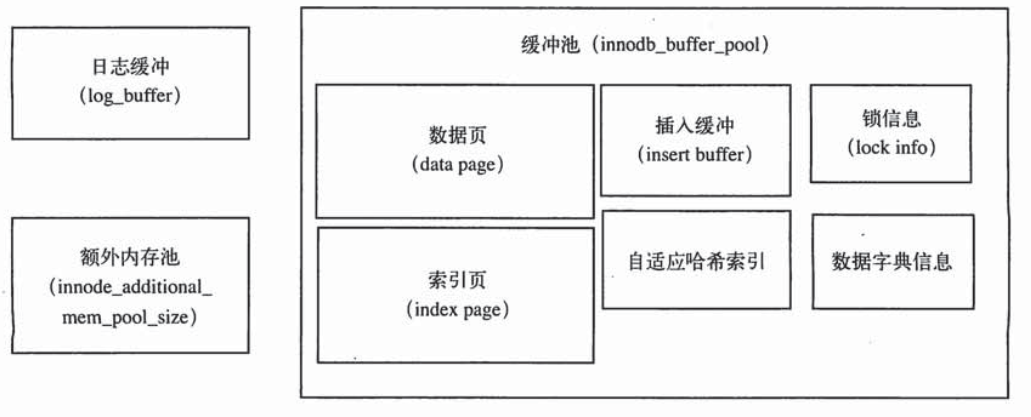
Innodb内存结构
聚集索引与非聚集索引:
聚集索引:主键,有序,存储顺序与内存一致
非聚集索引:非主键,无序
聚集索引在叶子节点存储的是表中的数据
非聚集索引在叶子节点存储的是主键和索引列
使用非聚集索引查询出数据时,拿到叶子上的主键再去查到想要查找的数据。(拿到主键再查找这个过程叫做回表)
缓冲池:
缓冲池用于存放各种数据的缓存。Innodb总是将磁盘中的数据(数据库文件)按页(16K)读取到缓冲池,然后按最近最少使用算法(LRU)来保存缓冲池中的数据。如果数据库文件需要修改,总是先修改在缓存池中的页(发生修改后,该页为脏页),然后按一定频率刷新到磁盘中。
insert buffer(插入缓冲):
使用条件:.索引是辅助索引;.索引不是唯一的。
也就是说,主键索引不使用插入缓冲。主键索引是聚集索引,插入是顺序的,执行效率比较高,就不借助缓冲了。
但是,当表中存在辅助索引(非聚集索引,非主键)时,不一定是顺序的了,这时需要离散的访问,插入性能会降低。
所以,对于非聚集索引的插入和更新操作,不是直接插入到索引页中,而是插入到缓冲中,再以一定频率执行插入缓冲和非聚集索引叶子节点的合并操作。
注:由于非主键索引叶子节点存的是主键和当前列值,所以使用非聚集索引查询时,先查辅助索引的那颗树找到对应的主键,再查主键索引的那颗树,会查两次,效率不高。
redo log(重做日志):
在事务提交的时候,Innodb会先把数据从磁盘中读到内存进行修改,然后把事务日志写到日志缓冲(log buffer),然后再刷新到重做日志文件(redo log file)中进行持久化,然后再定期刷新到磁盘中。
用于在实例故障恢复时,继续那些已经commit但数据尚未完全回写到磁盘的事务。
double write(两次写):
为防止redo log在写的过程中损坏,我们需要留个备份。若出现故障,先从备份中恢复redo log,再进行数据恢复。
undo log:
记录数据修改前的镜像,用于将未提交的事务回滚到事务开始前的状态。 undo操作:当Innodb存储引擎回滚时,它实际上做的是与之前相关的工作,对于insert操作,Innodb会完成一个delete,对于update,则会执行一个相反的update,将修改前的行放回去。
自适应哈希索引:
Innodb会监控表上索引的查找频率,若发现建立哈希索引会提升速度,则自动创建哈希索引。不是对整张表建立索引,而是根据访问频率对某些页建立。
事务提交:
事务进行过程中,每次sql语句执行,都会记录undo log和redo log,然后更新数据形成脏页。然后redo log按照时间或空间等条件进行落盘,undo log和脏页按照checkpoint进行落盘,落盘后相应的redo log就可以删除了。此时,事务还未commit,如果发生崩溃,则首先检查checkpoint记录,使用相应的redo log进行数据和undo log的恢复,然后查看undo log的状态发现事务尚未提交,然后就使用undo log进行回滚。事务执行commit操作时,会将本事务相关的所有redo log都进行落盘,只有所有redo log落盘成功,才算commit成功。然后内存中的数据脏页继续按照checkpoint进行落盘。如果此时发生了崩溃,则只使用redo log恢复数据。
Innodb内存结构的更多相关文章
- 详细了解 InnoDB 内存结构及其原理
最近发现,文章太长的话,包含的信息量较大, 并且需要更多的时间去阅读.而大家看文章,应该都是利用的一些碎片时间.所以我得出一个结论,文章太长不太利于大家的吸收和消化.所以我之后会减少文章的长度,2-3 ...
- Innodb的内存结构
1.缓冲池从1.0.x版本开始,允许有多个缓冲池实例. mysql> show variables like 'innodb_buffer_pool_size'\G ************** ...
- MySQL之 InnoDB记录结构(转自掘金小册 MySQL是怎样运行的,版权归作者所有!)
以下内容来自掘金小册 MySQL 是怎样运行的:从根儿上理解 MySQL 版权归原作者所有! 页是MySQL中磁盘和内存交互的基本单位,也是MySQL是管理存储空间的基本单位. 指定和修改行格式的语法 ...
- MySQL整体架构与内存结构
一 mysql 整体框架: MySQL是由SQL接口,解析器,优化器,缓存,存储引擎等组成的. 1. Connectors指的是不同语言中与SQL的交互. 2. Management Serveic ...
- 第五节:从一条记录说起——InnoDB记录结构
<MySQL 是怎样运行的:从根儿上理解 MySQL>第五节:从一条记录说起——InnoDB记录结构 准备工作 现在只知道客户端发送请求并等待服务器返回结果. MySQL什么方式来访 ...
- (1.3)学习笔记之mysql体系结构(C/S整体架构、内存结构、物理存储结构、逻辑结构)
目录 1.学习笔记之mysql体系结构(C/S架构) 2.mysql整体架构 3.存储引擎 4.sql语句处理--SQL层(内存层) 5.服务器内存结构 6.mysql如何使用磁盘空间 7.mysql ...
- jvm系列(二):JVM内存结构
JVM内存结构 所有的Java开发人员可能会遇到这样的困惑?我该为堆内存设置多大空间呢?OutOfMemoryError的异常到底涉及到运行时数据的哪块区域?该怎么解决呢?其实如果你经常解决服务器性能 ...
- JVM之内存结构
JVM是按照运行时数据的存储结构来划分内存结构的.JVM在运行Java程序时,将他们划分成不同格式的数据,分别存储在不同的区域,这些数据就是运行时数据.运行时数据区域包括堆,方法区,运行时常量池,程序 ...
- Delphi XE7中各种字符串与字符类型的内存结构
1. ShortString 类型 定义:type ShortString = string[255]; 内存结构与大小:ShortString 是每个字符为单字节的字符串.ShortString 的 ...
随机推荐
- sip呼叫里SDP的一些字段的含义
v=0 o=- 1 0 IN IP4 164.135.25.51 #local ip ,即本机SIP信令交互地址 s=SNS call #用于传递会话主题 c=IN IP4 164.135.25.51 ...
- 5.移动端自动化测试-小知识 import和from...import的区别
一.import 1 import导入的时,需要使用模块名的限定. 举个例子,我们首先创建一个md.py文件,里面有一个函数 2 然后在1.py文件中引用这个函数. 注意,我们需要使用md.的方式 ...
- Celery 初步使用心得
一. 基本介绍 Celery是一个专注于实时处理和任务调度的分布式任务队列.所谓任务就是消息,消息中的有效载荷中包含要执行任务需要的全部数据. 使用Celery常见场景: Web应用.当用户触发的一个 ...
- 构建之法个人作业5——alpha2项目测试
[相关信息] Q A 这个作业属于哪个课程 https://edu.cnblogs.com/campus/xnsy/2019autumnsystemanalysisanddesign/ 这个作业要求在 ...
- QQ气泡效果剖析
对于QQ汽泡效果我想不用多说了,都非常的熟悉,而且当时这效果出来简直亮瞎眼了,挺炫的,这里再来感受下: 而这次只实现单个汽泡的效果,并不涉及到加入Listview上的处理,一步步来,先上一下最终这次要 ...
- Ubuntu安装截图软件shutter
参考链接: Ubuntu 安装和配置shutter截图软件 解决shutter不能编辑的问题:https://itsfoss.com/shutter-edit-button-disabled/ 安装前 ...
- 一段有关线搜索的从python到matlab的代码
在Udacity上很多关于机器学习的课程几乎都是基于python语言的,博主“ttang”的博文“重新发现梯度下降法——backtracking line search”里对回溯线搜索的算法实现也是用 ...
- 数字签名 转载:http://www.youdzone.com/signature.html
What is a Digital Signature?An introduction to Digital Signatures, by David Youd Bob (Bob's public k ...
- Peter Shirley Ray Tracing in One Weekend(上篇)
Peter Shirley-Ray Tracing in One Weekend (2016) 原著:Peter Shirley 本书是Peter Shirley ray tracing系列三部曲的第 ...
- C# ado.net 操作(一)
简单的增删改查 class Program { private static string constr = "server=.;database=northwnd;integrated s ...