Flume-概述
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。
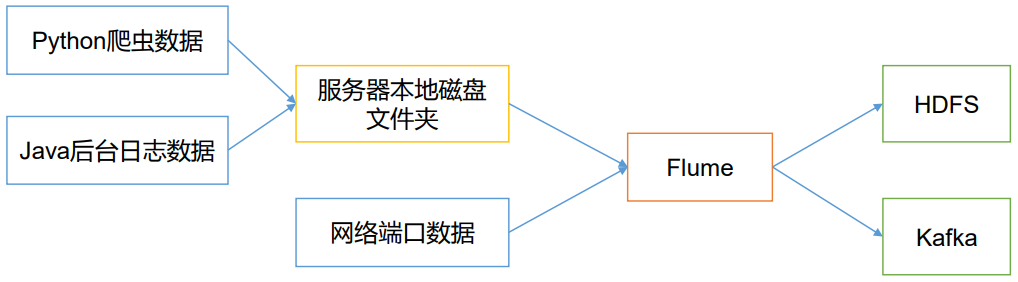
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
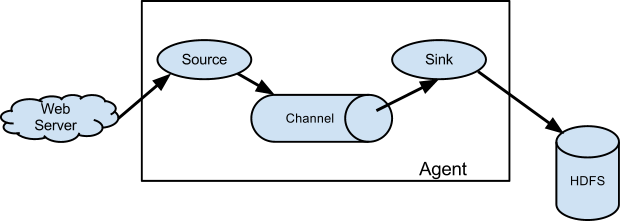
一、架构
https://flume.apache.org/FlumeUserGuide.html#data-flow-model
二、组件
1.Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent 主要有 3 个部分组成,Source、Channel、Sink。
2.Source
https://flume.apache.org/FlumeUserGuide.html#flume-sources
Source 是负责接收数据到 Flume Agent 的组件。
Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
3.Sink
https://flume.apache.org/FlumeUserGuide.html#flume-sinks
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
4.Channel
https://flume.apache.org/FlumeUserGuide.html#flume-channels
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运 作在不同的速率上。
Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个 Sink 的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel 以及 Kafka Channel。 Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适 用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕 机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
5.Event
传输单元,Flume 数据传输的基本单元,以 Event 的形式将数据从源头送至目的地。Event 由 Header 和 Body 两部分组成,Header 用来存放该 event 的一些属性,为 K-V 结构,Body 用来存放该条数据,形式为字节数组。

Flume-概述的更多相关文章
- Flume概述和简单实例
Flume概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方( ...
- Flume 概述/企业案例
概述 1 Flume定义 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统.Flume基于流式架构,灵活简单. 下面我们来详细介绍一下Flume架构中的 ...
- Flume 概述+环境配置+监听Hive日志信息并写入到hdfs
Flume介绍Flume是Apache基金会组织的一个提供的高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供 ...
- 1.flume概述
我们的web服务器等等每天会产生大量的日志,我们要把这些日志收集起来,移动到hadoop平台上进行分析. 那么如何移动这些数据呢?一种方法是通过shell cp到hadoop集群上,然后通过hdfs ...
- Flume概述
flume是分布式的,可靠的,用于从不同的来源有效收集 聚集 和 移动 大量的日志数据用以集中式的数据存储的系统. 是apache的一个顶级项目. 系统需求:jdk1.6以上,推荐java1.7
- Flume的概述和安装部署
一.Flume概述 Flume是一种分布式.可靠且可用的服务,用于有效的收集.聚合和移动大量日志文件数据.Flume具有基于流数据流的简单灵活的框架,具有可靠的可靠性机制和许多故障转移和恢复机制,具有 ...
- 大数据技术之_09_Flume学习_Flume概述+Flume快速入门+Flume企业开发案例+Flume监控之Ganglia+Flume高级之自定义MySQLSource+Flume企业真实面试题(重点)
第1章 Flume概述1.1 Flume定义1.2 Flume组成架构1.2.1 Agent1.2.2 Source1.2.3 Channel1.2.4 Sink1.2.5 Event1.3 Flum ...
- Hadoop应用开发实战(flume应用开发、搜索引擎算法、Pipes、集群、PageRank算法)
Hadoop是2013年最热门的技术之一,通过北风网robby老师<深入浅出Hadoop实战开发>.<Hadoop应用开发实战>两套课程的学习,普通Java开发人员可以在最快的 ...
- [ETL] Flume 理论与demo(Taildir Source & Hdfs Sink)
一.Flume简介 1. Flume概述 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据: ...
- 学习笔记:分布式日志收集框架Flume
业务现状分析 WebServer/ApplicationServer分散在各个机器上,想在大数据平台hadoop上进行统计分析,就需要先把日志收集到hadoop平台上. 思考:如何解决我们的数据从其他 ...
随机推荐
- 解决 vue 使用 element 时报错ERROR in ./node_modules/element-ui/lib/theme-chalk/fonts/element-icons.ttf
在 webpack.config.js 中加入这个依赖 { test: /\.(eot|svg|ttf|woff|woff2)(\?\S*)?$/, loader: 'file-loader' }
- jmeter连接mysql数据库进行多条语句查询
前提工作: 1.在jmeter官网下载jmeter包(官网地址:https://jmeter.apache.org/).此外还需下载mysql驱动包,如:mysql-connector-java-5. ...
- 【Day4】3.urllib模块使用案例
import urllib.request as ur ret = ur.urlopen('https://edu.csdn.net/').read() with open('edu.html','w ...
- 去掉行尾的^M
1. 处理掉行尾的^M 在windos下进行linux内核驱动编写,调试成功后需要集成到内核代码中去,所以会通过虚拟机共享文件夹拷贝到内核对应目录,这时候看源码文件还是没有异常的. 当对该文件进行回车 ...
- Maven 依赖的作用域
Maven的一个哲学是惯例优于配置(Convention Over Configuration), Maven默认的依赖配置项中,scope的默认值是compile,项目中经常傻傻的分不清,直接默认了 ...
- SQL SERVER 常用函数 学习笔记
1.字符串截取.字符串转数字 --Server.8.30 select SUBSTRING('SqlServer_2008',4,6) as DB, CONVERT(float,SUBSTRING(' ...
- python学习笔记:安装boost python库以及使用boost.python库封装
学习是一个累积的过程.在这个过程中,我们不仅要学习新的知识,还需要将以前学到的知识进行回顾总结. 前面讲述了Python使用ctypes直接调用动态库和使用Python的C语言API封装C函数, C+ ...
- 用命令行的方式把jmeter结果文件JTL生成csv格式的聚合报告
我们知道 利用jmeter 的GUI的 Aggragate Listner 很容易把一个JTL 文件另存为CSV 文件,该CSV 文件中自动分析了 Transactions 的 90%, Median ...
- Matlab---读取 .txt文件
Matlab读取 .txt文件 这里提供两种方法:1,load()函数.2,importdata()函数. ---------------------------------------------- ...
- MNPR--造福人类的人值得被感激
https://artineering.io/research/MNPR/ https://mnpr.artineering.io https://pdfs.semanticscholar.org/0 ...