OpenCV中的KNN
一、K近邻
有两个类,红色、蓝色。我将红色点标记为0,蓝色点标记为1。还要创建25个训练数据,把它们分别标记为0或者1。Numpy中随机数产生器可以帮助我们完成这个任务
import cv2
import numpy as np
import matplotlib.pyplot as plt # 包含25个已知/训练数据的(x,y)值的特征集
trainData = np.random.randint(, , (, )).astype(np.float32) # 用数字0和1分别标记红色和蓝色
responses = np.random.randint(, , (, )).astype(np.float32) # 画出红色的点
red = trainData[responses.ravel() == ]
plt.scatter(red[:, ], red[:, ], , 'r', '^') # 画出蓝色的点
blue = trainData[responses.ravel() == ]
plt.scatter(blue[:, ], blue[:, ], , 'b', 's') plt.show()
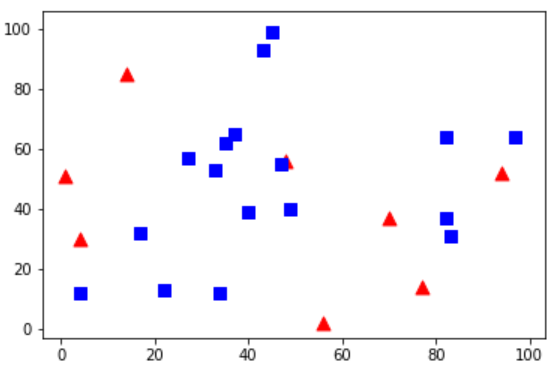
很有可能你运行的图和我的不一样,因为使用了随机数产生器,每次运行代码都会得到不同的结果。
下面就是KNN算法分类器的初始化,我们要传入一个训练数据集,以及对应的label。我们给它一个测试数据,让它来进行分类。OpenCV中使用knn.findNearest()函数
参数1:测试数据
参数2:k的值
返回值1:由kNN算法计算得到的测试数据的类别标志(0 或 1)。如果你想使用最近邻算法,只需要将k设置1,k就是最近邻的数目
返回值2:k的最近邻居的类别标志
返回值3:每个最近邻居到测试数据的距离
测试数据被标记为绿色。
# newcomer为测试数据
newcomer = np.random.randint(, , (, )).astype(np.float32)
plt.scatter(newcomer[:,],newcomer[:,],,'g','o') knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
ret, results, neighbours, dist = knn.findNearest(newcomer, ) print("result: ", results, "\n")
print("neighbours: ", neighbours,"\n")
print("distance: ", dist) plt.scatter(red[:, ], red[:, ], , 'r', '^')
plt.scatter(blue[:, ], blue[:, ], , 'b', 's') plt.show()
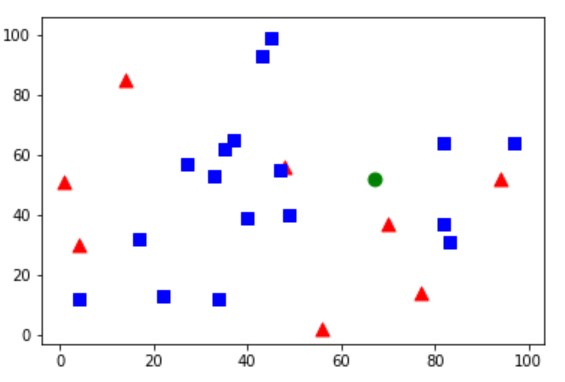
下面是我得到的结果:
result: [[.]] neighbours: [[. . .]] distance: [[. . .]]
测试数据有三个邻居,有两个是红色,一个是蓝色。因此测试数据被分为红色。
二、使用kNN对手写数字OCR
OCR(Optical Character Recognition,光学字符识别)
目标
1. 要根据我们掌握的kNN知识创建一个基本的OCR程序
2. 使用OpenCV自带的手写数字和字母数据测试我们的程序
手写数字的OCR
我们的目的是创建一个可以对手写数字进行识别的程序。需要训练数据和测试数据。OpenCV 安装包中有一副图片(/samples/python2/data/digits.png),其中有一幅有5000个手写数字(每个数字重复500遍)。每个数字是一个20x20的小图。所以第一步就是将这个图像分割成5000个不同的数字,将拆分后的每一个数字图像展成400个像素点的图像(1x400的一维向量)。这个就是我们的特征集,所有像素的灰度值。我们使用每个数字的前250个样本做训练数据,剩余的250个做测试数据。
import numpy as np
import cv2
import matplotlib.pyplot as plt img = cv2.imread('digits.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 我们把图片分成5000张,每张20 x
cells = [np.hsplit(row, ) for row in np.vsplit(gray, )] # 使cells变成一个numpy数组,它的维度为(, , , )
x = np.array(cells) # 训练数据和测试数据
train = x[:, :].reshape(-, ).astype(np.float32) # size = (, )
test = x[:, :].reshape(-, ).astype(np.float32) # size = (, ) # 为训练集和测试集创建一个label
k = np.arange()
train_labels = np.repeat(k, )[:, np.newaxis]
test_labels = train_labels.copy() # 初始化KNN,训练数据、测试KNN,k=
knn = cv2.ml.KNearest_create()
knn.train(train, cv2.ml.ROW_SAMPLE, train_labels)
ret, result, neighbours, dist = knn.findNearest(test, k=) # 分类的准确率
# 比较结果和test_labels
matches = result==test_labels
correct = np.count_nonzero(matches)
accuracy = correct * 100.0 / result.size
print(accuracy)
结果为:
91.76
为了避免每次运行程序都要准备和训练分类器,我们最好把它保留,这样在下次运行时,只需要从文件中读取这些数据开始进行分类就可以了。
# 保留数据
np.savez('knn_data.npz', train=train, train_labels=train_labels) # 加载数据
with np.load('knn_data.npz') as data:
print(data.files)
train = data['train']
train_labels = data['train_labels']
结果为:
['train', 'train_labels']
英文字母的OCR
接下来我们来做英文字母的OCR。和上面做法一样,但是数据和特征集有一些不同。OpenCV自带的数据文件(/samples/cpp/letter-recognition.data)。有20000行,每一行的第一列是我们的一个字母标记,接下来的16个数字是它的不同特征。取前10000个作为训练样本,剩下的10000个作为测试样本。我们先把字母表换成ascII,因为我们不直接处理字母。
data = np.loadtxt('letter-recognition.data', dtype='float32', delimiter=',', converters={:lambda ch:ord(ch) - ord('A')})
# 将数据分成2份,10000个训练,10000个测试
train, test = np.vsplit(data, )
# 将训练集和测试集分解为数据、label
# 实际上每一行的第一列是我们的一个字母标记。接下来的 个数字是它的不同特征。
responses, trainData = np.hsplit(train, []) # 数据从第二列开始
labels, testData = np.hsplit(test, [])
# 初始化KNN,训练数据、测试KNN,k=
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
ret, result, neighbours, dist = knn.findNearest(testData, k=)
# 分类的准确率
# 比较结果和test_labels
correct = np.count_nonzero(result==labels)
accuracy = correct * 100.0 / result.size
print(accuracy)
结果为:
93.06
OpenCV中的KNN的更多相关文章
- [OpenCV-Python] OpenCV 中机器学习 部分 VIII
部分 VIII机器学习 OpenCV-Python 中文教程(搬运)目录 46 K 近邻(k-Nearest Neighbour ) 46.1 理解 K 近邻目标 • 本节我们要理解 k 近邻(kNN ...
- Opencv中KNN背景分割器
背景分割器BackgroundSubtractor是专门用来视频分析的,会对视频中的每一帧进行"学习",比较,计算阴影,排除检测图像的阴影区域,按照时间推移的方法提高运动分析的结果 ...
- opencv中Mat与IplImage,CVMat类型之间转换
opencv中对图像的处理是最基本的操作,一般的图像类型为IplImage类型,但是当我们对图像进行处理的时候,多数都是对像素矩阵进行处理,所以这三个类型之间的转换会对我们的工作带来便利. Mat类型 ...
- 解析opencv中Box Filter的实现并提出进一步加速的方案(源码共享)。
说明:本文所有算法的涉及到的优化均指在PC上进行的,对于其他构架是否合适未知,请自行试验. Box Filter,最经典的一种领域操作,在无数的场合中都有着广泛的应用,作为一个很基础的函数,其性能的好 ...
- OpenCV中IplImage图像格式与BYTE图像数据的转换
最近在将Karlsruhe Institute of Technology的Andreas Geiger发表在ACCV2010上的Efficent Large-Scale Stereo Matchin ...
- opencv中的SIFT,SURF,ORB,FAST 特征描叙算子比较
opencv中的SIFT,SURF,ORB,FAST 特征描叙算子比较 参考: http://wenku.baidu.com/link?url=1aDYAJBCrrK-uk2w3sSNai7h52x_ ...
- 混合高斯模型:opencv中MOG2的代码结构梳理
/* 头文件:OurGaussmix2.h */ #include "opencv2/core/core.hpp" #include <list> #include&q ...
- opencv中的.at方法
opencv中的.at方法是用来获取图像像素值得函数: interpolation:差值 histogram:直方图
- 【OpenCV】OpenCV中GPU模块使用
CUDA基本使用方法 在介绍OpenCV中GPU模块使用之前,先回顾下CUDA的一般使用方法,其基本步骤如下: 1.主机代码执行:2.传输数据到GPU:3.确定grid,block大小: 4.调用内核 ...
随机推荐
- bs4模块
1.导入模块 from bs4 import BeautifulSoup 2.创建对象 Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它 ...
- 文本编辑利器Notepad++ 10个强大而又鲜为人知的特性【转】
文本编辑利器Notepad++ 10个强大而又鲜为人知的特性 - 为程序员服务
- python将PNG格式的图片转化成为jpg
""" 先来说一下jpg图片和png图片的区别 jpg格式:是有损图片压缩类型,可用最少的磁盘空间得到较好的图像质量 png格式:不是压缩性,能保存透明等图 " ...
- 【dp】P2642 双子序列最大和
题目描述 给定一个长度为n的整数序列,要求从中选出两个连续子序列,使得这两个连续子序列的序列和之和最大,最终只需输出最大和.一个连续子序列的和为该子序列中所有数之和.每个连续子序列的最小长度为1,并且 ...
- 20165223《网络对抗技术》Exp5 MSF基础应用
目录 -- MSF基础应用 实验说明 实验任务内容 基础问题回答 实验内容 主动攻击 ms17_10_eternalblue(成功) ms17_10_psexec(成功) ms08_067_netap ...
- logback输出json格式日志(包括mdc)发送到kafka
1,pom.xml <!-- kafka --> <dependency> <groupId>com.github.danielwegener</groupI ...
- 第六周java学习总结
学号 20175206 <Java程序设计>第六周学习总结 教材学习内容总结 第七章: 主要内容 内部类 匿名类 异常类 断言 重点和难点 重点:内部类和异常类的理解 难点:异常类的使用 ...
- EasyUI + ajax + treegrid/datagrid 接收 json 数据,显示树状/网状表结构
最后一更了,时间间隔有点久了~~ EasyUI作为一个成熟的前端框架,封装了ajax,对于数据的处理配合datagrid组件的使用,使其非常适合后台管理界面的开发(目前来说界面有点过时了). 通过aj ...
- minikube是什么
最近在学习Kubernetes,需要再本地搭建换一个minikube的环境 搭建好之后我们查看节点: lideMacBook-Pro:~ liyuanhong$ kubectl get node NA ...
- django环境部署 crm和路飞学城
环境依赖 yum install gcc patch libffi-devel python-devel zlib-devel bzip2-devel openssl-devel ncurses-de ...