spark 机器学习 ALS原理(一)
1.线性回归模型
线性回归是统计学中最常用的算法,当你想表示两个变量间的数学关系时,就可以用线性回归。当你使用它时,你首先假设输出变量(相应变量、因变量、标签)和预测变量(自变量、解释变量、特征)之间存在的线性关系。
(自变量是指:研究者主动操纵,而引起因变量发生变化的因素或条件,因此自变量被看作是因变量的原因。
因变量是指:在函数关系式中,某个量会随一个(或几个)变动的量的变动而变动。)
线性模型可能使用于类似下面的问题:比如你正在研究一个公司的销售额和该公司在广告上的投入之间的关系,或者某人在社交网站上的好友数量和他每天在该社交网站上花费的时间之间的关系。
理解线性回归一个切入点是先确定那条直线,我们知道,通过斜率和截距就可以完全确定一条直线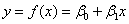
例子1:
假设 (用户数,利润值)
S={(x,y)=(1,25),(10,250),(100,2500)}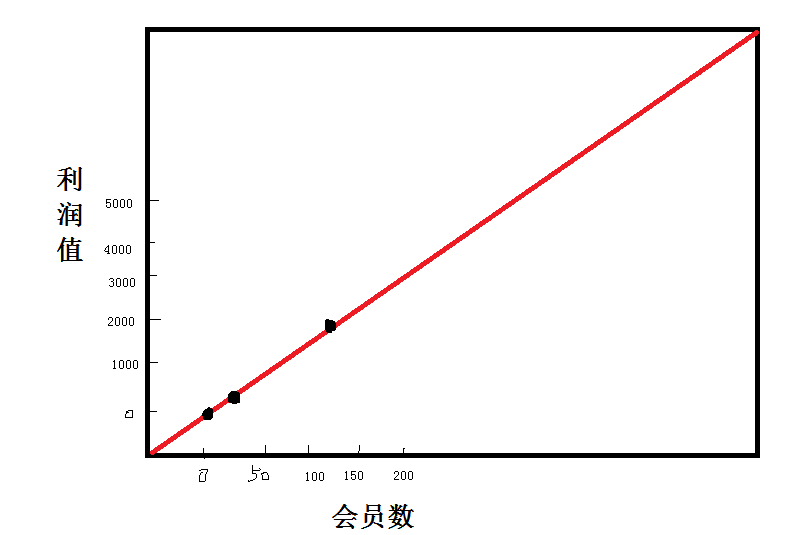
例子2:
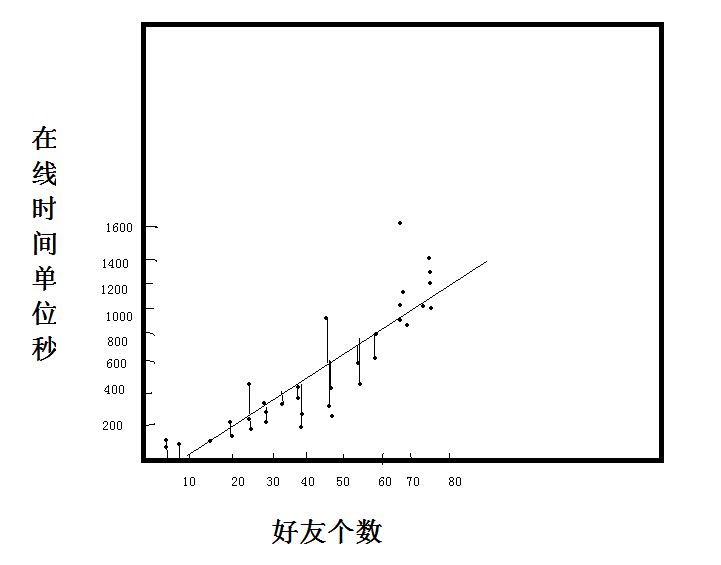
假设(好友数,在线时间)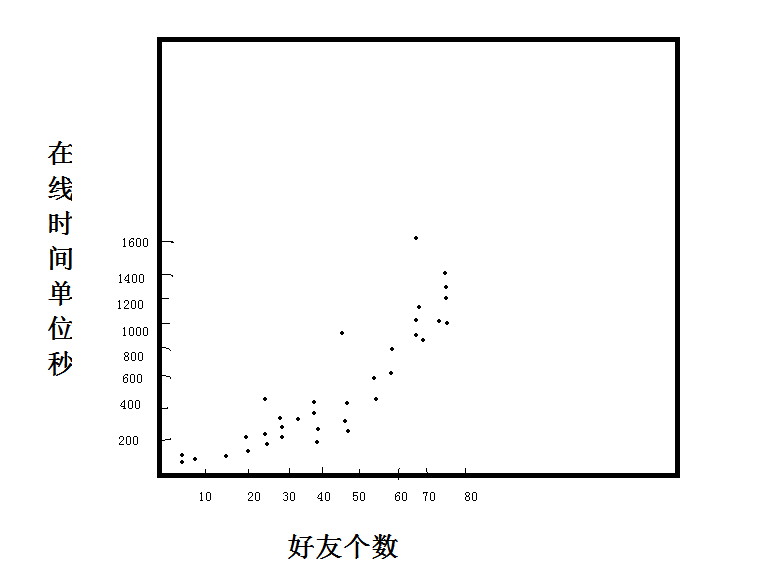
看到当前图片,很难一眼看出两个变量之间的关系了。
我们假设图中是线性关系,可以画出多条线。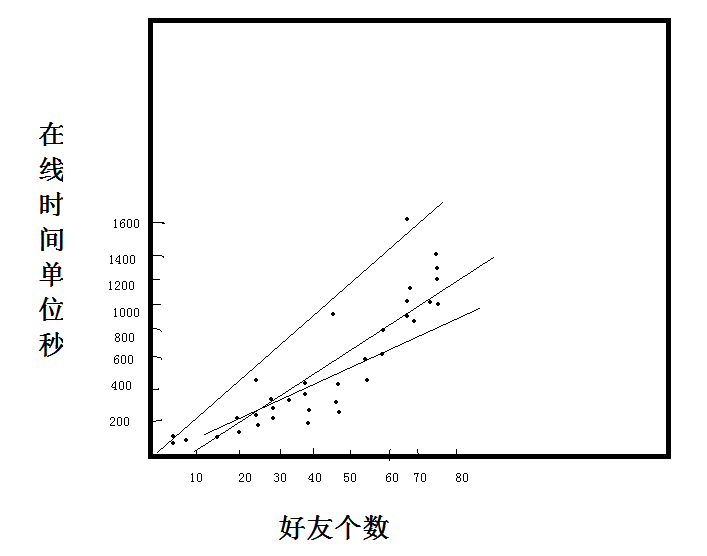
那么哪条线才是我们使用的最优线呢?这是一个拟合过程
2.spark ALS
ALS中文名作交替最小二乘法,就是在最小二乘法基础上的升级,在机器学习中,ALS特指使用最小二乘法求解的一个协同过滤算法,是协同过滤中的一种。ALS算法是2008年以来,用的比较多的协同过滤算法。从协同过滤的分类来说,ALS算法属于User-Item CF,也叫做混合CF,因为它同时考虑了User和Item两个方面,即即可基于用户进行推荐又可基于物品
如下图所示,u表示用户,v表示商品,用户给商品打分,但是并不是每一个用户都会给每一种商品打分。比如用户u6就没有给商品v3打分,需要我们推断出来,这就是机器学习的任务。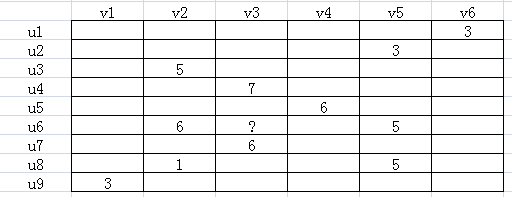
由于并不是每个用户给每种商品都打了分,可以假设ALS矩阵是低秩的,即一个m*n的矩阵,是由m*k和k*n两个矩阵相乘得到的,其中k<<m,n。
Am×n=Um×k×Vk×n
这种假设是合理的,因为用户和商品都包含了一些低维度的隐藏特征,比如我们只要知道某个人喜欢碳酸饮料,就可以推断出他喜欢百世可乐、可口可乐、芬达,而不需要明确指出他喜欢这三种饮料。这里的碳酸饮料就相当于一个隐藏特征。上面的公式中,Um×k表示用户对隐藏特征的偏好,Vk×n表示产品包含隐藏特征的程度。机器学习的任务就是求出Um×k和Vk×n。可知uiTvj是用户i对商品j的偏好,使用Frobenius范数来量化重构U和V产生的误差。由于矩阵中很多地方都是空白的,即用户没有对商品打分,对于这种情况我们就不用计算未知元了,只计算观察到的(用户,商品)集合R。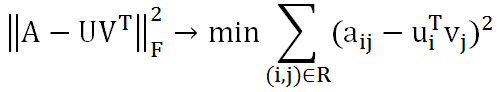
这样就将协同推荐问题转换成了一个优化问题。目标函数中U和V相互耦合,这就需要使用交替二乘算法。即先假设U的初始值U(0),这样就将问题转化成了一个最小二乘问题,可以根据U(0)可以计算出V(0),再根据V(0)计算出U(1),这样迭代下去,直到迭代了一定的次数,或者收敛为止。虽然不能保证收敛的全局最优解,但是影响不大。
spark 机器学习 ALS原理(一)的更多相关文章
- spark 机器学习 决策树 原理(一)
1.什么是决策树 决策树(decision tree)是一个树结构(可以是二叉树或者非二叉树).决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树. 其中每个非叶节点表示 ...
- spark 机器学习 knn原理(一)
1.knnK最近邻(k-Nearest Neighbor,KNN)分类算法,在给定一个已经做好分类的数据集之后,k近邻可以学习其中的分类信息,并可以自动地给未来没有分类的数据分好类.我们可以把用户分 ...
- 【转载】协同过滤 & Spark机器学习实战
因为协同过滤内容比较多,就新开一篇文章啦~~ 聚类和线性回归的实战,可以看:http://www.cnblogs.com/charlesblc/p/6159187.html 协同过滤实战,仍然参考:h ...
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
- Spark生态以及原理
spark 生态及运行原理 Spark 特点 运行速度快 => Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算.官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapR ...
- Spark 以及 spark streaming 核心原理及实践
收录待用,修改转载已取得腾讯云授权 作者 | 蒋专 蒋专,现CDG事业群社交与效果广告部微信广告中心业务逻辑组员工,负责广告系统后台开发,2012年上海同济大学软件学院本科毕业,曾在百度凤巢工作三年, ...
- Spark机器学习6·聚类模型(spark-shell)
K-均值(K-mean)聚类 目的:最小化所有类簇中的方差之和 类簇内方差和(WCSS,within cluster sum of squared errors) fuzzy K-means 层次聚类 ...
- Spark机器学习3·推荐引擎(spark-shell)
Spark机器学习 准备环境 jblashttps://gcc.gnu.org/wiki/GFortranBinaries#MacOS org.jblas:jblas:1.2.4-SNAPSHOT g ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
随机推荐
- shell脚本中执行mysql sql脚本文件并传递参数
1 shell 文件内容替换 sed是一个很好的文件处理工具,本身是一个管道命令,主要是以行为单位进行处理,可以将数据行进行替换.删除.新增.选取等特定工作,下面先了解一下sed的用法. 调用sed命 ...
- 10点睛Spring MVC4.1-全局异常处理
10.1 全局异常处理 使用@ControllerAdvice注解来实现全局异常处理; 使用@ControllerAdvice的属性缩小处理范围 10.2 演示 演示控制器 package com.w ...
- DevOps - 配置管理工具Ansible
1 - 配置管理工具 配置管理工具(SCM,Software Configuration Management)可以将代码.软件方式实现的基础设施配置信息保存,也可以根据需求变化反复进行变更. 相关工 ...
- JIRA+JIRA Agile敏捷项目管理工具
jira插件下载地址 http://www.confluence.cn/pages/viewpage.action?pageId=1671327 下载GreenHopper插件 安装Jira-agil ...
- a标签添加移除事件及开启禁用事件
一.添加移除点击事件 <script type="text/javascript" src="jquery.min.js"></script& ...
- Vue零碎总结
1.Vue指令里的bind钩子是生成了vnode,但是将它插入/更新到浏览器dom树之前的操作,因此对于一些需要插入dom树后执行的操作它是不支持的,如el.focus()方法,这些要放在insert ...
- 用pytorch1.0搭建简单的神经网络:进行多分类分析
用pytorch1.0搭建简单的神经网络:进行多分类分析 import torch import torch.nn.functional as F # 包含激励函数 import matplotlib ...
- Struts笔记2
Struts2-配置文件result元素 作用:为动作指定结果视图 name属性:逻辑视图的名称,对应着动作方法的返回值.默认值是success type属性:结果类型,指的就是用什么方式转到定义的页 ...
- 剑指offer54:字符流中第一个不重复的字符
1 题目描述 请实现一个函数用来找出字符流中第一个只出现一次的字符.例如,当从字符流中只读出前两个字符"go"时,第一个只出现一次的字符是"g".当从该字符流中 ...
- Linux 基础 目录介绍
/bin 存放二进制可执行文件(ls cat clear)等等 ,常用基础命令在这个目录下 /etc 存放系统管理和配置文件 如 passwd 用 ...