「数据结构与算法(Python)」(二)
顺序表
在程序中,经常需要将一组(通常是同为某个类型的)数据元素作为整体管理和使用,需要创建这种元素组,用变量记录它们,传进传出函数等。一组数据中包含的元素个数可能发生变化(可以增加或删除元素)。
对于这种需求,最简单的解决方案便是将这样一组元素看成一个序列,用元素在序列里的位置和顺序,表示实际应用中的某种有意义的信息,或者表示数据之间的某种关系。
这样的一组序列元素的组织形式,我们可以将其抽象为线性表。一个线性表是某类元素的一个集合,还记录着元素之间的一种顺序关系。线性表是最基本的数据结构之一,在实际程序中应用非常广泛,它还经常被用作更复杂的数据结构的实现基础。
根据线性表的实际存储方式,分为两种实现模型:
- 顺序表,将元素顺序地存放在一块连续的存储区里,元素间的顺序关系由它们的存储顺序自然表示。
- 链表,将元素存放在通过链接构造起来的一系列存储块中。
顺序表的基本形式

图a表示的是顺序表的基本形式,数据元素本身连续存储,每个元素所占的存储单元大小固定相同,元素的下标是其逻辑地址,而元素存储的物理地址(实际内存地址)可以通过存储区的起始地址Loc (e0)加上逻辑地址(第i个元素)与存储单元大小(c)的乘积计算而得,即:
Loc(ei) = Loc(e0) + c*i
故,访问指定元素时无需从头遍历,通过计算便可获得对应地址,其时间复杂度为O(1)。
如果元素的大小不统一,则须采用图b的元素外置的形式,将实际数据元素另行存储,而顺序表中各单元位置保存对应元素的地址信息(即链接)。由于每个链接所需的存储量相同,通过上述公式,可以计算出元素链接的存储位置,而后顺着链接找到实际存储的数据元素。注意,图b中的c不再是数据元素的大小,而是存储一个链接地址所需的存储量,这个量通常很小。
图b这样的顺序表也被称为对实际数据的索引,这是最简单的索引结构。(PS:python中的list就是采用这种方式)
顺序表的结构与实现
顺序表的结构

一个顺序表的完整信息包括两部分,一部分是表中的元素集合,另一部分是为实现正确操作而需记录的信息,即有关表的整体情况的信息,这部分信息主要包括元素存储区的容量和当前表中已有的元素个数两项。
顺序表的两种基本实现方式
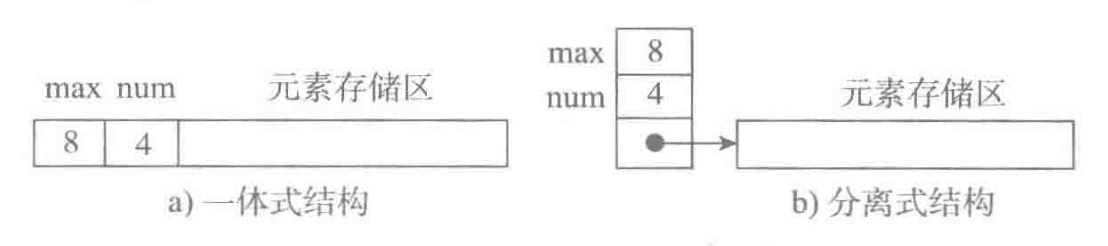
图a为一体式结构,存储表信息的单元与元素存储区以连续的方式安排在一块存储区里,两部分数据的整体形成一个完整的顺序表对象。
一体式结构整体性强,易于管理。但是由于数据元素存储区域是表对象的一部分,顺序表创建后,元素存储区就固定了。
图b为分离式结构,表对象里只保存与整个表有关的信息(即容量和元素个数),实际数据元素存放在另一个独立的元素存储区里,通过链接与基本表对象关联。
元素存储区替换
一体式结构由于顺序表信息区与数据区连续存储在一起,所以若想更换数据区,则只能整体搬迁,即整个顺序表对象(指存储顺序表的结构信息的区域)改变了。
分离式结构若想更换数据区,只需将表信息区中的数据区链接地址更新即可,而该顺序表对象不变。
元素存储区扩充
采用分离式结构的顺序表,若将数据区更换为存储空间更大的区域,则可以在不改变表对象的前提下对其数据存储区进行了扩充,所有使用这个表的地方都不必修改。只要程序的运行环境(计算机系统)还有空闲存储,这种表结构就不会因为满了而导致操作无法进行。人们把采用这种技术实现的顺序表称为动态顺序表,因为其容量可以在使用中动态变化。
扩充的两种策略
每次扩充增加固定数目的存储位置,如每次扩充增加10个元素位置,这种策略可称为线性增长。
特点:节省空间,但是扩充操作频繁,操作次数多。
每次扩充容量加倍,如每次扩充增加一倍存储空间。
特点:减少了扩充操作的执行次数,但可能会浪费空间资源。以空间换时间,推荐的方式。
顺序表的操作
增加元素
如图所示,为顺序表增加新元素111的三种方式

a. 尾端加入元素,时间复杂度为O(1)
b. 非保序的加入元素(不常见),时间复杂度为O(1)
c. 保序的元素加入,时间复杂度为O(n)
删除元素
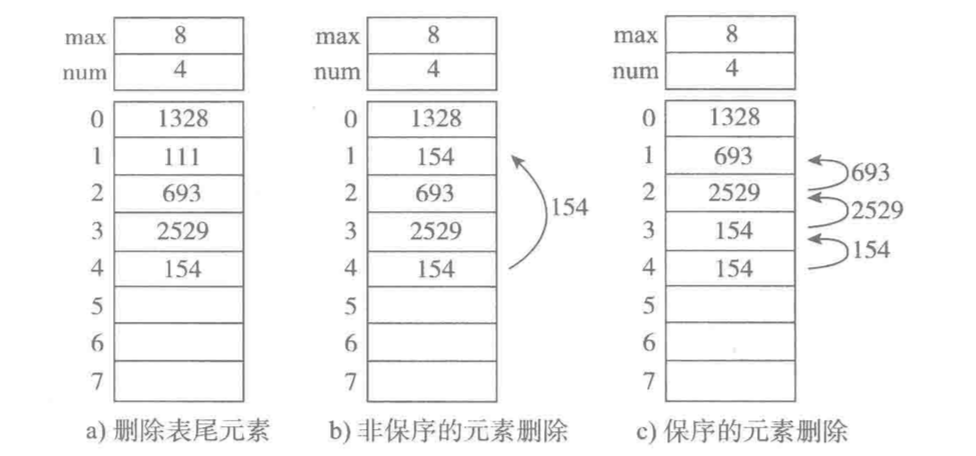
a. 删除表尾元素,时间复杂度为O(1)
b. 非保序的元素删除(不常见),时间复杂度为O(1)
c. 保序的元素删除,时间复杂度为O(n)
Python中的顺序表
Python中的list和tuple两种类型采用了顺序表的实现技术,具有前面讨论的顺序表的所有性质。
tuple是不可变类型,即不变的顺序表,因此不支持改变其内部状态的任何操作,而其他方面,则与list的性质类似。
list的基本实现技术
Python标准类型list就是一种元素个数可变的线性表,可以加入和删除元素,并在各种操作中维持已有元素的顺序(即保序),而且还具有以下行为特征:
基于下标(位置)的高效元素访问和更新,时间复杂度应该是O(1);
为满足该特征,应该采用顺序表技术,表中元素保存在一块连续的存储区中。
允许任意加入元素,而且在不断加入元素的过程中,表对象的标识(函数id得到的值)不变。
为满足该特征,就必须能更换元素存储区,并且为保证更换存储区时list对象的标识id不变,只能采用分离式实现技术。
在Python的官方实现中,list就是一种采用分离式技术实现的动态顺序表。这就是为什么用list.append(x) (或 list.insert(len(list), x),即尾部插入)比在指定位置插入元素效率高的原因。
在Python的官方实现中,list实现采用了如下的策略:在建立空表(或者很小的表)时,系统分配一块能容纳8个元素的存储区;在执行插入操作(insert或append)时,如果元素存储区满就换一块4倍大的存储区。但如果此时的表已经很大(目前的阀值为50000),则改变策略,采用加一倍的方法。引入这种改变策略的方式,是为了避免出现过多空闲的存储位置。
(来源:https://www.bilibili.com/video/av21540971)
「数据结构与算法(Python)」(二)的更多相关文章
- 数据结构与算法-Python/C(目录)
第一篇 基本概念 01 什么是数据结构 02 什么是算法 03 应用实例-最大子列和问题 第二篇 线性结构 01 线性表及其实现 02 堆栈 03 队列 04 应用实例-多项式加法运算 05 小白专场 ...
- 北京大学公开课《数据结构与算法Python版》
之前我分享过一个数据结构与算法的课程,很多小伙伴私信我问有没有Python版. 看了一些公开课后,今天特向大家推荐北京大学的这门课程:<数据结构与算法Python版>. 课程概述 很多同学 ...
- 【数据结构与算法Python版学习笔记】引言
学习来源 北京大学-数据结构与算法Python版 目标 了解计算机科学.程序设计和问题解决的基本概念 计算机科学是对问题本身.问题的解决.以及问题求解过程中得出的解决方案的研究.面对一 个特定问题,计 ...
- 「数据结构与算法(Python)」(一)
算法的提出 算法的概念 算法是计算机处理信息的本质,因为计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务.一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写 ...
- 数据结构与算法(Python)
一.数据结构与算法概述 数据结构与算法的定义 我们把现实中大量而且非常复杂的问题以特定的数据类型(个体)和特定的存储结构(个体的关系)保存到相应的主存储器(内存)中,以及在此基础上为实现某个功能而执行 ...
- 「数据结构与算法之链表(Python)」(四)
什么是链表 顺序表的储存分为一体式结构和分离式结构,但总的来说存储数据的内存是一块连续的单元,每次申请前都要预估所需要的内存空间大小.这样就不能随意的增加我们需要的数据了.链接就是为了解决这个问题.它 ...
- 「数据结构与算法(Python)」(三)
栈结构实现 栈可以用顺序表实现,也可以用链表实现. 栈的操作 Stack() 创建一个新的空栈 push(item) 添加一个新的元素item到栈顶 pop() 弹出栈顶元素 peek() 返回栈顶元 ...
- 【数据结构与算法Python版学习笔记】树——利用二叉堆实现优先级队列
概念 队列有一个重要的变体,叫作优先级队列. 和队列一样,优先级队列从头部移除元素,不过元素的逻辑顺序是由优先级决定的. 优先级最高的元素在最前,优先级最低的元素在最后. 实现优先级队列的经典方法是使 ...
- 【数据结构与算法Python版学习笔记】树——平衡二叉搜索树(AVL树)
定义 能够在key插入时一直保持平衡的二叉查找树: AVL树 利用AVL树实现ADT Map, 基本上与BST的实现相同,不同之处仅在于二叉树的生成与维护过程 平衡因子 AVL树的实现中, 需要对每个 ...
随机推荐
- iostat (转https://www.cnblogs.com/ftl1012/p/iostat.html)
iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视.它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况.iostat也有一个弱 ...
- TCP通信的文件上传案例
- Yarn 资源调度器
1. 概述 YARN 是一个资源调度平台,负责为运算程序提供服务器运算资源: YARN 由ResourceManager,NodeManager, ApplicationMaster 和 Contai ...
- [转帖]微软宣布即将开始大规模推送Windows 10 V1903重大版本更新
微软宣布即将开始大规模推送Windows 10 V1903重大版本更新 https://www.cnbeta.com/articles/tech/894303.htm 微软要批量更新 1903了 bu ...
- 【LOJ】#2720. 「NOI2018」你的名字
题解 把S串建一个后缀自动机 用一个可持久化权值线段树维护每个节点的right集合是哪些节点 求本质不同的子串我们就是要求T串中以每个点为结束点的串有多少在\(S[l..r]\)中出现过 首先我们需要 ...
- python学习-16 列表list
list 1.由[ ]括住,中括号内各元素由逗号隔开,各元素可以是数字,字符串,列表,布尔值等等. 例如: li = [521,"love",["john",& ...
- 怎样给回调函数绑定this
在三种绑定this的方法中, Function.prototype.call() 和 Function.prototye.apply() 都是会立即执行该函数的, 但回调函数是不能立即执行的, 它只是 ...
- Bootstrap3 CDN 使用手册
一.一般功能 <link href="https://cdn.bootcss.com/bootstrap/3.3.7/css/bootstrap.css" rel=" ...
- 洛谷 P1307 数字反转
链接:https://www.luogu.org/problem/P1307 题目: 题目描述 给定一个整数,请将该数各个位上数字反转得到一个新数.新数也应满足整数的常见形式,即除非给定的原数为零,否 ...
- sql语句分页多种方式
sql语句分页多种方式ROW_NUMBER()OVER sql语句分页多种方式ROW_NUMBER()OVER 2009年12月04日 星期五 14:36 方式一 select top @pageSi ...