Python3获取大量电影信息:调用API
实验室这段时间要采集电影的信息,给出了一个很大的数据集,数据集包含了4000多个电影名,需要我写一个爬虫来爬取电影名对应的电影信息。
其实在实际运作中,根本就不需要爬虫,只需要一点简单的Python基础就可以了。
前置需求:
Python3语法基础
HTTP网络基础
===================================
第一步,确定API的提供方。IMDb是最大的电影数据库,与其相对的,有一个OMDb的网站提供了API供使用。这家网站的API非常友好,易于使用。
http://www.omdbapi.com/
第二步,确定网址的格式。
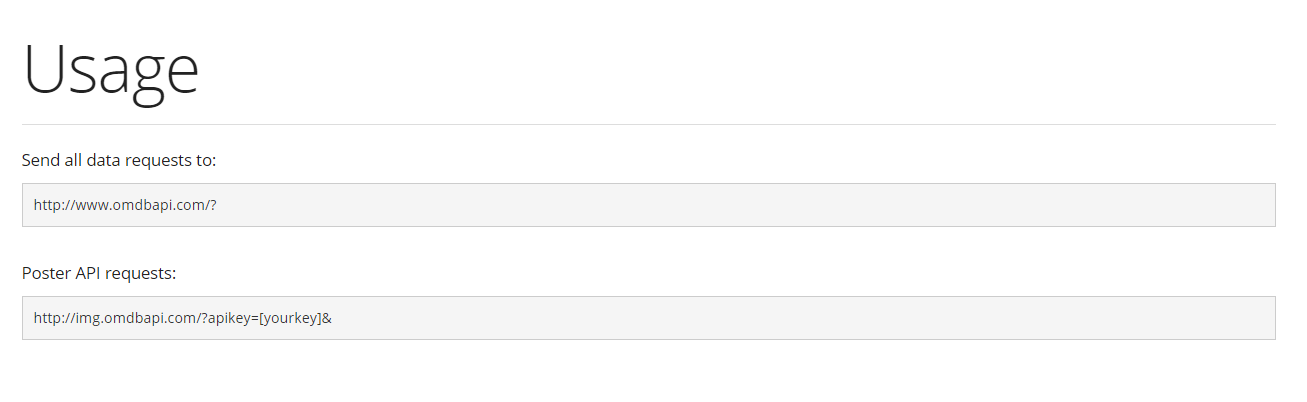
第三步,了解基本的Requests库的使用方法。
http://cn.python-requests.org/zh_CN/latest/

为什么我要使用Requests,不使用urllib.request呢?
因为Python的这个库容易出各种各样的奇葩问题,我已经受够了……
第四步,编写Python代码。
我想做的是,逐行读取文件,然后用该行的电影名去获取电影信息。因为源文件较大,readlines()不能完全读取所有电影名,所以我们逐行读取。
import requests
for line in open("movies.txt"):
s=line.split('%20\n')
urll='http://www.omdbapi.com/?t='+s[0]
result=requests.get(urll)
if result:
json=result.text
print(json)
p=open('result0.json','a')
p.write(json)
p.write('\n')
p.close()
我预先把电影名文件全部格式化了一遍,将所有的空格替换成了"%20",便于使用API(否则会报错)。这个功能可以用Visual Studio Code完成。
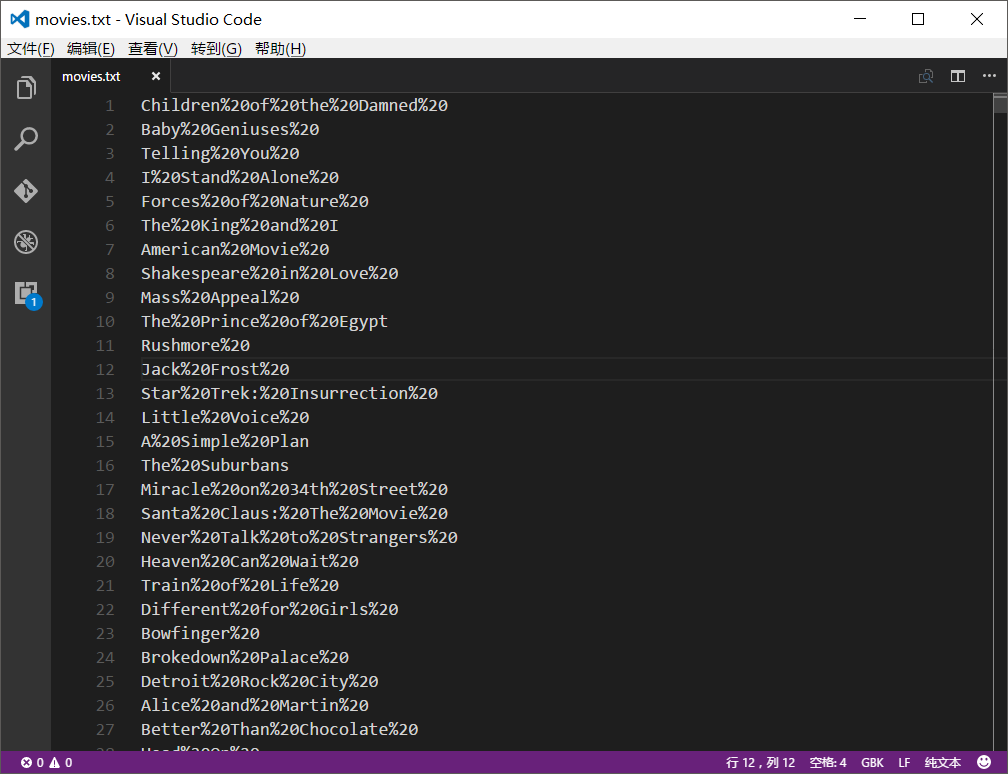
注意,编码的时候选择GBK编码,不然会出现下面错误:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 0: illegal multibyte sequence
第五步,做优化和异常处理。
主要做三件事,第一件事,控制API速度,防止被服务器屏蔽;
第二件事,获取API key(甚至使用多个key)
第三件事:异常处理。
import requests
key=[‘’] for line in open("movies.txt"):
try:
#……
except TimeoutError:
continue
except UnicodeEncodeError:
continue
except ConnectionError:
continue
下面贴出完整代码:
# -*- coding: utf-8 -*- import requests
import time key=['xxxxx','yyyyy',zzzzz','aaaaa','bbbbb']
i=0 for line in open("movies.txt"):
try:
i=(i+1)%5
s=line.split('%20\n')
urll='http://www.omdbapi.com/?t='+s[0]+'&apikey='+key[i]
result=requests.get(urll)
if result:
json=result.text
print(json)
p=open('result0.json','a')
p.write(json)
p.write('\n')
p.close()
time.sleep(1)
except TimeoutError:
continue
except UnicodeEncodeError:
continue
except ConnectionError:
continue
接下来喝杯茶,看看自己的程序跑得怎么样吧!
Python3获取大量电影信息:调用API的更多相关文章
- 一个 C# 获取高精度时间类(调用API QueryP*)
如果你觉得用 DotNet 自带的 DateTime 获取的时间精度不够,解决的方法是通过调用 QueryPerformanceFrequency 和 QueryPerformanceCounter这 ...
- python3获取网页天气预报信息并打印
查到一个可以提供区域天气预报的url, https://www.sojson.com/open/api/weather/json.shtml?city=%E6%88%90%E9%83%BD打算用pyt ...
- Python3获取拉勾网招聘信息
为了了解跟python数据分析有关行业的信息,大概地了解一下对这个行业的要求以及薪资状况,我决定从网上获取信息并进行分析.既然想要分析就必须要有数据,于是我选择了拉勾,冒着危险深入内部,从他们那里得到 ...
- 获取app安装信息私有api
@class LSApplicationProxy, NSArray, NSDictionary, NSProgress, NSString, NSURL, NSUUID; @interface LS ...
- iOS 获取APP相关信息 私有API
/* Generated by RuntimeBrowser Image: /System/Library/Frameworks/MobileCoreServices.framework/Mobile ...
- 爬虫实战【11】Python获取豆瓣热门电影信息
之前我们从猫眼获取过电影信息,而且利用分析ajax技术,获取过今日头条的街拍图片. 今天我们在豆瓣上获取一些热门电影的信息. 页面分析 首先,我们先来看一下豆瓣里面选电影的页面,我们默认选择热门电影, ...
- Vue 电影信息影评(豆瓣,猫眼)
Vue电影信息影评网站 此网站是我的毕业设计,题目是"基于HTML5的电影信息汇总弄网站",由于最近在看Vue.js,所以就想用Vue.js来构建一个前端网站,这里code就不大篇 ...
- 80 行代码爬取豆瓣 Top250 电影信息并导出到 CSV 及数据库
一.下载页面并处理 二.提取数据 观察该网站 html 结构 可知该页面下所有电影包含在 ol 标签下.每个 li 标签包含单个电影的内容. 使用 XPath 语句获取该 ol 标签 在 ol 标签中 ...
- Android 获取手机信息,设置权限,申请权限,查询联系人,获取手机定位信息
Android 获取手机信息,设置权限,申请权限,查询联系人,获取手机定位信息 本文目录: 获取手机信息 设置权限 申请权限 查询联系人 获取手机定位信息 调用高德地图,设置显示2个坐标点的位置,以及 ...
随机推荐
- 根据xml文件自动生成xsd文件
根据xml生成xsd文档 1. 找到vs自带的xsd.exe工具所在的文件夹位置: C:\Program Files (x86)\Microsoft SDKs\Windows\v7.0A\Bin 注意 ...
- 基于selenium+java的12306自动抢票
import java.util.concurrent.TimeUnit; import org.openqa.selenium.By;import org.openqa.selenium.Keys; ...
- cogs 1901. [国家集训队2011]数颜色
Cogs 1901. [国家集训队2011]数颜色 ★★★ 输入文件:nt2011_color.in 输出文件:nt2011_color.out 简单对比时间限制:0.6 s 内存限制 ...
- IT兄弟连 JavaWeb教程 监听器2
4 监听HttpSession域对象的创建和销毁 HttpSessionListener接口用于监听HttpSession对象的创建和销毁. 创建一个Session时,激发sessionCreate ...
- Java IO 输入和输出流
数据流是指一组有顺序的,有起点和终点的字节集合. 最初的版本中,java.io 包中的流只有普通的字节流,即以 byte 为基本处理单位的流.字节流用来读写 8 位的数据,由于不会对数据做任何转换,因 ...
- 13.Python略有小成(装饰器,递归函数)
Python(装饰器,递归函数) 一.开放封闭原则 软件面世时,不可能把所有的功能都设计好,再未来的一两年功能会陆续上线,定期更新迭代,软件之前所用的源代码,函数里面的代码以及函数的调用方式一般不 ...
- python爬虫——web前端基础(3)
超链接的使用------>>>> 链接的引用使用的是<a>标记. <a>标记的基本语法:<a href="链接地址" ta ...
- java.lang.NoClassDefFoundError: com/sun/tools/javac/processing/JavacProcessingEnvironment
最近项目用到了java程序动态编译java源文件,运行程序一直报错,提示错误如下: Can't initialize javac processor due to (most likely) a cl ...
- Nacos深入浅出(七)
大家可以把这个也下载下来,结合之前的Nacos一起来看下,感觉前面几篇看了好像冰山一角的感觉 学无止境! https://github.com/nacos-group/nacos-spring-pro ...
- 黑马学习Ajax 跨域资源共享 jQuery+jsonp实现