python 垃圾回收笔记
python 程序在运行的时候,需要在内存中开辟出一块空间,用于存放运行时产生的临时变量;计算完成后,再将结果输出到永久性存储器中。如果数量过大,
内存空间管理不善,就会出现 OOM(out of memory), 俗称爆内存,程序可能被操作系统终止。
引用计数
Python 中一切皆对象。因此,一切变量,本质上都是对象的一个指针。
import os
import psutil
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid() # 进程ID
p = psutil.Process(pid) # 返回进程对象,不传 pid 默认会获取当前的pid
info = p.memory_full_info() # pfullmem 对象
memory = info.uss / 1024. / 1024
print(f'{hint} memory used: {memory} MB')
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
func()
show_memory_info('finished')
"""
运行结果:
initial memory used: 8.32421875 MB
after a created memory used: 396.21484375 MB
finished memory used: 9.0078125 MB
"""
示例中调用函数 func(), 在列表 a 被创建之后,内存占用迅速增加到了 396MB, 而在函数调用之后,内存返回正常。
这是因为函数内部声明的列表a是局部变量,在函数返回后,局部变量的引用会注销掉;此时,列表a所指代对象的引用计数为0,python便会执行垃圾
回收,因此之前占用的大量内存被释放了。
import os
import psutil
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process()
info = p.memory_full_info()
memory = info.uss / 1024 / 1024
print(f'{hint} memory used: {memory} MB')
def func():
show_memory_info('initial')
global a
a = [i for i in range(10000000)]
show_memory_info('after a created')
func()
show_memory_info('finished')
"""
运行结果:
initial memory used: 8.4765625 MB
after a created memory used: 395.86328125 MB
finished memory used: 395.86328125 MB
"""
global a 将 a 声明为全局变量。那么,即使函数返回后,列表的引用依然存在,于是对象就不会被垃圾回收掉,依然占用大量内存。
同样,如果我们把生成的列表返回,然后在主程序中接收,那么引用依然存在,垃圾回收就不会触发,大量内存仍然被占用着:
def func():
show_memory_info('initial')
a = [i for i in derange(10000000)]
show_memory_info('after a created')
return a
a = func()
show_memory_info('finished')
这是最常见的几种情况。
python内部的引用计数机制
import sys
a = []
# 两次引用,一次来自 a,一次来自 getrefcount
print(sys.getrefcount(a))
def func(a):
# 四次引用,a,python 的函数调用栈,函数参数,和 getrefcount
print(sys.getrefcount(a))
func(a)
# 两次引用,一次来自 a,一次来自 getrefcount,函数 func 调用已经不存在
print(sys.getrefcount(a))
sys.getrefcount() 这个函数,可以查看一个变量的引用计数。它本身也会引入一次计数。
在函数调用时,会产生额外的两次引用,一个来自函数栈,一个来自函数参数。
import sys
a = []
print(sys.getrefcount(a)) # 两次
b = a
print(sys.getrefcount(a)) # 三次
c = b
d = b
e = c
f = e
g = d
print(sys.getrefcount(a)) # 八次
理解了引用这个概念后,引用释放是一种非常自然和清晰的思想。相比C语言里,你需要使用free去手动释放内存,python 自带垃圾回收。
如果想手动回收可以先 del a 来删除一个对象;然后强制调用 gc.collect(),即可手动启动垃圾回收。
import gc
import os
import psutil
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024 / 1024
print(f'{hint} memory used: {memory} MB')
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
del a
gc.collect()
show_memory_info('finish')
引用计数为0是垃圾回收的充要条件么?
循环引用
如果有两个对象,它们互相引用,并且不再被别的对象引用,那么它们应该被垃圾回收么?(python自带的不会,手动却可以)
import os
import psutil
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024 / 1024
print(f'{hint} memory used: {memory} MB')
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a, b created')
a.append(b)
b.append(a)
func()
show_memory_info('finished')
"""
运行结果:
initial memory used: 8.48046875 MB
after a, b created memory used: 783.83203125 MB
finished memory used: 783.83203125 MB
"""
这里 a 和 b 互相引用,并且,作为局部变量,在函数 func 调用结束后,a 和 b 这两个指针从程序意义上已经不存在了。但是,很明显,依然有内存
占用。因为互相引用,导致它们的引用数都不为0。
如果这段代码运行在生产环境中,哪怕 a 和 b 一开始占用的空间不是很大,但经过长时间的运行后,所占内存会越来越大,最终会撑爆服务器。
互相引用还是很容易发现的,更隐蔽的情况是出现一个引用环,在工程代码比较复杂的情况下,引用环很难被发现。
解决这类问题,我们可以通过手动垃圾回收,即显式的调用 gc.collect(), 来启动垃圾回收。
import gc
import os
import psutil
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024 / 1024
print(f'{hint} memory used: {memory} MB')
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a, b created')
a.append(b)
b.append(a)
func()
gc.collect() # 手动垃圾回收
show_memory_info('finished')
"""
运行结果:
initial memory used: 8.453125 MB
after a, b created memory used: 783.90625 MB
finished memory used: 9.37109375 MB
"""
虽然 a,b 的引用计数不为0,但是我们也可以通过 gc.collect() 进行垃圾回收
python 使用标记清除(mark-sweep)算法和分代收集(generational), 来启用针对循环引用的自动垃圾回收。
先来看看标记清除算法。我们先用图论来理解不可达的概念。对于一个有向图,如果从一个节点出发进行遍历,并标记其经过的所有节点;
那么,在遍历结束后,所有没有被标记的节点,我们称之为不可达节点。显然,这些节点的存在没有任何意义,我们就需要对它们进行垃圾回收。
当然,每次都遍历全图,对于python而言是一种巨大的性能浪费。所以在python垃圾回收实现中,mark-sweep 使用双向链表维护了一个数据结构,
并且只考虑容器类的对象(只有容器类对象才有可能产生循环引用)。
而分代收集算法,则是另一个优化手段。
python将所有对象分为三代。刚刚创立的对象是第0代;经过一次垃圾回收后,依然存在的对象,便会依次从上一代挪到下一代。而每一代启动自动垃圾
回收的阈值,则是可以单独指定的。当垃圾回收器中新增对象(新建的对象)减去删除对象(手动调用del删除的对象、函数运行结束释放的对象等)达到相应的阈值时,就会对这一代对象启动垃圾回收。
事实上,分代收集基于的思想是,新生的对象更有可能被垃圾回收,而存活更久的对象也有更高的概率继续存活。因此,通过这种做法,可以节约不少
计算量,从而提高python的性能。
引用计数是其中最简单的实现,引用计数并非充要条件。还有其他的可能性,比如循环引用就是其中之一。
调试内存泄漏
虽然有了自动回收机制,还是会出现内存泄露的情况。
可以通过 objgraph(一个可视化引用关系的包)。在这个包中,主要关注两个函数,第一个是 show_refs(), 它可以生成清晰的引用关系图。
需要手动下载安装graphviz,然后将其 bin 目录放入到环境变量中,才能出来图片。在 jupyter notebook 中可以直接显示图片。但是在pycharm中
会显示图片地址,需要自己去手动打开。
通过下面这段代码和生成的引用调用图,你能非常直观的发现,有两个list互相引用,说明这里极有可能引起内存泄漏。这样一来,再去代码层排查就容易多了。
import objgraph
import os
os.environ["PATH"] += os.pathsep + r'D:\GoogleDownload\graphviz-2.38\release\bin'
a = [1, 2, 3]
b = [4, 5, 6]
a.append(b)
b.append(a)
objgraph.show_refs([a])
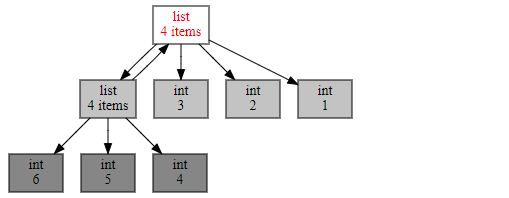
而另一个非常有用的函数是 show_backrefs()
import objgraph
import os
os.environ["PATH"] += os.pathsep + r'D:\GoogleDownload\graphviz-2.38\release\bin'
a = [1, 2, 3]
b = [4, 5, 6]
a.append(b)
b.append(a)
objgraph.show_backrefs([a])

这个代码显示的图片比之前的复杂的多。show_backrefs() 有很多有用的参数,比如层数限制(max_depth)、宽度限制(too_many)、输出格式控制(filename output)、
节点过滤(filter, extra_ignore)等。
总结
- 垃圾回收是 python 自带的机制,用于自动释放不会再用到的内存空间;
- 引用计数是其中最简单的实现,这只是充分非必要条件,因为循环引用需要通过不可达判定,来确定是否可以回收;
- Python 的自动回收算法包括标记清除和分代收集,主要针对的是循环引用的垃圾收集;
- 调试内存泄漏的工具:objgraph;
- 这只是皮毛。
python 垃圾回收笔记的更多相关文章
- Python垃圾回收机制--完美讲解!
转自: http://www.jianshu.com/p/1e375fb40506 先来个概述,第二部分的画述才是厉害的. Garbage collection(GC) 现在的高级语言如java,c# ...
- python垃圾回收机制与小整数池
python垃圾回收机制 当引用计数为0时,python会删除这个值. 引用计数 x = 10 y = x del x print(y) 10 引用计数+1,引用计数+1,引用计数-1,此时引用计数为 ...
- python垃圾回收机制:引用计数 VS js垃圾回收机制:标记清除
js垃圾回收机制:标记清除 Js具有自动垃圾回收机制.垃圾收集器会按照固定的时间间隔周期性的执行. JS中最常见的垃圾回收方式是标记清除. 工作原理 当变量进入环境时,将这个变量标记为"进入 ...
- python 垃圾回收
# 垃圾回收 # 小整数对象池 # a = 100# python对小整数的定义是[-5,257],这些证书对象是提前创建好的,不会被垃圾回收,再一个python的程序中,所有位于这个范围内的正式使用 ...
- python垃圾回收
python垃圾回收 python垃圾回收主要使用引用计数来跟踪和回收垃圾.在引用计数的基础上,通过“标记—清除”解决容器对象可能产生的循环引用问题,通过“分代回收”以空间换时间的方法提高垃圾回收效率 ...
- 《垃圾回收的算法与实现》——Python垃圾回收
Python垃圾回收 python采用引用计数法进行垃圾回收 Python内存分配 python在分配内存空间时,在malloc之上堆放了3个独立的分层. python内存分配时主要由arena.po ...
- python垃圾回收机制(Garbage collection)
由于面试中遇到了垃圾回收的问题,转载学习和总结这个问题. 在C/C++中采用用户自己管理维护内存的方式.自己管理内存极其自由,可以任意申请内存,但也为大量内存泄露.悬空指针等bug埋下隐患. 因此在现 ...
- python 垃圾回收详解
原文:https://zhuanlan.zhihu.com/p/31150408 总纲 策略和垃圾回收系统工作内容 引用计数详解 标记-清除+分代收集 循环引用 编程应用-常见方法 ex 过程详解 使 ...
- python垃圾回收算法
标准python垃圾回收器由两部分组成,即引用计数回收器和分代垃圾回收器(即python包中的gc module).其中,引用计数模块不能被禁用,而GC模块可以被禁用. 引用计数算法 python中每 ...
随机推荐
- Jmeter之JSON Path Extractor的使用(JSON-handle下载安装和使用)
jp@gc - JSON Path Extractor和“正则表达式提取器”使用效果一样. 他的作用单一,只提取json数据 jp@gc - JSON Path Extracto 变量名自己定义,js ...
- 手把手教你写一个windows服务 【基于.net】 附实用小工具{注册服务/开启服务/停止服务/删除服务}
1,本文适用范围 语言:.net 服务类型:windows服务,隔一段时间执行 2,服务搭建: 1,在vs中创建 console程序 2,在console项目所在类库右键 添加-新建项-选择Windo ...
- js摄像头
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8& ...
- VBA学习资料分享-1
近年来,人工智能的概念深入人心,许多企业也正逐步或已推行办公自动化,寻求人力时间成本的降低,从而提升效益.对企业来说,要完全使用人工智能将工作流程自动化恐怕是没那么容易的,可以的话成本也不低,所以使用 ...
- .net core默认不支持gb2312
采集数据时,乱码,之前遇到过这个情况,于是老办法: 果断使用Encoding.GetEncoding(“GB2312”),抛异常.搜了下,是因为.net core默认不支持gb2312 所以,两个办法 ...
- js的一些兼容融性问题
1.非行内样式获取 高级浏览器 getComputedStyle(obox.false)//获取所有属性 ie浏览器 box.currentStyle//获取所有属性 兼容写法 function ge ...
- 80C51串行口
串行通信是指 使用一条数据线,将数据一位一位地依次传输,每一位数据占据一个固定的时间长度 单工.半双工.全双工 单工数据传输只支持数据在一个方向上传输 半双工数据传输允许数据在两个方向上传输,但是,在 ...
- redis—持久化操作
简介 Redis是一种高级key-value数据库.它跟memcached类似,不过数据可以持久化,而且支持的数据类型很丰富.有字符串,链表,集 合和有序集合.支持在服务器端计算集合的并,交和补集(d ...
- Linux学习笔记(四)Linux常用命令:帮助命令
一.帮助命令man [man] [命令] 例如: man ls man的级别 man -f [命令] 相当于 whereis [命令] 可查看该命令有几个等级,进而可以通过 man [等级数] [ ...
- PMM 监控 MySQL
Percona Monitoring and Management (PMM)是一款开源的用于监控 MySQL 和 MongoDB 性能的开源平台,通过 PMM 客户端收集到的 DB 监控数据用第三方 ...