Kafka集群安裝部署(自带Zookeeper)
kafka简介
kafka官网:http://kafka.apache.org/
kafka下载页面:http://kafka.apache.org/downloads
kafka配置快速入门:http://kafka.apache.org/quickstart
新版本的kafka自带有zookeeper,本篇文章记录使用自带zookeeper搭建kafka集群。
為了實現高可用,高吞吐量,kafka以集群方式部署,分別在3臺服務器上安裝部署,因kafka依賴於zookeeper,如果想要使用Kafka,就必须安装ZK,Kafka中的消费偏置信息、kafka集群、topic信息会被存储在ZK中。
這裏採用kafka內置的zookeeper,也是以集群方式部署,無需在單獨安裝zookeeper。
首先让我们看几个基本的消息系统术语:
•Kafka将消息以topic为单位进行归纳。
•将向Kafka topic发布消息的程序成为producers.
•将预订topics并消费消息的程序成为consumer.
•Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker.
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息,如下图所示:
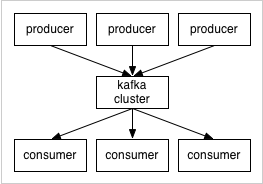
客户端和服务端通过TCP协议通信。Kafka提供了Java客户端,并且对多种语言都提供了支持。
环境准备
kafka版本:kafka_2.11-1.0.0.tgz
三台主机IP:172.16.10.91、172.16.10.92、172.16.10.93
安裝配置工作
1、kafka安裝
下载后解压kafka,将其解压到/usr/local目录下,删除压缩包即可:
tar xzvf kafka_2.11-1.0.0.tgz #解压
进入到kafka的config目录
自定义目录:
首先新建kafka的日志目录和zookeeper数据目录,因为这两项默认放在tmp目录,而tmp目录中内容会随重启而丢失,所以我们自定义以下目录:
mkdir /usr/local/kafka_2.-1.0./zookeeper #创建zookeeper数据目录
mkdir /usr/local/kafka_2.-1.0./log #创建日志目录
mkdir /usr/local/kafka_2.-1.0./log/zookeeper #创建zookeeper日志目录
mkdir /usr/local/kafka_2.-1.0./log/kafka #创建kafka日志目录
2、zookeeper配置
> 修改 zookeeper.properties
进入config目录下,修改关键配置如下,3台服务器的zookeeper.properties配置文件都一样
#修改为自定义的zookeeper数据目录
dataDir=/usr/local/kafka_2.-1.0./zookeeper #修改为自定义的zookeeper日志目录
dataLogDir=/usr/local/kafka_2.-1.0./log/zookeeper # 端口
clientPort= #注释掉
#maxClientCnxns= #设置连接参数,添加如下配置
tickTime=2000 #为zk的基本时间单元,毫秒
initLimit=10 #Leader-Follower初始通信时限 tickTime*10
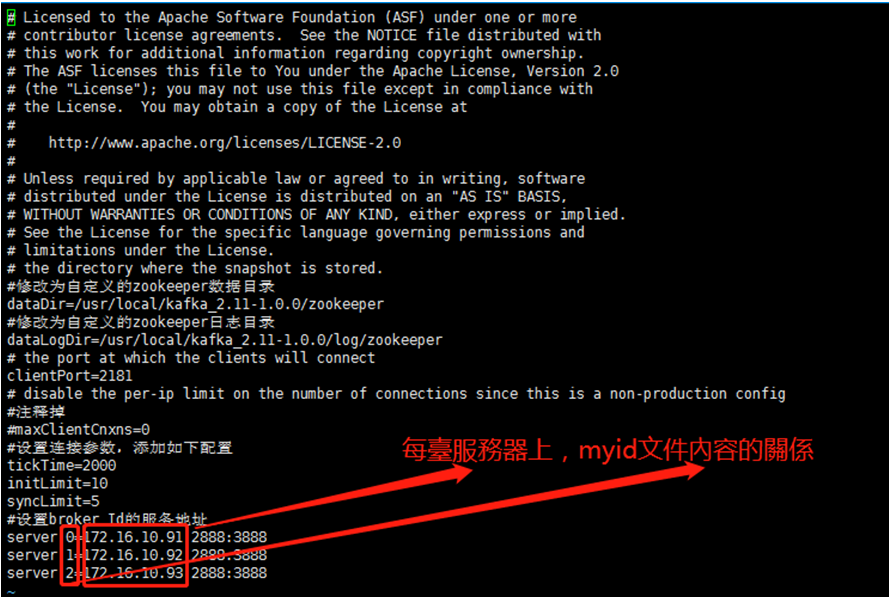
syncLimit=5 #Leader-Follower同步通信时限 tickTime*5 #设置broker Id的服务地址
server.=172.16.10.91::
server.=172.16.10.92::
server.=172.16.10.93::
> zookeeper数据目录添加myid配置
在各台服务器的zookeeper数据目录【/usr/local/kafka_2.11-1.0.0/zookeeper】添加myid文件,写入服务broker.id属性值
如这里的目录是/usr/local/kafka_2.11-1.0.0/zookeeper
注:3臺服務器都要添加myid文件,但值的內容不一樣,具體關係請見下圖:
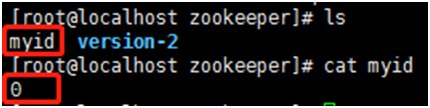
例如:第一台broker.id为0的服务到该目录【/usr/local/kafka_2.11-1.0.0/zookeeper】下执行以下命令,會生成myid文件內容
[root@mmc config]# echo 0 > myid
3、kafka配置
进入config目录下,修改server.properties文件
注:3臺服務器都要配置,其中【broker.id、advertised.listeners】不一樣,其它配置都一樣
############################# Server Basics #############################
# broker 的全局唯一编号,不能重复
broker.id=1 ############################# Socket Server Settings #############################
# 配置监听,修改为本机ip
advertised.listeners=PLAINTEXT://172.16.10.91:9092 # 处理网络请求的线程数量,默认
num.network.threads= # 用来处理磁盘IO的线程数量,默认
num.io.threads= # 发送套接字的缓冲区大小,默认
socket.send.buffer.bytes= # 接收套接字的缓冲区大小,默认
socket.receive.buffer.bytes= # 请求套接字的缓冲区大小,默认
socket.request.max.bytes= ############################# Zookeeper #############################
# 配置三台服务zookeeper连接地址
zookeeper.connect=172.16.10.91:2181,172.16.10.92:2181,172.16.10.93:2181 ############################# Log Basics #############################
# kafka 运行日志存放路径
log.dirs=/usr/local/kafka_2.11-1.0.0/log/kafka # topic 在当前broker上的分片个数,与broker保持一致
num.partitions=3 # 用来恢复和清理data下数据的线程数量,默认
num.recovery.threads.per.data.dir= ############################# Log Retention Policy #############################
# segment文件保留的最长时间,超时将被删除,默认
log.retention.hours= # 滚动生成新的segment文件的最大时间,默认
log.roll.hours=
4、kafka启动
kafka启动时先启动zookeeper,再启动kafka;关闭时相反,先关闭kafka,再关闭zookeeper
- 進入kafka根目錄
[root@localhost kafka_2.-1.0.]# cd /usr/local/kafka_2.-1.0./
- 啟動zookeeper
輸入命令:
[root@localhostkafka_2.-1.0.]# bin/zookeeper-server-start.sh config/zookeeper.properties & #後臺啟動命令:
[root@localhostkafka_2.-1.0.]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties >log/zookeeper/zookeeper.log 2>1 &
查看log/zookeeper/zookeeper.log 文件,第1、2臺服務器啟動的時候,會報錯Connection refused,因為另外1、2臺服務器還沒啟動,先不用管它

查看log/zookeeper/zookeeper.log 文件,等3臺服務都啟動完後,就不在報錯了
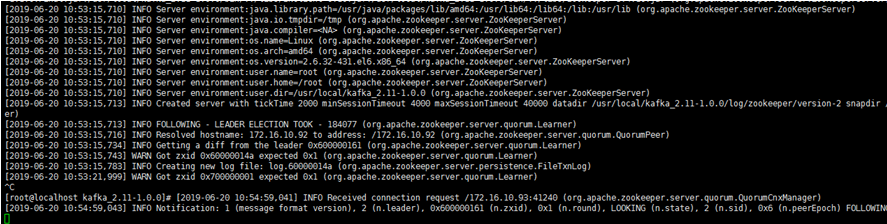
- 啟動kafka
輸入命令:
[root@localhostkafka_2.-1.0.]# bin/kafka-server-start.sh config/server.properties & #後臺啟動命令:
[root@localhostkafka_2.-1.0.]# nohup bin/kafka-server-start.sh config/server.properties >log/kafka/kafka.log 2>1 &
查看log/kafka/kafka.log 文件,啟動過程中沒有報錯,且有以下信息輸出,說明啟動成功

5、kafka测试验证
分别启动三台机器的zookeeper,三台机器的zookeeper都启动成功后,再分别启动三台机器的kafka。
- 進入kafka根目錄
[root@localhost kafka_2.-1.0.]# cd /usr/local/kafka_2.-1.0./
- 在某臺機器創建topic,名稱為test
[root@localhost kafka_2.11-1.0.0]# bin/kafka-topics.sh -create --zookeeper 172.16.10.91:2181,172.16.10.92:2181,172.16.10.93:2181 -replication-factor 3 --partitions 3 --topic test
命令解析:
--create: #指定创建topic动作
--topic: #指定新建topic的名称
--zookeeper: #指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样
--partitions 3 #指定当前创建的kafka分区数量,默认为1个
--replication-factor #指定每个分区的副本集数量,不能大于 broker 节点数量,多了也没用,1个节点放>=2个副本挂了都完蛋。

- 查看topic,确认topic创建成功
[root@localhost kafka_2.-1.0.]# bin/kafka-topics.sh --list --zookeeper 172.16.10.91:

- 查看topic,详细信息
[root@localhost kafka_2.-1.0.]# bin/kafka-topics.sh --describe --zookeeper 172.16.10.93: --topic test
可以描述为:Topic分区数/副本数/副本Leader/副本ISR等信息:

“leader”:该节点负责该分区的所有的读和写,每个节点的leader都是随机选择的。
“replicas”:备份的节点列表,无论该节点是否是leader或者目前是否还活着,只是显示。
“isr”:同步备份”的节点列表,也就是活着的节点并且正在同步leader
其中Replicas和Isr中的1,2,0就对应着3个broker他们的broker.id属性!
- 在某臺服務器上创建生产者
[root@localhost kafka_2.-1.0.]# bin/kafka-console-producer.sh --broker-list 172.16.10.91:,172.16.10.92:,172.16.10.93: --topic test

- 在另外两台服務器创建消费者
[root@localhost kafka_2.-1.0.]# bin/kafka-console-consumer.sh --zookeeper 172.16.10.91:,172.16.10.92:,172.16.10.93: --topic test --from-beginning
- 生產者服務器截圖

- 消費者服務器截圖

- 修改topic信息
bin/kafka-topics.sh --zookeeper 192.168.187.146: --alter --topic test --config max.message.bytes=
bin/kafka-topics.sh --zookeeper 192.168.187.146: --alter --topic test --delete-config max.message.bytes
bin/kafka-topics.sh --zookeeper 192.168.187.146: --alter --topic test --partitions
bin/kafka-topics.sh --zookeeper 192.168.187.146: --alter --topic test --partitions ## Kafka分区数量只允许增加,不允许减少
- 删除topic
注意,只是删除Topic在zk的元数据,日志数据仍需手动删除
[root@localhost kafka_2.-1.0.]# bin/kafka-topics.sh -delete --zookeeper 172.16.10.91:,172.16.10.92:,172.16.10.93: --topic test

Note: This will have no impact if delete.topic.enable is not set to true.## 默认情况下,删除是标记删除,没有实际删除这个Topic;如果运行删除Topic,两种方式:
方式一:通过delete命令删除后,手动将本地磁盘以及zk上的相关topic的信息删除即可
方式二:配置server.properties文件,给定参数delete.topic.enable=true,重启kafka服务,此时执行delete命令表示允许进行Topic的删除
- 查看kafka未消费的消息
[root@localhost kafka_2.11-1.0.0]# bin/kafka-console-consumer.sh --bootstrap-server 172.16.10.91:9092,172.16.10.92:9092,172.16.10.93:9092 --topic logstash-busi-2 --from-beginning

- 查看kafka消费進度
命令:bin/kafka-consumer-groups.sh --bootstrap-server <Kafka broker 连接信息> --describe --group <group 名称>
bin/kafka-consumer-groups.sh --bootstrap-server 172.16.10.91:9092,172.16.10.92:9092,172.16.10.93:9092 --describe --group terminalMonitor

6、kafka测试集群的容错能力
Kafka是支持容错的,下面我们来对Kafka的容错性进行测试,测试步骤如下
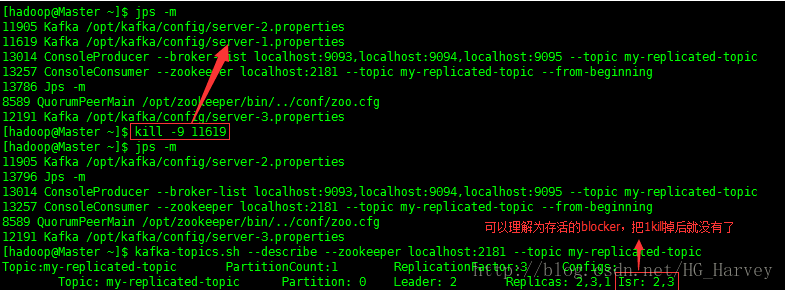
(1).查看topic的详细信息,观察那个blocker的角色是leader,那些blocker的角色是follower
[hadoop@Master ~]$ kafka-topics.sh --describe --zookeeper localhost: --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount: ReplicationFactor: Configs:
Topic: my-replicated-topic Partition: Leader: 2 Replicas: ,, Isr: ,,
(2).手工kill掉任意一个状态是follower的borker,测试生成和消费信息是否正确
步骤1中可以看到 2 为leader,1 和 3为 follower,将follower为1的进程kill掉
启动生产和消费者测试信息是否正确
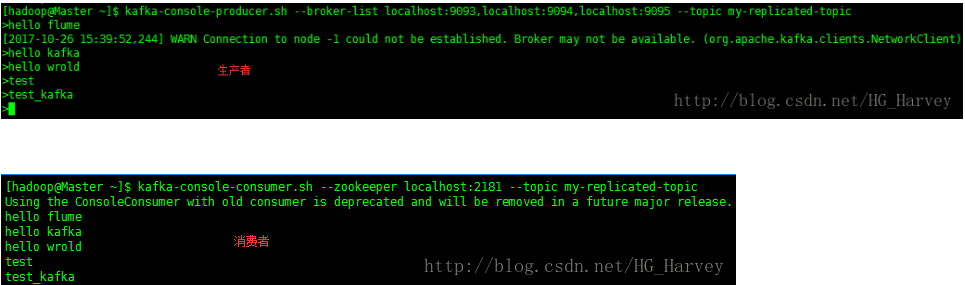
结论:kill掉任意一个状态是follower的broker,生成和消费信息正确,不受任何影响
(3).手工kill掉状态是leader的borker,测试生产和消费的信息是否正确
borker2的角色为leader,将它kill掉,borker 3变成了leader

启动生产和消费者测试信息是否正确
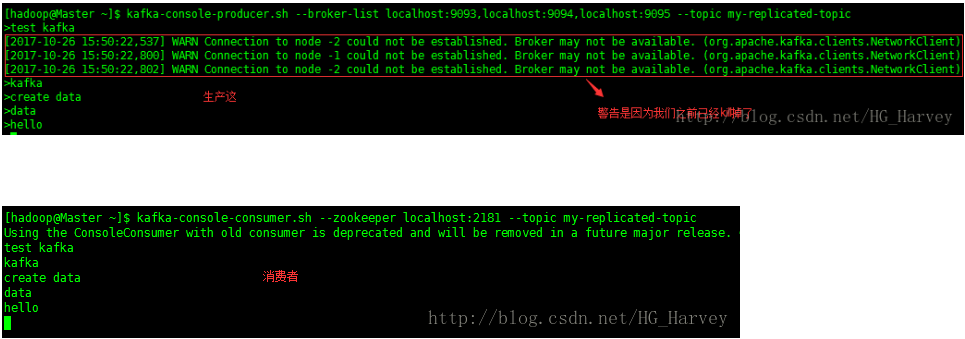
结论:kill掉状态是leader的borker,生产和消费的信息正确
总结:不管当前状态的borker是leader还是follower,当我们kill掉后,只要有一个borker能够正常使用,则消息仍然能够正常的生产和发送。即Kafka的容错性是有保证的!
Kafka集群安裝部署(自带Zookeeper)的更多相关文章
- kafka——集群安裝部署(自带zookeeper)
kafka系列文章 第一章 linux单机安装kafka 第二章 kafka--集群安裝部署(自带zookeeper) 一.kafka简介 kafka官网:http://kafka.apache.or ...
- centos7下kafka集群安装部署
应用摘要: Apache kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的 分布式发布订阅消息系统,是消息中间件的一种,用于构建实时 ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- kafka集群安全化之启用kerberos与acl
一.背景 在我们部署完kafka之后,虽然我们已经可以“肆意”的用kafka了,但是在一个大公司的实际生产环境中,kafka集群往往十分庞大,每个使用者都应该只关心自己所负责的Topic,并且对其他人 ...
- kafka集群安装部署
kafka集群安装 使用的版本 系统:centos6.5 centos6.7 jdk:1.7.0_79 zookeeper:3.4.9 kafka:2.10-0.10.1.0 一.环境准备[只列,不具 ...
- Kafka集群模式部署
环境:kafka 0.8.1.1 基本概念 Kafka维护按类区分的消息,称为主题(topic) 生产者(producer)向kafka的主题发布消息 消费者(consumer)向主题注册,并且接收发 ...
- kafka 集群的部署安装
这里我们罗列一下我们的环境 10.19.18.88 zk1 10.19.16.84 zk2 10.19.11.44 zk3 这里公司需要接入kafka用于zipkin来定位调用链 kafka 的地址是 ...
- bigdata_ Kafka集群模式部署
环境:kafka 0.8.1.1 基本概念 Kafka维护按类区分的消息,称为主题(topic) 生产者(producer)向kafka的主题发布消息 消费者(consumer)向主题注册,并且接收发 ...
- Kafka 集群安装部署
2.1 安装部署 2.1.1 集群规划 192.168.1.102 192.168.1.103 192.168.1.104 zookeeper zookeeper zookeeper kafka ka ...
随机推荐
- IIS 调试配置
- oracle学习1 基于oracle数据库的PLSQL编程以及存储过程的创建和使用视频
https://www.bilibili.com/video/av46777605 plsql中选择testWindow中可以进行测试 1.编写函数在plsql的testwindow中 begin d ...
- SQL Prompt 5 功能按键说明
1. Refresh suggestions 未知,按了没反映 2.Format sql 标准化SQL代码书 ...
- 使用SpringSession和Redis解决分布式Session共享问题
SpringSession优势 遵循servlet规范,同样方式获取session,对应用代码无侵入且对于developers透明化 关键点在于做到透明和兼容 接口适配:仍然使用HttpServlet ...
- HDU 5727 Necklace ( 2016多校、二分图匹配 )
题目链接 题意 : 给出 2*N 颗珠子.有 N 颗是阴的.有 N 颗是阳的.现在要把阴阳珠子串成一个环状的项链.而且要求珠子的放置方式必须的阴阳相间的.然后给出你 M 个限制关系.格式为 ( A.B ...
- Linux—查看远程Linux系统运行时间
[选择题]在Shell环境下,如何查看远程Linux系统运行了多少时间? A.scp user@被监控主机ip "uptime" B.ssh user@被监控主机ip " ...
- Linux下SHA256校验
一.将Hash: SHA256文件和需要检验的文件放在同一个文件夹内 二.$sha256sum -c SHA265 文件 输出: 校验文件:ok
- Android学习_数据持久化
数据持久化:将内存中的瞬时数据存储到设备中 1. 文件存储 存储一些简单的文本数据或二进制数据. 核心:Context类提供的openFileOutput()和openFileInput()方法,然后 ...
- Leetcode题目31.下一个排列(中等)
题目描述: 实现获取下一个排列的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列. 如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列). 必须原地修改,只允许使用额外 ...
- light4j轻量级微服务应用
最近对light-4j轻框架比较感兴趣,于是对现有应用做了一次重构,现将其间的一些点滴所得分享出来. 项目打包 pom.xml配置了两个profile:debug支持mvn exec:exec启动应用 ...