近似最近邻算法-annoy解析
转自https://www.cnblogs.com/futurehau/p/6524396.html
Annoy是高维空间求近似最近邻的一个开源库。
Annoy构建一棵二叉树,查询时间为O(logn)。
Annoy通过随机挑选两个点,并使用垂直于这个点的等距离超平面将集合划分为两部分。
如图所示,图中灰色线是连接两个点,超平面是加粗的黑线。按照这个方法在每个子集上迭代进行划分。

依此类推,直到每个集合最多剩余k个点,下图是一个k = 10 的情况。
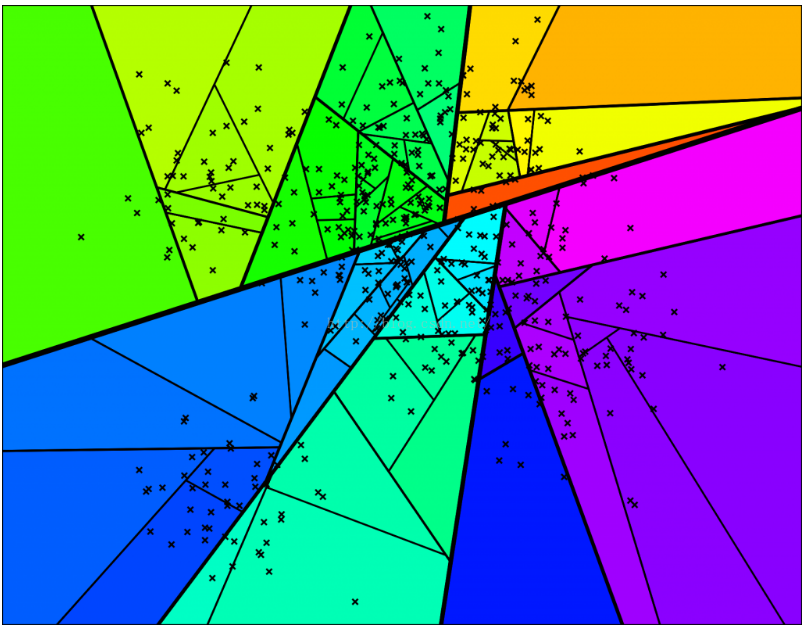
相应的完整二叉树结构:
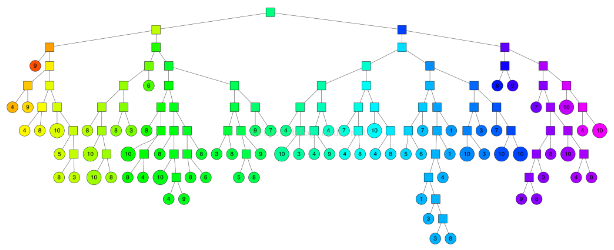
随机投影森林。
一个思想依据是:在原空间中相邻的点,在树结构上也表现出相互靠近的特点,也就是说,如果两个点在空间上相互靠近,那么他们很可能被树结构划分到一起。
如果要在空间中查找临近点,我们可以在这个二叉树中搜索。上图中每个节点用超平面来定义,所以我们可以计算出该节点往哪个方向遍历,搜索时间 log n
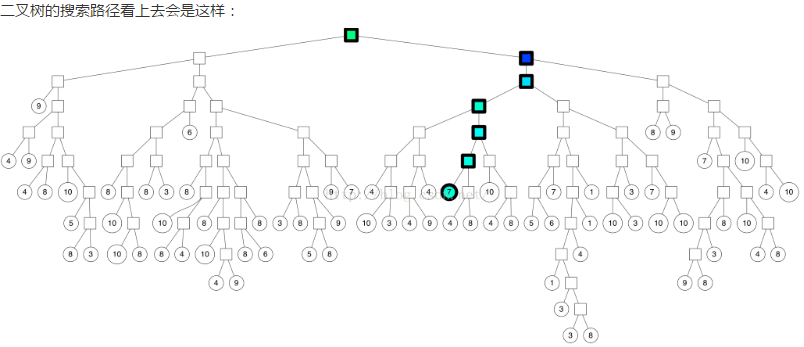
如上图,我们找到了七个最近邻,但是假如我们想找到更多的最近邻怎么办?有些最近邻是在我们遍历的叶子节点的外边的。
技巧1:使用优先队列
如果一个划分的两边“靠得足够近”(量化方式在后面介绍),我们就两边都遍历。这样就不只是遍历一个节点的一边,我们将遍历更多的点
我们可以设置一个阈值,用来表示是否愿意搜索划分“错”的一遍。如果设置为0,我们将总是遍历“对”的一片。但是如果设置成0.5,就按照上面的搜索路径。
这个技巧实际上是利用优先级队列,依据两边的最大距离。好处是我们能够设置比0大的阈值,逐渐增加搜索范围。
技巧2:构建一个森林
我们能够用一个优先级队列,同时搜索所有的树。这样有另外一个好处,搜索会聚焦到那些与已知点靠得最近的那些树——能够把距离最远的空间划分出去
每棵树都包含所有的点,所以当我们搜索多棵树的时候,将找到多棵树上的多个点。如果我们把所有的搜索结果的叶子节点都合在一起,那么得到的最近邻就非常符合要求。
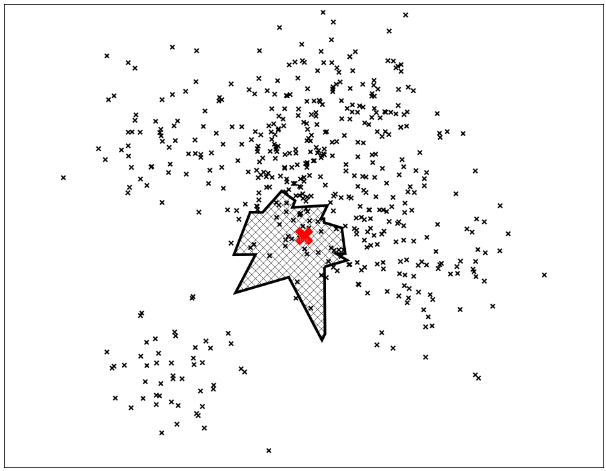
依照上述方法,我们找到一个近邻的集合,接下来就是计算所有的距离和对这些点进行排序,找到最近的k个点。
很明显,我们会丢掉一些最近的点,这也是为什么叫近似最近邻的原因。
Annoy在实际使用的时候,提供了一种机制可以调整(搜索k),你能够根据它来权衡性能(时间)和准确度(质量)。
tips:
1.距离计算,采用归一化的欧氏距离:vectors = sqrt(2-2*cos(u, v))
2.向量维度较小(<100),即使维度到达1000变现也不错
3.内存占用小
4.索引创建与查找分离(特别是一旦树已经创建,就不能添加更多项)
5.有两个参数可以用来调节Annoy 树的数量n_trees和搜索期间检查的节点数量search_k
n_trees在构建时提供,并影响构建时间和索引大小。 较大的值将给出更准确的结果,但更大的索引。
search_k在运行时提供,并影响搜索性能。 较大的值将给出更准确的结果,但将需要更长的时间返回。
如果不提供search_k,它将默认为n *
n_trees,其中n是近似最近邻的数目。
否则,search_k和n_tree大致是独立的,即如果search_k保持不变,n_tree的值不会影响搜索时间,反之亦然。
基本上,建议在可用负载量的情况下尽可能大地设置n_trees,并且考虑到查询的时间限制,建议将search_k设置为尽可能大。
近似最近邻算法-annoy解析的更多相关文章
- Annoy解析
Annoy是高维空间求近似最近邻的一个开源库. Annoy构建一棵二叉树,查询时间为O(logn). Annoy通过随机挑选两个点,并使用垂直于这个点的等距离超平面将集合划分为两部分. 如图所示,图中 ...
- JS-常考算法题解析
常考算法题解析 这一章节依托于上一章节的内容,毕竟了解了数据结构我们才能写出更好的算法. 对于大部分公司的面试来说,排序的内容已经足以应付了,由此为了更好的符合大众需求,排序的内容是最多的.当然如果你 ...
- 在opencv3中实现机器学习算法之:利用最近邻算法(knn)实现手写数字分类
手写数字digits分类,这可是深度学习算法的入门练习.而且还有专门的手写数字MINIST库.opencv提供了一张手写数字图片给我们,先来看看 这是一张密密麻麻的手写数字图:图片大小为1000*20 ...
- 使用C语言实现二维,三维绘图算法(2)-解析曲面的显示
使用C语言实现二维,三维绘图算法(2)-解析曲面的显示 ---- 引言---- 每次使用OpenGL或DirectX写三维程序的时候, 都有一种隔靴搔痒的感觉, 对于内部的三维算法的实现不甚了解. 其 ...
- KNN(k-nearest neighbor的缩写)又叫最近邻算法
KNN(k-nearest neighbor的缩写)又叫最近邻算法 机器学习笔记--KNN算法1 前言 Hello ,everyone. 我是小花.大四毕业,留在学校有点事情,就在这里和大家吹吹我们的 ...
- 【算法】K最近邻算法(K-NEAREST NEIGHBOURS,KNN)
K最近邻算法(k-nearest neighbours,KNN) 算法 对一个元素进行分类 查看它k个最近的邻居 在这些邻居中,哪个种类多,这个元素有更大概率是这个种类 使用 使用KNN来做两项基本工 ...
- 最近邻算法(KNN)
最近邻算法: 1.什么是最近邻是什么? kNN算法全程是k-最近邻算法(k-Nearest Neighbor) kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数数以一个类型别 ...
- Adaboost 算法实例解析
Adaboost 算法实例解析 1 Adaboost的原理 1.1 Adaboost基本介绍 AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,由 ...
- 2. Attention Is All You Need(Transformer)算法原理解析
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
随机推荐
- ubuntu下使用JNI Java调用C++的例子
TestJNI.java public class TestJNI { static{ System.load("/home/buyizhiyou/workspace/JNI/src/lib ...
- python之random、time与sys模块
一.random模块 import random # float型 print(random.random()) #取0-1之间的随机小数 print(random.uniform(n,m)) #取 ...
- Hadoop读写mysql
需求 两张表,一张click表记录某广告某一天的点击量,另一张total_click表记录某广告的总点击量 建表 CREATE TABLE `click` ( `id` ) NOT NULL AUTO ...
- Flink原理(一)——基础架构
Flink系列博客,基于Flink1.6,打算分为三部分:原理.源码.实例以及API使用分析,后期等系列博客完成后再弄一个目录. 该系列博客是我自己学习过程中的一些理解,若有不正确.不准确的地方欢迎大 ...
- 使用DateTimeFormatter替换线程不安全的SimpleDateFormat
原文:https://blog.csdn.net/baofeidyz/article/details/81307478 如何让SimpleDateFormat保持安全运行? 方案一 每次都去new这种 ...
- How to parse unix timestamp to time.Time
The time.Parse function does not do Unix timestamps. Instead you can use strconv.ParseInt to parse ...
- P2746 P2812 [USACO5.3]校园网Network of Schools[SCC缩点]
题目描述 一些学校连入一个电脑网络.那些学校已订立了协议:每个学校都会给其它的一些学校分发软件(称作"接受学校").注意即使 B 在 A 学校的分发列表中, A 也不一定在 B 学 ...
- 大数据之路week07--day04 (YARN,Hadoop的优化,combline,join思想,)
hadoop 的计算特点:将计算任务向数据靠拢,而不是将数据向计算靠拢. 特点:数据本地化,减少网络io. 首先需要知道,hadoop数据本地化是指的map任务,reduce任务并不具备数据本地化特征 ...
- Codeforces Round #533 (Div. 2) E. Helping Hiasat(最大独立集)
题目链接:https://codeforces.com/contest/1105/problem/E 题意:有 n 个事件,op = 1 表示我可以修改昵称,op = 2 表示一个名为 s_i 的朋友 ...
- 使用jQuery快速高效制作网页交互特效----jQuery中的事件与动画
jQuery中的事件 和WinForm一样,在网页中的交互也是需要事件来实现的,例如tab切换效果,可以通过鼠标单击事件来实现. 事件在元素对象与功能代码中起着重要的桥梁作用. 在JQuery中,事件 ...