pandas处理大文本数据
当数据文件是百万级数据时,设置chunksize来分批次处理数据
案例:美国总统竞选时的数据分析
读取数据
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df1 = pd.read_csv("./usa_election.csv",low_memory=False)
df1.shape
结果:(536041, 16) #可以看到数据量为536041
将数据在此进行级联成更大的文本数据
df =pd.concat([df1,df1,df1,df1])
df.shape
结果:(2144164, 16)
%%time
ret = df.to_csv("./hehe.csv",index = False)
ret
将df数据读取到文件中,并计算写入时间
ret = pd.read_csv("./hehe.csv",low_memory = False,chunksize=500000)
#将写入的大数据文件读出来,low_memory = False表示是否在内部一块的形式处理文件,chunksize表示分批次处理文件,每次处理多少数据
ret
读取的文件格式是:<pandas.io.parsers.TextFileReader at 0x122f30f0>
添加循环,读出来数据
for x in ret:
print(type(x))
结果:
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.frame.DataFrame'>
然后分批次处理数据 # 将str类型的时间转化成为时间类型的
处理前:

处理后:
处理过程:
months = {"JAN":"1", "FEB":"2","MAR":"3","APR":"4","MAY":"5","JUN":"6","JUL":"7","AUG":"8","SEP":"9","OCT":"10","NOV":"11","DEC":"12"}
def conver(x):
day,month,year = x.split("-") #进行切片操作
datatime = "20"+year+"-"+str(months[month])+"-"+day
return datatime #对切片重新组合
df1["contb_receipt_dt"] = df1["contb_receipt_dt"].map(conver)
df1["contb_receipt_dt"] = pd.to_datetime(df1["contb_receipt_dt"]) #转化成时间格式
df1["contb_receipt_dt"]
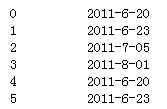
累加和的操作
# 累加和
a = np.arange(101) 随机一个数组数据
display(a)
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77,
78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90,
91, 92, 93, 94, 95, 96, 97, 98, 99, 100])
b = a.cumsum() #求出该数据的累加和用函数cumsum()
ree=DataFrame(b,columns=["num"])
ree["num"].plot() #画出累加和的那列的图谱

pandas处理大文本数据的更多相关文章
- JDBC 关于大文本数据
大文本数据Clob,在不同的数据库中类型名不一致,有的是text格式,有的是clob,还有其他一些格式 package test; import java.io.BufferedReader; i ...
- Android自定义ScrollView分段加载大文本数据到TextView
以下内容为原创,转载时请注明链接地址:http://www.cnblogs.com/tiantianbyconan/p/3311658.html 这是我现在碰到的一个问题,如果需要在TextView中 ...
- Pandas字符串和文本数据
在本章中,我们将使用基本系列/索引来讨论字符串操作.在随后的章节中,将学习如何将这些字符串函数应用于数据帧(DataFrame). Pandas提供了一组字符串函数,可以方便地对字符串数据进行操作. ...
- pb中读取大文本数据
string ls_FileName,lb_FileDatas,lb_FileData long ll_FileLen,ll_Handle,ll_Loop,ll_Bytes,ll_Loops,ll_ ...
- 利用JDBC处理mysql大数据--大文本和二进制文件等
转载自http://www.cnblogs.com/xdp-gacl/p/3982581.html 一.基本概念 大数据也称之为LOB(Large Objects),LOB又分为:clob和blob, ...
- 使用JDBC处理MySQL大文本和大数据
LOB,Large Objects,是一种用于存储大对象的数据类型,一般LOB又分为BLOB与CLOB.BLOB通常用于存储二进制数据,比如图片.音频.视频等.CLOB通常用于存储大文本,比如小说. ...
- jdbc基础 (三) 大文本、二进制数据处理
LOB (Large Objects) 分为:CLOB和BLOB,即大文本和大二进制数据 CLOB:用于存储大文本 BLOB:用于存储二进制数据,例如图像.声音.二进制文件 在mysql中,只有B ...
- 使用jdbc存储图片和大文本
package cn.itcast.i_batch; import java.sql.Connection; import java.sql.PreparedStatement; import jav ...
- Python文本数据互相转换(pandas and win32com)
(工作之后,就让自己的身心都去休息吧) 今天介绍一下文本数据的提取和转换,这里主要实例的转换为excel文件(.xlsx)转换world文件(.doc/docx),同时需要使用win32api,同py ...
随机推荐
- Etherscan API 中文文档-交易以及检查交易收据状态
本文原文链接 点击这里获取Etherscan API 中文文档(完整版) 完整内容排版更好,推荐读者前往阅读. 交易(Transaction) 交易相关的 API,接口的参数说明请参考Ethersca ...
- [BeiJing wc2012]连连看
题目链接 费用流板子+拆点 #include <bits/stdc++.h> using namespace std; typedef long long ll; inline int r ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- jquery的$().each和$.each的区别
在jquery中,遍历对象和数组,经常会用到$().each和$.each(),两个方法.两个方法是有区别的,从而这两个方法在针对不同的操作上,显示了各自的特点. $().each,对于这个方法,在d ...
- Vsftp设置为PASV mode(被动模式传送)
首先配置vsftpd.conf文件: #vi /etc/vsftpd/vsftpd.conf 在文件的末尾加上: pasv_enable=YES pasv_max_port=30010 pasv_mi ...
- 一步步实现自己的ORM(二)
在第一篇<一步步实现自己的ORM(一)>里,我们用反射获取类名.属性和值,我们用这些信息开发了简单的INSERT方法,在上一篇文章里我们提到主键为什么没有设置成自增长类型,单单从属性里我们 ...
- AJPFX辨析Java中堆内存和栈内存的区别
Java把内存分成两种,一种叫做栈内存,一种叫做堆内存 在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配.当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间 ...
- Redis key 键
1.set key value //设置.修改值 2.get key //如果key不存在,返回nil,表示空. 3.type key //返回key对应的value的数据类型 4.ren ...
- Java分页下载
需求.提供公共的可以按照一定条件查询出结果,并提供将查询结果全部下载功能(Excel.CSV.TXT),由于一次性查出结果放到内存会占用大量内存.需要支持分页模式查询出所有数据. 实现思路 1.在公共 ...
- JavaScript 事件对象event
什么是事件对象? 比如当用户单击某个元素的时候,我们给这个元素注册的事件就会触发,该事件的本质就是一个函数,而该函数的形参接收一个event对象. 注:事件通常与函数结合使用,函数不会在事件发生前被执 ...