Spark大型电商项目实战-及其改良之番外(1)-将spark前端页面效果高效拷贝至博客
Spark大型电商项目实战-及其改良这个系列的时间轴展示图一直在变....1-3篇是用图直接表示时间轴,用一段简陋的html代码表示时间表.第4篇开始才是用比较完整的前端效果,能移动、缩放时间轴,鼠标移动到时间轴的stage,下方对应的stage时间表会高亮.
这是因为博客园的文章本质就是html标签集合组成的页面,如果能嵌入适当的css和js文件,也能得到想要的效果。
拿到运行时间表
先在服务器运行./start-history-server.sh开启历史服务器,之后就可以查看运行完毕的spark jobs页面
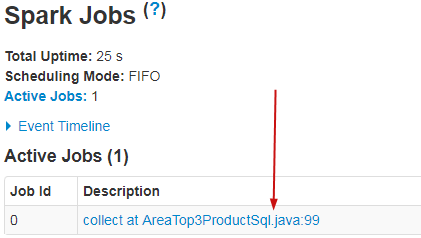
点击此处,进入job
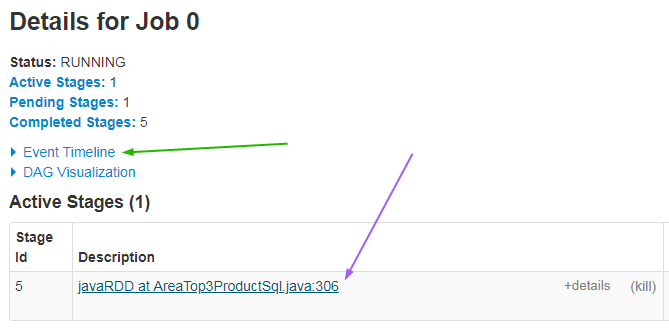
点击绿色箭头处打开时间轴,点击紫色箭头处查看stage的运行情况(不同executor的运行情况)
复制class为container-fluid的html元素及其内部,拼接进一篇博客作比对用
获得css
对应的js和css链接都要复制到这个html上。js在博客园后台申请下权限,就能在博文写js了,这些js文件的操作是对特定页面有效的,其他博文没有影响。嵌入页首页尾。
麻烦的是css,如果全部提取出来,文字量太大了,复制的样式出问题很难揪bug。
只能复制spark页面里面的css,可是这种页面的css规则太多太杂,很难单独提取
这时就要请万能的Python出场了.
import re
import cssselect
from lxml import etree def getAllStyle(filepath):
cssdict = []
alloof = ''
with open(filepath, 'r', encoding='utf-8') as r:
line = r.read().replace('\n ','').replace('\n ','').replace('\n','')
for stylestr in re.findall(r'[^}]+{[^}]+}', line):
if(filepath.find('spark-dag-viz.css') != -1):
print(stylestr)
csss = stylestr.split('{')
#cssdict[csss[0]] = '{' + csss[1]
cssdict.append(stylestr)
#
return cssdict
#
def getHtree(filepath):
alloof = ''
htree = None
with open(filepath, 'r', encoding='utf-8') as r:
htree = etree.HTML(r.read())
return htree
#
def getValidCss(filepath, csses):
htree = getHtree(filepath)
validCss = []
for css in csses:
getsplit = css.split('{')[0]
getyou = []
for acss in getsplit.split(','):
acss = acss.replace(':after','')\
.replace(':before','')\
.replace('::-moz-focus-inner','')\
.replace('::-webkit-search-cancel-button','')\
.replace(':-moz-placeholder','')\
.replace(':-ms-input-placeholder','')\
.replace('::-webkit-input-placeholder','')\
.replace(':invalid','')\
.replace('::-webkit-search-decoration','')
#acss = acss.split(':')[0]
if(acss.find('@') != -1):
getyou.append(1)
else:
getyou.extend(htree.cssselect(acss))
if(len(getyou) != 0):
validCss.append(css)
return validCss
#
def exportYou(filepath, validCss):
with open(filepath, 'w', encoding='utf-8') as w:
for val in validCss:
w.write(val + '\n')
#
if __name__ == '__main__':
cssfiles = ['C:/Users/Administrator/Documents/JobDetail_files/bootstrap.min.css',
'C:/Users/Administrator/Documents/JobDetail_files/vis.min.css',
'C:/Users/Administrator/Documents/JobDetail_files/webui.css',
'C:/Users/Administrator/Documents/JobDetail_files/timeline-view.css',
'C:/Users/Administrator/Documents/JobDetail_files/spark-dag-viz.css']
cssdict = []
for cssfile in cssfiles:
cssdict.extend(getAllStyle(cssfile))
validCss = getValidCss('C:/Users/Administrator/sparktimelime.html', cssdict)
exportYou('C:/Users/Administrator/sparkCss.html', validCss)
因为这5个css文件是spark前端要用的,从这里面提取出来css样式,再用lxml提取html标签树,用css选择器选择对应元素,如果存在就把css样式提取出来(注意带@和:号的,可能是pseudo),再一起写进html里面(博文正文可以嵌入style标签,但是不能嵌入script标签)
提取出css样式后,复制到最顶的style标签里面。再对style进行某些筛选,就可以让博文也能实现spark前端那种效果。
Spark大型电商项目实战-及其改良之番外(1)-将spark前端页面效果高效拷贝至博客的更多相关文章
- Spark大型电商项目实战-及其改良(3) 分析sparkSQL语句的性能影响
之前的运行数据被清除了,只能再运行一次,对比一下sparkSQL语句的影响 纯SQL的时间 对应时间表 th:first-child,.table-bordered tbody:first-child ...
- Spark大型电商项目实战-及其改良(1) 比对sparkSQL和纯RDD实现的结果
代码存在码云:https://coding.net/u/funcfans/p/sparkProject/git 代码主要学习https://blog.csdn.net/u012318074/artic ...
- Spark大型电商项目实战-及其改良(4) 单独运行程序发现的问题
之前的运行结果比对发现,有1个函数的作用在2个job里面是相同的,但是对应的计算时间却差太远 于是把4个job分开运行.虽说使用的数据不同,但是生成数据的生成器是相同的,数据排布差距不大,数据量也是相 ...
- Spark大型电商项目实战-及其改良(2) RDD优化效果不稳定的真正原因
首先看没有map join的第2任务: 时间线如下 接着是对应id的算子计算时间表 Stage Id Description Submitted Duration Tasks: Succeeded/T ...
- 16套java架构师,高并发,高可用,高性能,集群,大型分布式电商项目实战视频教程
16套Java架构师,集群,高可用,高可扩展,高性能,高并发,性能优化,设计模式,数据结构,虚拟机,微服务架构,日志分析,工作流,Jvm,Dubbo ,Spring boot,Spring cloud ...
- Java 18套JAVA企业级大型项目实战分布式架构高并发高可用微服务电商项目实战架构
Java 开发环境:idea https://www.jianshu.com/p/7a824fea1ce7 从无到有构建大型电商微服务架构三个阶段SpringBoot+SpringCloud+Solr ...
- SpringBoot电商项目实战 — ElasticSearch接入实现
如今在一些中大型网站中,搜索引擎已是必不可少的内容了.首先我们看看搜索引擎到底是什么呢?搜索引擎,就是根据用户需求与一定算法,运用特定策略从互联网检索出制定信息反馈给用户的一门检索技术.搜索引擎依托于 ...
- SpringBoot电商项目实战 — 前后端分离后的优雅部署及Nginx部署实现
在如今的SpringBoot微服务项目中,前后端分离已成为业界标准使用方式,通过使用nginx等代理方式有效的进行解耦,并且前后端分离会为以后的大型分布式架构.弹性计算架构.微服务架构.多端化服务(多 ...
- C# 大型电商项目性能优化(一)
经过几个月的忙碌,我厂最近的电商平台项目终于上线,期间遇到的问题以及解决方案,也可以拿来和大家多做交流了. 我厂的项目大多采用C#.net,使用逐渐发展并流行起来的EF(Entity Framewor ...
随机推荐
- linux定时备份mysql数据并同步到其他服务器
(备份还原操作) ###导出数据库 /usr/bin/mysqldump -u root -pwd database > database20180808.sql ###导入数据库 mysql ...
- HDU 6311 Cover (无向图最小路径覆盖)
HDU 6311 Cover (无向图最小路径覆盖) Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/ ...
- JS数组循环的性能和效率分析(for、while、forEach、map、for of)
从最简单的for循环说起 for( 初始化:条件; ){} 条件为Trusy 值时候,可以继续执行for 循环,当条件变为Falsy 时跳出for循环.for循环常见的四种写法const person ...
- 中国省份毗邻关系JSON数据[相邻省份][所辖市级信息][行政区划]
最近做一个需求, 需要一份每个省份相邻[毗邻]的省份信息,这里整理了一版. json 数据,结构大致这样子的. [ { "id": 7, "name": &qu ...
- [strongswan][autoconf][automake][cento] 在CentOS上编译strongswan git源码时遇到的autoconf问题
编译strongswan的git源码问题 1. 概述 首先,我们想要通过源码编译strongswan.当满足以下条件时,通常你会遇见此问题: 源码时通过git clone的得来的,而不是官网下载的源码 ...
- 【Mac】-NO.133.Mac.1 -【重置忘记macos root密码】
Style:Mac Series:Java Since:2018-09-10 End:2018-09-10 Total Hours:1 Degree Of Diffculty:5 Degree Of ...
- java的智能提示无法打开
第一步:选中“window”->“preference” 第二步:选中“java”,并展开 第三步:选中“Editor”,并展开 第四步:选中“Content Assist”,在右侧 ...
- 短信外部浏览器H5链接一键跳转微信打开任意站
今天讲讲微信跳转的那些事情,这项技术最早出现在在线广告上面,可以从外部引流到微信并打开微信内置浏览器然后打开一个指定的网页地址,在这个网页里面可以放任何想推广的内容,可以是引导文案.活动内容,或者是一 ...
- python之单例模式
#单例模式:有时需要写出高性能的类,那么会采用单例模式.通俗的解释就是类只创建一次实例,贯穿整个生命周期,实现了高性能. #1.模块化单例#所谓的模块化就是一个单独的.py文件来存储类,这样就是单例模 ...
- UGUI背包系统
在Unity3d中,UGUI提供了Scroll Rect.Grid Layout Group.Mask这三个组件,下面就给大家介绍下如何用这个三个组件来实现滚动视图. 首先放置好背包的背景图 在矩形线 ...