Ajax介绍及爬取哔哩哔哩番剧索引追番人数排行
Ajax,是利用JavaScript在保证页面不被刷新,页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。简单的说,Ajax使得网页无需刷新即可更新其内容。举个例子,我们用浏览器打开新浪微博,进入某个用户的页面,当我们浏览到该页末尾时,会出现一个加载的动画,然后就刷新出来的新的微博内容,这个过程并不需要我们手动的刷新网页。
Ajax的原理:发送Ajax请求到网页更新的这个过程可分为三步:
1.发送请求
2.解析内容
3.渲染网页
详细的原理介绍可参照:https://www.cnblogs.com/wanghp/p/6991554.html
简单的说,JavaScript新建了一个XMLHttpRequest对象,然后调用onreadystatechange属性设置了监听,然后调用open()方法和send()方法向服务器发送了请求,当服务器返回响应时,监听对应的方法便会触发,然后在方法里解析响应的内容,从而实现了无需刷新便能更新网页。
那么如何查看Ajax请求呢?以爬取哔哩哔哩番剧索引追番人数排行为例,我们使用Chrome浏览器打开https://www.bilibili.com/anime/index/#season_version=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&pub_date=-1&style_id=-1&order=3&st=1&sort=0&page=1,并按F12打开开发者工具,如图所示: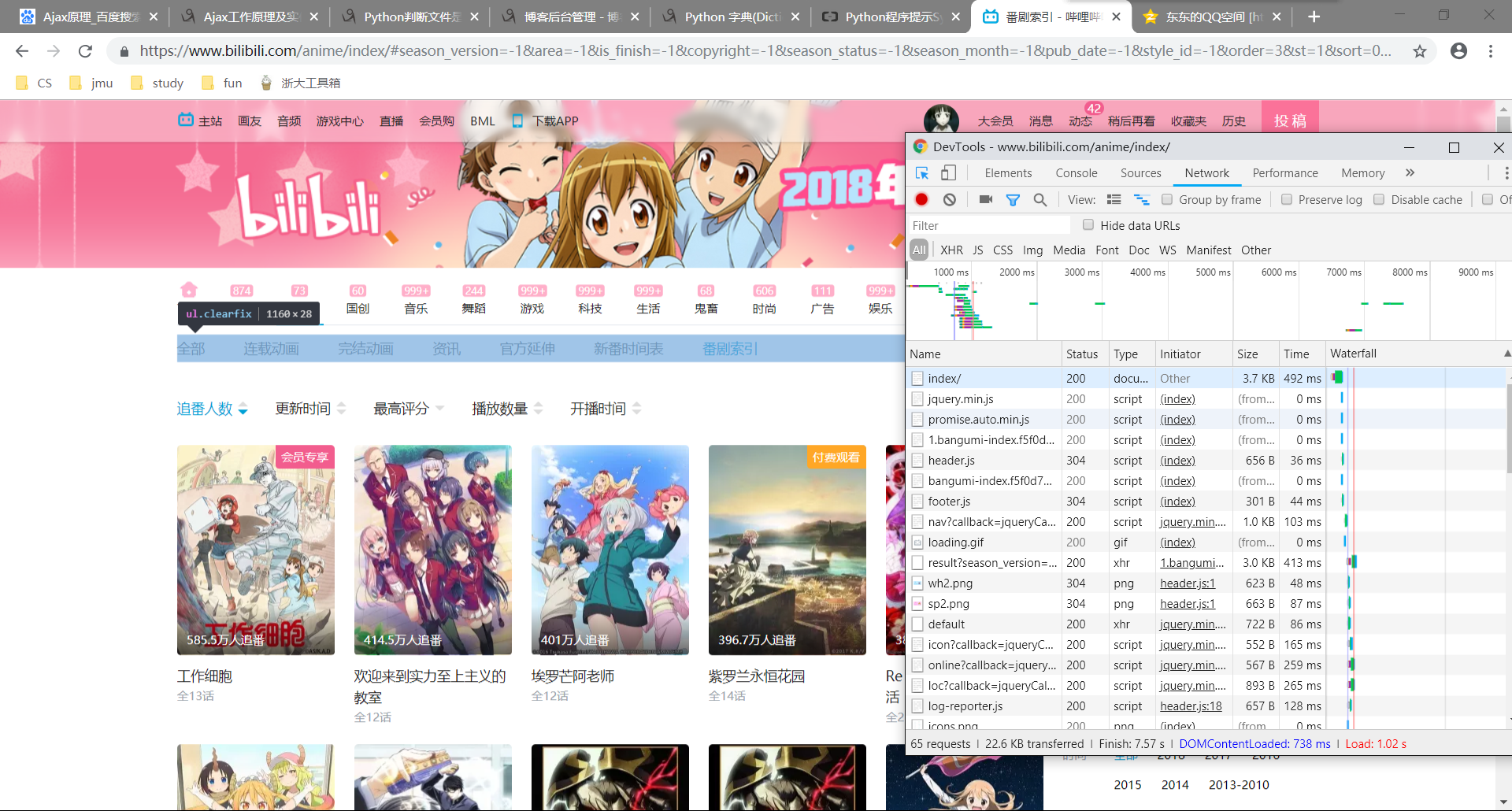
在开发者工具中切换到Network选项卡,然后重新刷新页面,筛选XHR请求类型,如图所示:
在左边找到我们需要爬取的Ajax请求,即

点击header可以查看该请求的header信息,之后我们会用到。
Preview是该请求返回的响应内容,包含了我们所要爬取的信息。
接下来我们以爬取b站追番人数排行榜为例来介绍如何提取Ajax结果:
首先在header中找到请求链接,即Request URL:
接着找到该请求的参数信息:

观察到每次翻页,page参数+1,其他参数没有改变,所以我们每次请求时只需要改变page参数即可。
下面给出代码示例:
from urllib.parse import urlencode
import requests
import time
import csv
import os base_url = "https://bangumi.bilibili.com/media/web_api/search/result?" headers = {
'Host':'bangumi.bilibili.com',
'Referer':'https://www.bilibili.com/anime/index/',
'User_Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Origin': 'https://www.bilibili.com',
} def get_page(page):
#参数
params = {
'season_version':'-1',
'area': '-1',
'is_finish': '-1',
'copyright': '-1',
'season_status': '-1',
'season_month':'-1',
'pub_date': '-1',
'style_id': '-1',
'order': '',
'st': '',
'sort': '',
'page': page,
'season_type':'',
'pagesize':''
}
url = base_url + urlencode(params)
try:
response = requests.get(url,headers=headers,allow_redirects=False)
#将内容解析为json格式返回
return response.json()
except requests.ConnectionError as e:
print('Error',e.args) def parse_page(json):
if json:
items = json.get('result').get('data')
for item in items:
ret = {}
ret['title'] = item.get('order').get('title')
ret['score'] = item.get('order').get('score')
ret['play'] = item.get('order').get('play')
ret['follow'] = item.get('order').get('follow')
ret['index_show'] = item.get('index_show')
ret['is_finish'] = item.get('is_finish')
yield item #写入文件
def write_to_file(items):
with open("bilibili.csv","a+") as csvfile:
writer = csv.writer(csvfile)
for item in items:
print(item)
writer.writerow([item['order']['follow'],item['title'],item['order']['score'],
item['order']['play'],item['index_show'],item['is_finish']]) def main(offset):
json = get_page(offset)
results = parse_page(json)
write_to_file(results)
return 0 if __name__ == '__main__':
for page in range(1,11):
main(offset=page)
time.sleep(1)
运行结果:

Ajax介绍及爬取哔哩哔哩番剧索引追番人数排行的更多相关文章
- Ajax数据的爬取(淘女郎为例)
mmtao Ajax数据的爬取(淘女郎为例) 如有疑问,转到 Wiki 淘女郎模特抓取教程 网址:https://0x9.me/xrh6z 判断一个页面是不是 Ajax 加载的方法: 查看网页源代码, ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- 爬虫七之分析Ajax请求并爬取今日头条
爬取今日头条图片 这里只讨论出现的一些问题,代码在最下面github链接里. 首先,今日头条取消了"图集"这一选项,因此对于爬虫来说效率降低了很多: 在所有代码都完成后,也许是爬取 ...
- 第十四节:Web爬虫之Ajax数据爬取
有时候在爬取数据的时候我们需要手动向上滑一下,网页才加载一定量的数据,但是网页的url并没有发生变化,这时我们就要考虑使用ajax进行数据爬取了...
- 他爬取了B站所有番剧信息,发现了这些……
本文来自「楼+ 之数据分析与挖掘实战 」第 4 期学员 -- Yueyec 的作业.他爬取了B站上所有的番剧信息,发现了很多有趣的数据- 关键信息:最高播放量 / 最强up主 / 用户追番数据 / 云 ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- 爬虫实战——Scrapy爬取伯乐在线所有文章
Scrapy简单介绍及爬取伯乐在线所有文章 一.简说安装相关环境及依赖包 1.安装Python(2或3都行,我这里用的是3) 2.虚拟环境搭建: 依赖包:virtualenv,virtualenvwr ...
- scrapy关键字爬取百度图库(一)
刚入门学习python的菜鸟,如有错误,还望指教 爬取百度图库需要知道百度图库的加载方式是通过下拉加载的,所以我们需要分析Ajax请求来爬取每一页的数据信息 表述不清直接上图片 图片一是刷新页面后加载 ...
- python scrapy爬取知乎问题和收藏夹下所有答案的内容和图片
上文介绍了爬取知乎问题信息的整个过程,这里介绍下爬取问题下所有答案的内容和图片,大致过程相同,部分核心代码不同. 爬取一个问题的所有内容流程大致如下: 一个问题url 请求url,获取问题下的答案个数 ...
随机推荐
- Partition--分区切换
现有数据表[dbo].[staging_TB1_20131018-104722]和分区表[dbo].[TB1],需要将分区表和数据表中做数据交换 CREATE TABLE [dbo].[staging ...
- HBase介绍(4)---常用shell命令
进入hbase shell console$HBASE_HOME/bin/hbase shell如果有kerberos认证,需要事先使用相应的keytab进行一下认证(使用kinit命令),认证成功之 ...
- sql字段操作
--删除第一位 substring(ftpMobile,2,len(ftpMobile)-1) --检查是否是数字 ISNUMERIC(ftpMobile) =0 含数字以外字符 ISNUMERIC ...
- SQL Server分页查询存储过程
--分页存储过程create PROCEDURE [dbo].[commonPagination]@columns varchar(500), --要显示的列名,用逗号隔开 @tableName va ...
- 解决Win8.1系统Wpprecorder.sys蓝屏故障
为了跨平台调试,在Mac Air使用Bootscamp安装了Windows 8.1,但是经常出现system_thread_exceptions_not_handled(Wpprecorder.sys ...
- 百度直接搜IP可以查看本机外网IP
百度直接搜IP可以查看本机外网IP ipconfig在控制台查看的是内网IP
- php数据库编程---mysql扩展库
1, Java有一种方式操作数据库, PHP有三种方式来操作mysql数据库.(1)mysql扩展库:(2)mysqli扩展库:(3)pdo: 2, mysql扩展库和mysql数据库区别 3, my ...
- vue数据响应的坑
1.首先遇到的第一个坑是数组 vue初始化时,data是一个数组并且为空的时候,里面有一些对象元素,直接改变这些对象的的属性不会触发视图更新 解决办法,copy一个新的数组(vue.assign是浅c ...
- git 换行符替换
https://help.github.com/en/articles/dealing-with-line-endings rm .git/index git reset https://github ...
- sklearn的train_test_split
train_test_split函数用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签. 格式: X_train,X_test, y_train, y_test ...