selenium入门学习
在写爬虫的学习过程中,经常会有一些动态加载,有些是可以动过接口直接获取到,但是实在没办法,所以学习下selenium。
首先百度一下:
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
首先下载:
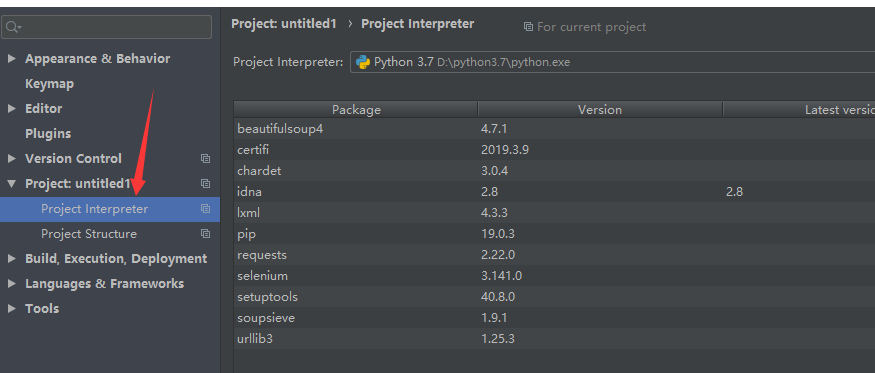
二: 下载chromedriver
找到本地chrome版本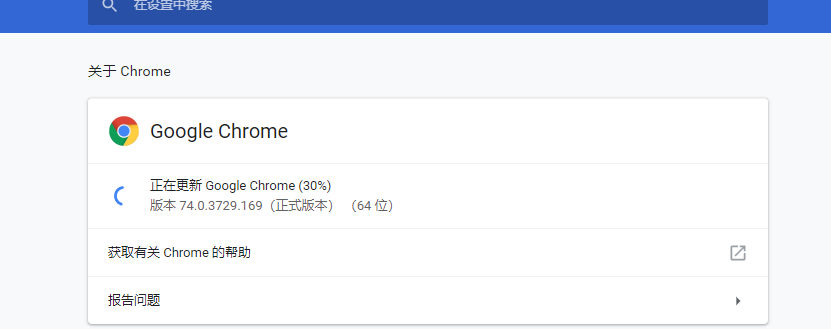
去队员的driver网站 http://npm.taobao.org/mirrors/chromedriver/ 下载(注意这里的win32兼容64位的)

接下来执行一小段代码

报错:
TypeError: 'module' object is not callable
解决办法
chrome-->Chrome 再次执行还是报错

解决办法,吧二进制包放到python家目录下面

或者
driver=webdriver.Chrome ('D:\python3.7\chromedriver') 写绝对路径
环境安装好了之后,一下是个基本应用:
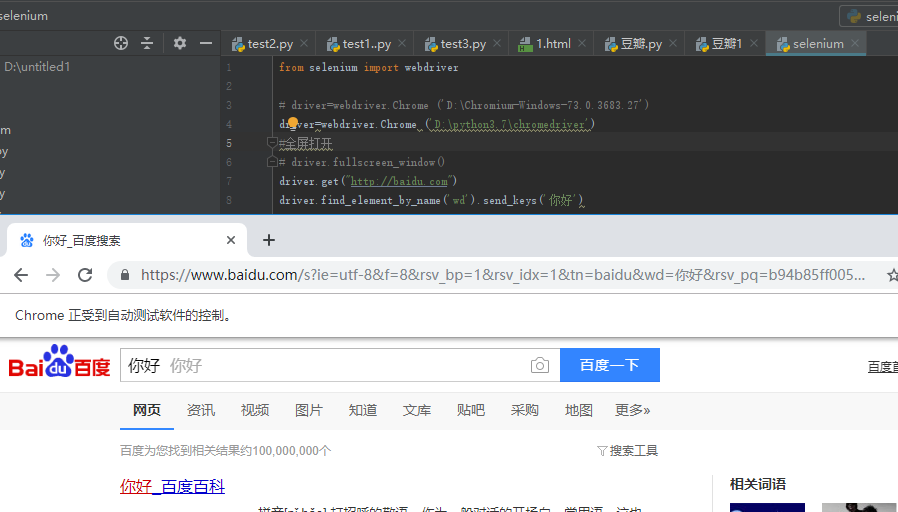
driver.quit()退出浏览器
elements=driver.find_elements_by_link_text("a")
for elment in elements:
if "新闻" in elment.test:
elment.clink()
elements=driver.find_elements_by_link_text("贴吧").click()
driver.back()
driver.find_element_by_partial_link_text("贴").click()driver.find_element_by_name('wd').send_keys('你好 \n')
driver.quit()
from selenium import webdriver # driver=webdriver.Chrome ('D:\Chromium-Windows-73.0.3683.27')
driver=webdriver.Chrome ('D:\python3.7\chromedriver')
#全屏打开
# driver.fullscreen_window()
driver.get("http://baidu.com")
#获取页面头部
baiduTitle = driver.title
print(baiduTitle)
#获取 带钱的url
currentUrl = driver.current_url
print(currentUrl)
# 页面刷新
driver.refresh()
#打开另一个url
driver.get("https://google.com")
#后退
driver.back()
#获取页面源代码
pageSource=driver.page_source
selenium入门学习的更多相关文章
- python3+selenium入门01-环境搭建
作为一个测试,在最近两年应该有明显的感觉.那就是工作变的难找,要求变的高了,自动化测试,性能测试等.没有自动化测试能力,只会点点点工作难找不说,工资也不高.所以还是要学习一些技术.首先要学习一门编程语 ...
- 自动化测试Java一:Selenium入门
From: https://blog.csdn.net/u013258415/article/details/77750214 Selenium入门 欢迎阅读Selenium入门讲义,本讲义将会重点介 ...
- Selenium自动化测试Python一:Selenium入门
Selenium入门 欢迎阅读Selenium入门讲义,本讲义将会重点介绍Selenium的入门知识以及Selenium的前置知识. 自动化测试的基础 在Selenium的课程以前,我们先回顾一下软件 ...
- vue入门学习(基础篇)
vue入门学习总结: vue的一个组件包括三部分:template.style.script. vue的数据在data中定义使用. 数据渲染指令:v-text.v-html.{{}}. 隐藏未编译的标 ...
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- PyQt4入门学习笔记(三)
# PyQt4入门学习笔记(三) PyQt4内的布局 布局方式是我们控制我们的GUI页面内各个控件的排放位置的.我们可以通过两种基本方式来控制: 1.绝对位置 2.layout类 绝对位置 这种方式要 ...
- PyQt4入门学习笔记(一)
PyQt4入门学习笔记(一) 一直没有找到什么好的pyqt4的教程,偶然在google上搜到一篇不错的入门文档,翻译过来,留以后再复习. 原始链接如下: http://zetcode.com/gui/ ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
随机推荐
- go get命令在go mod目录下与正常目录执行的区别
转载自https://www.jianshu.com/p/0a2ebb07da54 非$GOPATH目录下的go mod项目 $ go mod init test $ cat go.mod modul ...
- 加密算法之 MD5算法
题记:本人自测了很多次,该算法和apache的commons utils包中的MD5算法计算一致 一.针对文件内容生成MD5值 应用场景:针对文件,在传输过程由于网络原因丢帧或者被人别恶意篡改内容,可 ...
- springboot2.0数据制作为excel表格
注意:由于公司需要大量导出数据成excel表格,因此在网上找了方法,亲测有效. 声明:该博客参考于https://blog.csdn.net/long530439142/article/details ...
- visual studio 2019 中初始化 vue.js 项目
vs项目模板,webpack模板的创建方式在vs里创建后,npm install的过程会卡很久,暂时原因不明,感觉应该是文件太多,需要写入太多零碎文件. 试了几种初始化方法,还是用最新cli创建最好, ...
- python programming作业11 Qt designer (打地鼠,不是很完美)
不导包的代码 from PyQt5 import QtCore, QtGui, QtWidgets import sys from PyQt5.QtWidgets import QApplicati ...
- Excel不同版本差异性
apache poi-3.16.jar /* ==================================================================== Licensed ...
- python常见报错
1.Pycharm No module named requests 的解决方法 pip install requests 然后重启pycharm
- django 模板里面for循环和if常用的方法
django 模板里面for循环常用的方法 {% for %} 允许我们在一个序列上迭代.与Python的for 语句的情形类似,循环语法是 for X in Y ,Y是要迭代的序列而X是在每一个特定 ...
- Git命令与介绍
一. Git[命令与介绍] 1. 作用 可以用于个的项目版本控制和管理 目前多用于团队间的多人协作项目开发 2. 安装 l 安装包路径 l 安装 后的路径: 3. 工作流程 (1) 创建项目目录 在路 ...
- 如何在google colab加载kaggle数据
参考https://medium.com/@yvettewu.dw/tutorial-kaggle-api-google-colaboratory-1a054a382de0 从本地上传到colab上十 ...