OpenCV中的KNN
一、K近邻
有两个类,红色、蓝色。我将红色点标记为0,蓝色点标记为1。还要创建25个训练数据,把它们分别标记为0或者1。Numpy中随机数产生器可以帮助我们完成这个任务
import cv2
import numpy as np
import matplotlib.pyplot as plt # 包含25个已知/训练数据的(x,y)值的特征集
trainData = np.random.randint(, , (, )).astype(np.float32) # 用数字0和1分别标记红色和蓝色
responses = np.random.randint(, , (, )).astype(np.float32) # 画出红色的点
red = trainData[responses.ravel() == ]
plt.scatter(red[:, ], red[:, ], , 'r', '^') # 画出蓝色的点
blue = trainData[responses.ravel() == ]
plt.scatter(blue[:, ], blue[:, ], , 'b', 's') plt.show()
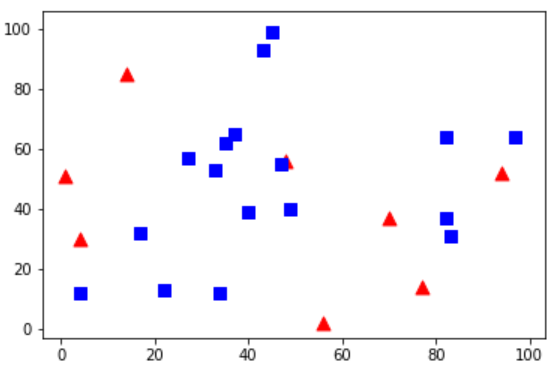
很有可能你运行的图和我的不一样,因为使用了随机数产生器,每次运行代码都会得到不同的结果。
下面就是KNN算法分类器的初始化,我们要传入一个训练数据集,以及对应的label。我们给它一个测试数据,让它来进行分类。OpenCV中使用knn.findNearest()函数
参数1:测试数据
参数2:k的值
返回值1:由kNN算法计算得到的测试数据的类别标志(0 或 1)。如果你想使用最近邻算法,只需要将k设置1,k就是最近邻的数目
返回值2:k的最近邻居的类别标志
返回值3:每个最近邻居到测试数据的距离
测试数据被标记为绿色。
# newcomer为测试数据
newcomer = np.random.randint(, , (, )).astype(np.float32)
plt.scatter(newcomer[:,],newcomer[:,],,'g','o') knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
ret, results, neighbours, dist = knn.findNearest(newcomer, ) print("result: ", results, "\n")
print("neighbours: ", neighbours,"\n")
print("distance: ", dist) plt.scatter(red[:, ], red[:, ], , 'r', '^')
plt.scatter(blue[:, ], blue[:, ], , 'b', 's') plt.show()
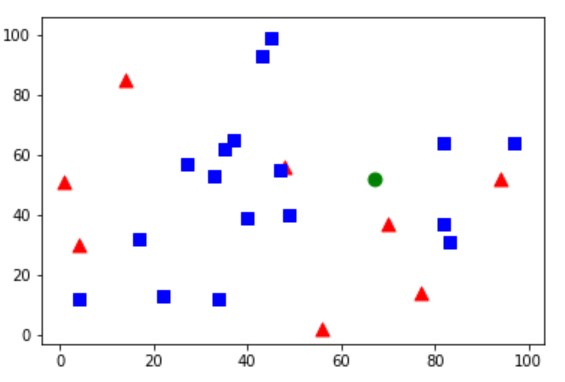
下面是我得到的结果:
result: [[.]] neighbours: [[. . .]] distance: [[. . .]]
测试数据有三个邻居,有两个是红色,一个是蓝色。因此测试数据被分为红色。
二、使用kNN对手写数字OCR
OCR(Optical Character Recognition,光学字符识别)
目标
1. 要根据我们掌握的kNN知识创建一个基本的OCR程序
2. 使用OpenCV自带的手写数字和字母数据测试我们的程序
手写数字的OCR
我们的目的是创建一个可以对手写数字进行识别的程序。需要训练数据和测试数据。OpenCV 安装包中有一副图片(/samples/python2/data/digits.png),其中有一幅有5000个手写数字(每个数字重复500遍)。每个数字是一个20x20的小图。所以第一步就是将这个图像分割成5000个不同的数字,将拆分后的每一个数字图像展成400个像素点的图像(1x400的一维向量)。这个就是我们的特征集,所有像素的灰度值。我们使用每个数字的前250个样本做训练数据,剩余的250个做测试数据。
import numpy as np
import cv2
import matplotlib.pyplot as plt img = cv2.imread('digits.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 我们把图片分成5000张,每张20 x
cells = [np.hsplit(row, ) for row in np.vsplit(gray, )] # 使cells变成一个numpy数组,它的维度为(, , , )
x = np.array(cells) # 训练数据和测试数据
train = x[:, :].reshape(-, ).astype(np.float32) # size = (, )
test = x[:, :].reshape(-, ).astype(np.float32) # size = (, ) # 为训练集和测试集创建一个label
k = np.arange()
train_labels = np.repeat(k, )[:, np.newaxis]
test_labels = train_labels.copy() # 初始化KNN,训练数据、测试KNN,k=
knn = cv2.ml.KNearest_create()
knn.train(train, cv2.ml.ROW_SAMPLE, train_labels)
ret, result, neighbours, dist = knn.findNearest(test, k=) # 分类的准确率
# 比较结果和test_labels
matches = result==test_labels
correct = np.count_nonzero(matches)
accuracy = correct * 100.0 / result.size
print(accuracy)
结果为:
91.76
为了避免每次运行程序都要准备和训练分类器,我们最好把它保留,这样在下次运行时,只需要从文件中读取这些数据开始进行分类就可以了。
# 保留数据
np.savez('knn_data.npz', train=train, train_labels=train_labels) # 加载数据
with np.load('knn_data.npz') as data:
print(data.files)
train = data['train']
train_labels = data['train_labels']
结果为:
['train', 'train_labels']
英文字母的OCR
接下来我们来做英文字母的OCR。和上面做法一样,但是数据和特征集有一些不同。OpenCV自带的数据文件(/samples/cpp/letter-recognition.data)。有20000行,每一行的第一列是我们的一个字母标记,接下来的16个数字是它的不同特征。取前10000个作为训练样本,剩下的10000个作为测试样本。我们先把字母表换成ascII,因为我们不直接处理字母。
data = np.loadtxt('letter-recognition.data', dtype='float32', delimiter=',', converters={:lambda ch:ord(ch) - ord('A')})
# 将数据分成2份,10000个训练,10000个测试
train, test = np.vsplit(data, )
# 将训练集和测试集分解为数据、label
# 实际上每一行的第一列是我们的一个字母标记。接下来的 个数字是它的不同特征。
responses, trainData = np.hsplit(train, []) # 数据从第二列开始
labels, testData = np.hsplit(test, [])
# 初始化KNN,训练数据、测试KNN,k=
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
ret, result, neighbours, dist = knn.findNearest(testData, k=)
# 分类的准确率
# 比较结果和test_labels
correct = np.count_nonzero(result==labels)
accuracy = correct * 100.0 / result.size
print(accuracy)
结果为:
93.06
OpenCV中的KNN的更多相关文章
- [OpenCV-Python] OpenCV 中机器学习 部分 VIII
部分 VIII机器学习 OpenCV-Python 中文教程(搬运)目录 46 K 近邻(k-Nearest Neighbour ) 46.1 理解 K 近邻目标 • 本节我们要理解 k 近邻(kNN ...
- Opencv中KNN背景分割器
背景分割器BackgroundSubtractor是专门用来视频分析的,会对视频中的每一帧进行"学习",比较,计算阴影,排除检测图像的阴影区域,按照时间推移的方法提高运动分析的结果 ...
- opencv中Mat与IplImage,CVMat类型之间转换
opencv中对图像的处理是最基本的操作,一般的图像类型为IplImage类型,但是当我们对图像进行处理的时候,多数都是对像素矩阵进行处理,所以这三个类型之间的转换会对我们的工作带来便利. Mat类型 ...
- 解析opencv中Box Filter的实现并提出进一步加速的方案(源码共享)。
说明:本文所有算法的涉及到的优化均指在PC上进行的,对于其他构架是否合适未知,请自行试验. Box Filter,最经典的一种领域操作,在无数的场合中都有着广泛的应用,作为一个很基础的函数,其性能的好 ...
- OpenCV中IplImage图像格式与BYTE图像数据的转换
最近在将Karlsruhe Institute of Technology的Andreas Geiger发表在ACCV2010上的Efficent Large-Scale Stereo Matchin ...
- opencv中的SIFT,SURF,ORB,FAST 特征描叙算子比较
opencv中的SIFT,SURF,ORB,FAST 特征描叙算子比较 参考: http://wenku.baidu.com/link?url=1aDYAJBCrrK-uk2w3sSNai7h52x_ ...
- 混合高斯模型:opencv中MOG2的代码结构梳理
/* 头文件:OurGaussmix2.h */ #include "opencv2/core/core.hpp" #include <list> #include&q ...
- opencv中的.at方法
opencv中的.at方法是用来获取图像像素值得函数: interpolation:差值 histogram:直方图
- 【OpenCV】OpenCV中GPU模块使用
CUDA基本使用方法 在介绍OpenCV中GPU模块使用之前,先回顾下CUDA的一般使用方法,其基本步骤如下: 1.主机代码执行:2.传输数据到GPU:3.确定grid,block大小: 4.调用内核 ...
随机推荐
- HTML&CSS_基础01
一.预备知识: # 1. HTML5 是 W3C 与 WHATWG 合作的结果. W3C 指 World Wide Web Consortium,万维网联盟. WHATWG 指 Web H ...
- 洛谷 P4714 「数学」约数个数和 解题报告
P4714 「数学」约数个数和 题意(假):每个数向自己的约数连边,给出\(n,k(\le 10^{18})\),询问\(n\)的约数形成的图中以\(n\)为起点长为\(k\)的链有多少条(注意每个点 ...
- 观察者模式 vs 发布-订阅模式
我曾经在面试中被问道,_“观察者模式和发布订阅模式的有什么区别?” _我迅速回忆起“Head First设计模式”那本书: 发布 + 订阅 = 观察者模式 “我知道了,我知道了,别想骗我” 我微笑着回 ...
- ref、out参数
ref和out都是表示按引用传递.与指针类似,直接指向同一内存. 按值传递参数的方法永远不可能改变方法外的变量,需要改变方法外的变量就必须按引用传递参数. 传递参数的方法,在C语言里,用指针.在C#里 ...
- 04-oracle中的视图
1.创建视图 介绍: 视图(View)通过SELECT查询语句定义,它是从一个或多个表(或视图)导出的,用来导出视图的表称为基表(Base Table),导出的视图称为虚表.在数据库中,只存储视图的定 ...
- airflow 笔记
首先是一个比较好的英文网站,可能要fq:http://site.clairvoyantsoft.com/installing-and-configuring-apache-airflow/ ===== ...
- 状态模式-State Pattern(Java实现)
状态模式-State Pattern 在状态模式(State Pattern)中,类的行为是基于它的状态改变的.当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类. State接口 ...
- 备忘录模式-Memento Pattern(Java实现)
备忘录模式-Memento Pattern Memento备忘录设计模式是一个保存另外一个对象内部状态拷贝的对象,这样以后就可以将该对象恢复到以前保存的状态. 本文中的场景: 有一款游戏可以随时存档, ...
- IE7下使用兼容Icon-Font CSS类
Iconfont在IE7下需要使用unicode方式,但是这种方式不太方便,使用以下代码可使IE7像普通用法使用. @font-face {font-family: "anticon&quo ...
- UE4 行为树资料
Composites Select 选择 从左往右执行其子节点,直到一个达成,则 Select 达成并返回上层,否则失败并返回上层 Sequence 队列 从左往右执行其子节点,直到一个失败,则 Se ...