正则表达式入门(初级篇) 本文主要为没有使用正则表达式经验的新手入门所写. 转载请写明出处 引子 首先说 正则表达式是什么? 正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达 ...
- python正则表达式re
Python正则表达式: re 正则表达式的元字符有. ^ $ * ? { [ ] | ( ).表示任意字符[]用来匹配一个指定的字符类别,所谓的字符类别就是你想匹配的一个字符集,对于字符集中的字符可 ...
- Python正则表达式详解
我用双手成就你的梦想 python正则表达式 ^ 匹配开始 $ 匹配行尾 . 匹配出换行符以外的任何单个字符,使用-m选项允许其匹配换行符也是如此 [...] 匹配括号内任何当个字符(也有或的意思) ...
- Python正则表达式学习摘要及资料
摘要 在正则表达式中,如果直接给出字符,就是精确匹配. {m,n}? 对于前一个字符重复 m 到 n 次,并且取尽可能少的情况 在字符串'aaaaaa'中,a{2,4} 会匹配 4 个 a,但 a{2 ...
- python正则表达式 小例几则
会用到的语法 正则字符 释义 举例 + 前面元素至少出现一次 ab+:ab.abbbb 等 * 前面元素出现0次或多次 ab*:a.ab.abb 等 ? 匹配前面的一次或0次 Ab?: A.Ab 等 ...
- Python 正则表达式-OK
Python正则表达式入门 一. 正则表达式基础 1.1. 简单介绍 正则表达式并不是Python的一部分. 正则表达式是用于处理字符串的强大工具, 拥有自己独特的语法以及一个独立的处理引擎, 效率上 ...
随机推荐
- ORACLE 查询某表中的某个字段的类型,是否为空,是否有默认值等
最近写的功能中有这样一个小功能,根据数据库查询此库中是否有某表,如果有,查询某表下面的某个字段的详细信息 其中一种是... select ATC.OWNER, atC.TABLE_NAME, ATC. ...
- composer包(发布到github上)同步到Packagist
在上一篇文章里面,探讨了如何一步步建立composer包–创建你的一个composer包 创建完成后,我们需要做的就是讲自建的包发布到Packagist上.至于说什么是Packagist,这个就不用我 ...
- 解决CSDN需要登录才能看全文
本来今天学习遇到一些问题,在网上翻着博客,突然在csdn里就提示要登录才能看全文. 看了下页面源码博客内容已经拿到本地了,只是加了一层罩,也是挺无语的,暂时先用这种方法解决吧: (function() ...
- SQL COUNT() 函数
COUNT() 函数返回匹配指定条件的行数. SQL COUNT() 语法 SQL COUNT(column_name) 语法 COUNT(column_name) 函数返回指定列的值的数目(NULL ...
- 好程序员web前端分享12个CSS高级技巧汇总
好程序员web前端分享下面这些CSS高级技巧,一般人我可不告诉他哦. 使用 :not() 在菜单上应用/取消应用边框 给body添加行高 所有一切都垂直居中 逗号分隔的列表 使用负的 nth-chil ...
- Ubuntu 14.04 下使用微软的跨平台轻量级开发神器 Visual Studio Code
因为 Visual Studio Code 不断更新,官方最新 v1.32 的 .deb 包已经不能用于 Ubuntu 14.04 直接安装了. 下载 v1.31 的 deb 包安装即可:https: ...
- VSC 解决红底线问题
话不多说 设置里代码奉上 { "editor.minimap.enabled": false, "workbench.iconTheme": "vs ...
- 转载:教你分分钟搞定Docker私有仓库Registry
一.什么是Docker私有仓库Registry 官方的Docker hub是一个用于管理公共镜像的好地方,我们可以在上面找到我们想要的镜像,也可以把我们自己的镜像推送上去.但是,有时候我们的服务器无法 ...
- vue nextTick使用
Vue nextTick使用 vue生命周期 原因是在created()钩子函数执行的时候DOM 其实并未进行任何渲染,而此时进行DOM操作无异于徒劳,所以此处一定要将DOM操作的js代码放进Vue. ...
- uniApp——v-for 动态class、动态style
:class="i.themColor" <view v-for="i in htmlJSON" class="column" :c ...