TensorFlow 之 高层封装slim,tflearn,keras
tensorflow资源整合
使用原生态TensorFlow API来实现各种不同的神经网络结构。虽然原生态的TensorFlow API可以很灵活的支持不同的神经网络结构,但是其代码相对比较冗长,写起来比较麻烦。为了让TensorFlow用起来更加方便,可以使用一些TensorFlow的高层封装。
目前对TensorFlow的主要封装有4个:
- 第一个是TensorFlow-Slim;
- 第二个是tf.contrib.learn(之前也被称为skflow);
- 第三个是TFLearn;
- 最后一个是Keras。
TensorFlow-Slim
# 直接使用TensorFlow原生态API实现卷积层。
with tf.variable_scope(scope_name):
weights = tf.get_variable("weight", …)
biases = tf.get_variable("bias", …)
conv = tf.nn.conv2d(…)
relu = tf.nn.relu(tf.nn.bias_add(conv, biases))
# 使用TensorFlow-Slim实现卷积层。通过TensorFlow-Slim可以在一行中实现一个卷积层的
# 前向传播算法。slim.conv2d函数的有3个参数是必填的。第一个参数为输入节点矩阵,第二参数
# 是当前卷积层过滤器的深度,第三个参数是过滤器的尺寸。可选的参数有过滤器移动的步长、
# 是否使用全0填充、激活函数的选择以及变量的命名空间等。
net = slim.conv2d(input, 32, [3, 3])
- 从上面的代码可以看出,使用TensorFlow-Slim可以大幅减少代码量。省去很多与网络结构无关的变量声明的代码。虽然TensorFlow-Slim可以起到简化代码的作用,但是在实际应用中,使用TensorFlow-Slim定义网络结构的情况相对较少,因为它既不如原生态TensorFlow的灵活,也不如下面将要介绍的其他高层封装简洁。但除了简化定义神经网络结构的代码量,使用TensorFlow-Slim的一个最大好处就是它直接实现了一些经典的卷积神经网络,并且Google提供了这些神经网络在ImageNet上训练好的模型。下表总结了通过TensorFlow-Slim可以直接实现的神经网络模型:
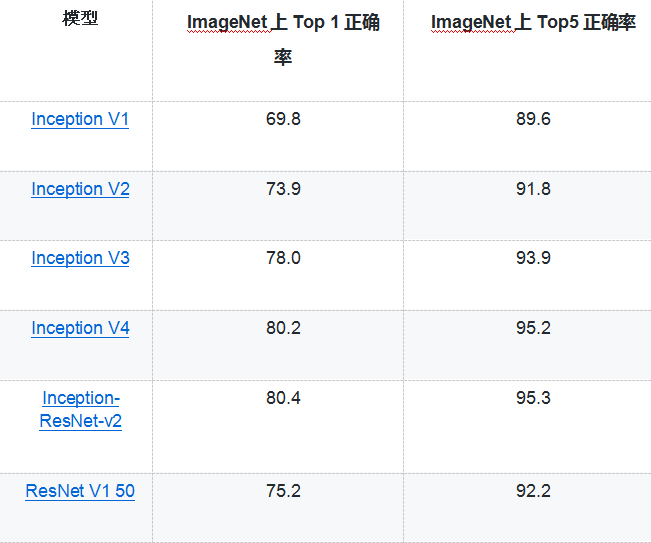
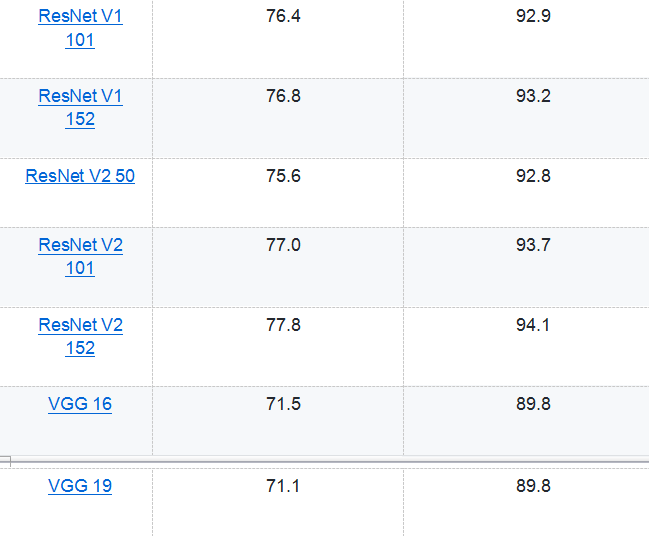
- Google提供的训练好的模型可以在github上tensorflow/models/slim目录下找到。在该目录下也提供了迁移学习的案例和代码。
tf.contrib.learn
tf.contrib.learn是TensorFlow官方提供的另外一个对TensorFlow的高层封装,通过这个封装,用户可以和使用sklearn类似的方法使用TensorFlow。通过tf.contrib.learn训练模型时,需要使用一个Estimator对象。Estimator对象是tf.contrib.learn 进行模型训练(train/fit)和模型评估(evaluation)的入口。
tf.contrib.learn模型提供了一些预定义的 Estimator,例如线性回归(tf.contrib.learn.LinearRegressor)、逻辑回归(tf.contrib.learn.LogisticRegressor)、线性分类(tf.contrib.learn.LinearClassifier)以及一些完全由全连接层构成的深度神经网络回归或者分类模型(tf.contrib.learn.DNNClassifier、tf.contrib.learn.DNNRegressor)。
除了可以使用预先定义好的模型,tf.contrib.learn也支持自定义模型,下面的代码给出了使用tf.contrib.learn在MNIST数据集上实现卷积神经网络的过程.
import tensorflow as tf
from sklearn import metrics
# 使用tf.contrib.layers中定义好的卷积神经网络结构可以更方便的实现卷积层。
layers = tf.contrib.layers
learn = tf.contrib.learn
# 自定义模型结构。这个函数有三个参数,第一个给出了输入的特征向量,第二个给出了
# 该输入对应的正确输出,最后一个给出了当前数据是训练还是测试。该函数的返回也有
# 三个指,第一个为定义的神经网络结构得到的最终输出节点取值,第二个为损失函数,第
# 三个为训练神经网络的操作。
def conv_model(input, target, mode):
# 将正确答案转化成需要的格式。
target = tf.one_hot(tf.cast(target, tf.int32), 10, 1, 0)
# 定义神经网络结构,首先需要将输入转化为一个三维举证,其中第一维表示一个batch中的
# 样例数量。
network = tf.reshape(input, [-1, 28, 28, 1])
# 通过tf.contrib.layers来定义过滤器大小为5*5的卷积层。
network = layers.convolution2d(network, 32, kernel_size=[5, 5], activation_fn=tf.nn.relu)
# 实现过滤器大小为2*2,长和宽上的步长都为2的最大池化层。
network = tf.nn.max_pool(network, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 类似的定义其他的网络层结构。
network = layers.convolution2d(network, 64, kernel_size=[5, 5], activation_fn=tf.nn.relu)
network = tf.nn.max_pool(network, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 将卷积层得到的矩阵拉直成一个向量,方便后面全连接层的处理。
network = tf.reshape(network, [-1, 7 * 7 * 64])
# 加入dropout。注意dropout只在训练时使用。
network = layers.dropout(
layers.fully_connected(network, 500, activation_fn=tf.nn.relu),
keep_prob=0.5,
is_training=(mode == tf.contrib.learn.ModeKeys.TRAIN))
# 定义最后的全连接层。
logits = layers.fully_connected(network, 10, activation_fn=None)
# 定义损失函数。
loss = tf.losses.softmax_cross_entropy(target, logits)
# 定义优化函数和训练步骤。
train_op = layers.optimize_loss(
loss,
tf.contrib.framework.get_global_step(),
optimizer='SGD',
learning_rate=0.01)
return tf.argmax(logits, 1), loss, train_op
# 加载数据。
mnist = learn.datasets.load_dataset('mnist')
# 定义神经网络结构,并在训练数据上训练神经网络。
classifier = learn.Estimator(model_fn=conv_model)
classifier.fit(mnist.train.images, mnist.train.labels, batch_size=100, steps=20000)
# 在测试数据上计算模型准确率。
score = metrics.accuracy_score(mnist.test.labels, list(classifier.predict(mnist.test.images)))
print('Accuracy: {0:f}'.format(score))
'''
运行上面的程序,可以得到类似如下的
Accuracy: 0.9901
'''
TFLearn
- TensorFlow的另外一个高层封装TFLearn进一步简化了tf.contrib.learn中对模型定义的方法,并提供了一些更加简洁的方法来定义神经网络的结构。和上面两个高层封装不一样,使用TFLearn需要单独安装,安装的方法为:
pip install tflearn
- 下面的代码介绍了如何通过TFLearn来实现卷积神经网络。更多关于TFLearn的用法介绍可以参考TFLearn的官方网站(http://tflearn.org/)
import tflearn
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimator import regression
import tflearn.datasets.mnist as mnist
# 读取MNIST数据。
trainX, trainY, testX, testY = mnist.load_data(one_hot=True)
# 将图像数据resize成卷积卷积神经网络输入的格式。
trainX = trainX.reshape([-1, 28, 28, 1])
testX = testX.reshape([-1, 28, 28, 1])
# 构建神经网络。input_data定义了一个placeholder来接入输入数据。
network = input_data(shape=[None, 28, 28, 1], name='input')
# 定义一个深度为5,过滤器为5*5的卷积层。从这个函数可以看出,它比tf.contrib.learn
# 中对卷积层的抽象要更加简洁。
network = conv_2d(network, 32, 5, activation='relu')
# 定义一个过滤器为2*2的最大池化层。
network = max_pool_2d(network, 2)
# 类似的定义其他的网络结构。
network = conv_2d(network, 64, 5, activation='relu')
network = max_pool_2d(network, 2)
network = fully_connected(network, 500, activation='relu', regularizer="L2")
network = dropout(network, 0.5)
network = fully_connected(network, 10, activation='softmax', regularizer="L2")
# 定义学习任务。指定优化器为sgd,学习率为0.01,损失函数为交叉熵。
network = regression(network, optimizer='sgd', learning_rate=0.01,
loss='categorical_crossentropy', name='target')
# 通过定义的网络结构训练模型,并在指定的验证数据上验证模型的效果。
model = tflearn.DNN(network, tensorboard_verbose=0)
model.fit(trainX, trainY, n_epoch=20, validation_set=([testX, testY]), show_metric=True)
- 运行上面的代码
---------------------------------
Training samples: 55000
Validation samples: 10000
--
Training Step: 860 | total loss: 0.25554 | time: 493.917s
| SGD | epoch: 001 | loss: 0.25554 - acc: 0.9267 |
val_loss: 0.24617 - val_acc: 0.9267 -- iter: 55000/55000
--
Training Step: 1054 | total loss: 0.28228 | time: 110.039s
| SGD | epoch: 002 | loss: 0.28228 - acc: 0.9207 -- iter: 12416/55000
Reference
TensorFlow 之 高层封装slim,tflearn,keras的更多相关文章
- TensorFlow高层封装:从入门到喷这本书
目录 TensorFlow高层封装:从入门到喷这本书 0. 写在前面 1. TensorFlow高层封装总览 2. Keras介绍 2.1 Keras基本用法 2.2 Keras高级用法 3. Est ...
- windows10(64位)Anaconda3+Python3.6搭建Tensorflow(cpu版本)及keras
转自:windows10(64位)Anaconda3+Python3.6搭建Tensorflow(cpu版本)及keras 1.本来电脑安装的是anaconda3 5.3.1,但安装的python版本 ...
- 吴裕雄--天生自然TensorFlow高层封装:使用TFLearn处理MNIST数据集实现LeNet-5模型
# 1. 通过TFLearn的API定义卷机神经网络. import tflearn import tflearn.datasets.mnist as mnist from tflearn.layer ...
- 吴裕雄--天生自然TensorFlow高层封装:Keras-多输入输出
# 1. 数据预处理. import keras from keras.models import Model from keras.datasets import mnist from keras. ...
- 吴裕雄--天生自然TensorFlow高层封装:Keras-返回值
# 1. 数据预处理. import keras from keras.models import Model from keras.datasets import mnist from keras. ...
- 吴裕雄--天生自然TensorFlow高层封装:Keras-TensorFlow API
# 1. 模型定义. import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist_ ...
- 吴裕雄--天生自然TensorFlow高层封装:Keras-CNN
# 1. 数据预处理 import keras from keras import backend as K from keras.datasets import mnist from keras.m ...
- 吴裕雄--天生自然TensorFlow高层封装:使用TensorFlow-Slim处理MNIST数据集实现LeNet-5模型
# 1. 通过TensorFlow-Slim定义卷机神经网络 import numpy as np import tensorflow as tf import tensorflow.contrib. ...
- 吴裕雄--天生自然TensorFlow高层封装:Estimator-自定义模型
# 1. 自定义模型并训练. import numpy as np import tensorflow as tf from tensorflow.examples.tutorials.mnist i ...
随机推荐
- php msql 表单
http://www.cnblogs.com/webers/p/3849707.html
- Linux inode 之我见
Linux硬盘组织方式为:引导区.超级块(superblock),索引结点(inode),数据块(datablock),目录块(diredtory block).其中超级块中包含了关于该硬盘或分区上的 ...
- stl vector 类
目录 [-]说明构造方法例子vector 类中定义了4中种构造函数: · 默认构造函数,构造一个初始长度为0的空向量,如:vector<int> v1; · 带有单个整形参数的构造函数,此 ...
- Selenium WebDriver- 操作JavaScript的Alert弹窗
弹层和弹框是有区别的,弹框是那种完全没样式的框子:弹层是可以直接看到html的,有样式 #encoding=utf-8 import unittest import time from seleniu ...
- Leetcode207--->课程表(逆拓扑排序)
题目: 课程表,有n个课程,[0, n-1]:在修一个课程前,有可能要修前导课程: 举例: 2, [[1,0]] 修课程1前需要先修课程0 There are a total of 2 courses ...
- andorid studio 环境搭建
1 安装jdk,配置jdk的环境变量http://www.cnblogs.com/liuhongfeng/p/4177568.html(通过java ,javac, java -version来察看j ...
- 【Vjudge】P1989Subpalindromes(线段树)
题目链接 水题一道,用线段树维护哈希值,脑补一下加减乱搞搞……注意细节就过了 一定注意细节…… #include<cstdio> #include<cstdlib> #incl ...
- cf- 297 < b > -- 区间翻转操作的优化
B. Pasha and String time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- BZOJ 4819 [Sdoi2017]新生舞会 ——费用流 01分数规划
比值最大 分数规划 二分答案之后用费用流进行验证. 据说标称强行乘以1e7换成了整数的二分. 不过貌似实数二分也可以过. #include <map> #include <cmath ...
- windows10下安装ubuntu16.04 双系统
软件和材料: UltraISO .ubuntu16.04镜像.U盘 步骤: 1.先在windows10 上下载UltraISO并安装 2.打开UltraISO,插入优盘,制作ubuntu160.4 ...