R语言与概率统计(三) 多元统计分析(下)广义线性回归
广义线性回归



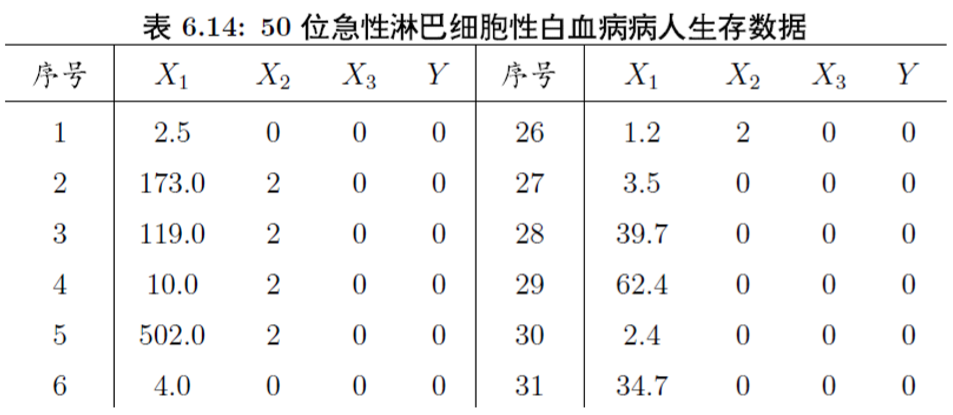

> life<-data.frame(
+ X1=c(2.5, 173, 119, 10, 502, 4, 14.4, 2, 40, 6.6,
+ 21.4, 2.8, 2.5, 6, 3.5, 62.2, 10.8, 21.6, 2, 3.4,
+ 5.1, 2.4, 1.7, 1.1, 12.8, 1.2, 3.5, 39.7, 62.4, 2.4,
+ 34.7, 28.4, 0.9, 30.6, 5.8, 6.1, 2.7, 4.7, 128, 35,
+ 2, 8.5, 2, 2, 4.3, 244.8, 4, 5.1, 32, 1.4),
+ X2=rep(c(0, 2, 0, 2, 0, 2, 0, 2, 0, 2, 0, 2, 0, 2, 0, 2,
+ 0, 2, 0, 2, 0, 2, 0),
+ c(1, 4, 2, 2, 1, 1, 8, 1, 5, 1, 5, 1, 1, 1, 2, 1,
+ 1, 1, 3, 1, 2, 1, 4)),
+ X3=rep(c(0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1),
+ c(6, 1, 3, 1, 3, 1, 1, 5, 1, 3, 7, 1, 1, 3, 1, 1, 2, 9)),
+ Y=rep(c(0, 1, 0, 1), c(15, 10, 15, 10))
+ )
> glm.sol<-glm(Y~X1+X2+X3, family=binomial, data=life)
> summary(glm.sol) Call:
glm(formula = Y ~ X1 + X2 + X3, family = binomial, data = life) Deviance Residuals:
Min 1Q Median 3Q Max
-1.6960 -0.5842 -0.2828 0.7436 1.9292 Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.696538 0.658635 -2.576 0.010000 **
X1 0.002326 0.005683 0.409 0.682308
X2 -0.792177 0.487262 -1.626 0.103998
X3 2.830373 0.793406 3.567 0.000361 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 67.301 on 49 degrees of freedom
Residual deviance: 46.567 on 46 degrees of freedom
AIC: 54.567 Number of Fisher Scoring iterations: 5
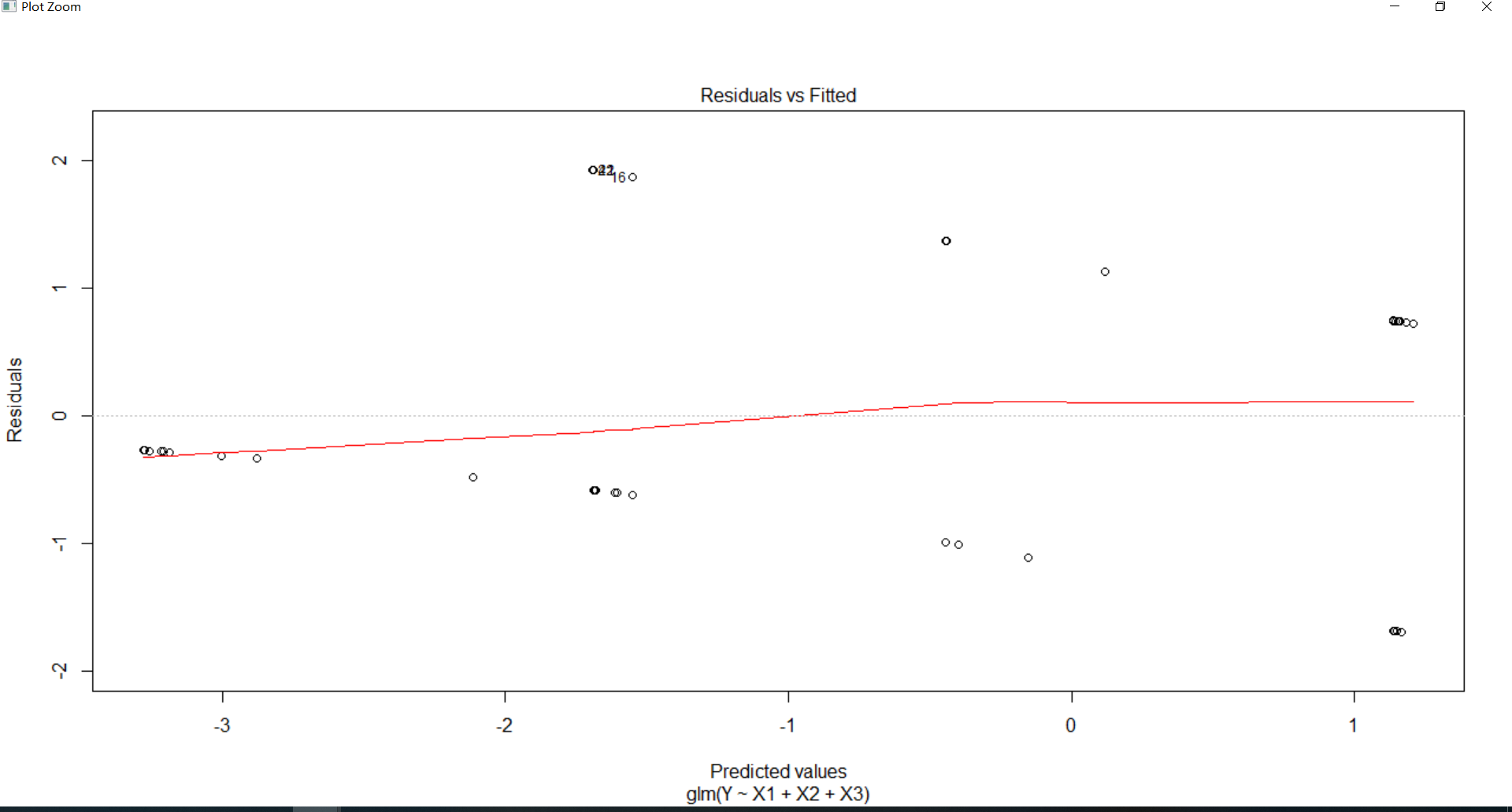

可见拟合的效果不好
> pre<-predict(glm.sol, data.frame(X1=5,X2=2,X3=0))
> p<-exp(pre)/(1+exp(pre));p#不接受治疗
1
0.03664087
>
> pre<-predict(glm.sol, data.frame(X1=5,X2=2,X3=1))
> p<-exp(pre)/(1+exp(pre));p#接受治疗
1
0.3920057
>
> step(glm.sol)
Start: AIC=54.57
Y ~ X1 + X2 + X3 Df Deviance AIC
- X1 1 46.718 52.718
<none> 46.567 54.567
- X2 1 49.502 55.502
- X3 1 63.475 69.475 Step: AIC=52.72
Y ~ X2 + X3 Df Deviance AIC
<none> 46.718 52.718
- X2 1 49.690 53.690
- X3 1 63.504 67.504 Call: glm(formula = Y ~ X2 + X3, family = binomial, data = life) Coefficients:
(Intercept) X2 X3
-1.642 -0.707 2.784 Degrees of Freedom: 49 Total (i.e. Null); 47 Residual
Null Deviance: 67.3
Residual Deviance: 46.72 AIC: 52.72
> glm.new<-update(glm.sol, .~.-X1)
> summary(glm.new) Call:
glm(formula = Y ~ X2 + X3, family = binomial, data = life) Deviance Residuals:
Min 1Q Median 3Q Max
-1.6849 -0.5949 -0.3033 0.7442 1.9073 Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.6419 0.6381 -2.573 0.010082 *
X2 -0.7070 0.4282 -1.651 0.098750 .
X3 2.7844 0.7797 3.571 0.000355 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 67.301 on 49 degrees of freedom
Residual deviance: 46.718 on 47 degrees of freedom
AIC: 52.718 Number of Fisher Scoring iterations: 5 >
> pre<-predict(glm.sol, data.frame(X1=5,X2=2,X3=0))
> p<-exp(pre)/(1+exp(pre));p#不接受治疗
1
0.03664087
>
> pre<-predict(glm.sol, data.frame(X1=5,X2=2,X3=1))
> p<-exp(pre)/(1+exp(pre));p#接受治疗
1
0.3920057
#####再来看一个类似的问题
install.packages('AER')
data(Affairs,package='AER')#婚外情数据,包括9个变量,婚外斯通频率,性别,婚龄等。
summary(Affairs)
table(Affairs$affairs)
#我们感兴趣的是是否有过婚外情所以做如下处理
Affairs$ynaffair[Affairs$affairs>0]<-1
Affairs$ynaffair[Affairs$affairs==0]<-0
Affairs$ynaffair<-factor(Affairs$ynaffair,levels=c(0,1),labels=c('NO','YES'))
table(Affairs$ynaffair)
#接下来做逻辑回归
fit.full=glm(ynaffair~.-affairs,data=Affairs,family=binomial())
summary(fit.full)
#除掉较大p值所对应的变量,如性别,是否有孩子、学历和职业在做一次分析
fit.reduced=glm(ynaffair~age+yearsmarried+religiousness+rating,data=Affairs,family=binomial())
summary(fit.reduced) AIC(fit.full,fit.reduced)#模型比较 #系数解释
exp(coef(fit.reduced))
R语言与概率统计(三) 多元统计分析(下)广义线性回归的更多相关文章
- R语言与概率统计(三) 多元统计分析(中)
模型修正 #但是,回归分析通常很难一步到位,需要不断修正模型 ###############################6.9通过牙膏销量模型学习模型修正 toothpaste<-data. ...
- R语言与概率统计(三) 多元统计分析(上)
> #############6.2一元线性回归分析 > x<-c(0.10,0.11,0.12,0.13,0.14,0.15,0.16,0.17,0.18,0.20,0.21,0. ...
- R语言与概率统计(一) 描述性统计分析
#查看已安装的包,查看已载入的包,查看包的介绍 ########例题3.1 #向量的输入方法 w<-c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 6 ...
- R语言与概率统计(二) 假设检验
> ####################5.2 > X<-c(159, 280, 101, 212, 224, 379, 179, 264, + 222, 362, 168, 2 ...
- R语言结合概率统计的体系分析---数字特征
现在有一个人,如何对这个人怎么识别这个人?那么就对其存在的特征进行提取,比如,提取其身高,其相貌,其年龄,分析这些特征,从而确定了,这个人就是这个人,我们绝不会认错. 同理,对数据进行分析,也是提取出 ...
- R语言与概率统计(六) 主成分分析 因子分析
超高维度分析,N*P的矩阵,N为样本个数,P为指标,N<<P PCA:抓住对y对重要的影响因素 主要有三种:PCA,因子分析,回归方程+惩罚函数(如LASSO) 为了降维,用更少的变量解决 ...
- R语言与概率统计(五) 聚类分析
#########################################0808聚类分析 X<-data.frame( x1=c(2959.19, 2459.77, 1495.63, ...
- R语言与概率统计(四) 判别分析(分类)
Fisher就是找一个线L使得组内方差小,组间距离大.即找一个直线使得d最大. ####################################1.判别分析,线性判别:2.分层抽样 #inst ...
- R语言︱数据分组统计函数族——apply族用法与心得
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:apply族功能强大,实用,可以代替 ...
随机推荐
- hibernate入门配置及第一个hibernate程序
学习了hibernate后就想先给大家分享一下它的配置方法: jar包导入 一.数据库表的创建 二.开启hibernate配置 编译器:eclipse 数据库:mysql 1.创建第一个xml文件 ...
- 牛客练习赛53 E 老瞎眼 pk 小鲜肉 (线段树,思维)
链接:https://ac.nowcoder.com/acm/contest/1114/E来源:牛客网 时间限制:C/C++ 2秒,其他语言4秒 空间限制:C/C++ 524288K,其他语言1048 ...
- wiki页面文本挖掘
import os,sysimport sysfrom bs4 import BeautifulSoupimport urllib.request# reload(sys)# sys.setdefau ...
- C++踩坑记录(一)std:;string的析构
之前写服务端程序有一个往消息队列里面推json的过程,然后发现推进去C#端取到的无论如何都是个空指针 简单复现一下现场 string str1 = string("hello1") ...
- [NOI2008]假面舞会——数论+dfs找环
原题戳这里 思路 分三种情况讨论: 1.有环 那显然是对于环长取个\(gcd\) 2.有类环 也就是这种情况 1→2→3→4→5→6→7,1→8→9→7 假设第一条链的长度为\(l_1\),第二条为\ ...
- python之select与selector
select/poll/epoll的区别 I/O多路复用的本质就是用select/poll/epoll,去监听多个socket对象. 参考:Linux IO模式及 select.poll.epoll详 ...
- 2018多校第九场 HDU 6416 (DP+前缀和优化)
转自:https://blog.csdn.net/CatDsy/article/details/81876341 #include <bits/stdc++.h> using namesp ...
- npm 镜像地址配置
1.查询当前镜像地址 npm get registry 2.修改镜像地址 npm config set registry http://registry.npm.taobao.org/ 原始镜像地址( ...
- webstorm 格式化代码及常用快捷键 Option+Command+l
mac 下 webstorm 格式化代码的快捷键 Option+Command+l
- 2019.6.20 校内测试 NOIP模拟 Day 1 分析+题解
这次是zay神仙给我们出的NOIP模拟题,不得不说好难啊QwQ,又倒数了~ T1 大美江湖 这个题是一个简单的模拟题. ----zay 唯一的坑点就是打怪的时候计算向上取整时,如果用ceil函数一 ...