3.配置HDFS HA
namenode负责管理整个hdfs集群,如果namenode故障则集群将不可用.因此有必须实现namenode高可用.
hdfs的高可用原理参考:
HADOOP(二):hdfs 高可用原理
zookeeper简介:
zookeeper集群安装
安装zookeeper
下载zookeeper
下载zookeeper并解压到/opt
[zookeeper@hadoop1 opt]$ wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz
[zookeeper@hadoop1 opt]$ gunzip zookeeper-3.4.9.tar.gz
[zookeeper@hadoop1 opt]$ tar -xvf zookeeper-3.4.9.tar.gz编辑zookeeper配置文件
[zookeeper@hadoop1 zookeeper-3.4.9]$ cd conf/
[zookeeper@hadoop1 conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[zookeeper@hadoop1 conf]$ cp zoo_sample.cfg zoo.cfg
[zookeeper@hadoop1 conf]$ vi zoo.cfg
tickTime=2000
dataDir=/opt/zookeeper-3.4.9/dataDir
dataLogDir=/opt/zookeeper-3.4.9/dataLogDir
clientPort=2181
initLimit=5
syncLimit=2
server.1=hadoop3:2888:3888
server.2=hadoop4:2888:3888
server.3=hadoop5:2888:3888创建myid文件
在每个节点上写上节点的id,如节点1就写1.放在dataDir指定的目录下.
启动zookeeper
bin/zkServer.sh start如果报错检查zookeeper.out
使用客户端连接到zookeeper:
[zookeeper@hadoop5 zookeeper-3.4.9]$ bin/zkCli.sh -server 127.0.0.1:2181连进去表示zookeeper正常
配置HDFS HA
配置手动HA
HDFS HA中用,nameserivce ID来标识一个HDFS服务,为了标识每个NN,还要加上namenode id。
在hdfs-site.xml中:
1.设置集群的标识dfs.nameservice
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>这里修改为dockercluster
2.设置namenode名称 dfs.ha.namenodes.[nameservice ID]
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>nn1 nn2为namenode的标识。
注意:当前只支持两个namenode的HA
3.设置namenode对外提供服务的RPC地址 dfs.namenode.rpc-address.[nameservice ID].[name node ID]
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop2:8020</value>
</property>这个RPC地址实际就是 dfs.defaultFS地址
4.设置HDFS web页面地址 dfs.namenode.http-address.[nameservice ID].[name node ID]
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop2:50070</value>
</property>如果启用的hdfs的安全机制,要设置 https-address
5.设置journal上edit log共享目录 dfs.namenode.shared.edits.dir
格式是:qjournal://host1:port1;host2:port2;host3:port3/journalId 所有节点上路径要保持一致
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop3:8485;hadoop4:8485;hadoop5:8485/mycluster</value>
</property>这里我们改成: qjournal://hadoop4:8485;hadoop5:8485;hadoop6:8485/dockercluster
6.设置实现集群HA的类 dfs.client.failover.proxy.provider.[nameservice ID]
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>当前仅支持这个类
7.设置切换时执行的程序 dfs.ha.fencing.methods
当namenode发生切换时,原来active的NN可能依然在写edit log,这时如果standby 也开始写edit log,元数据会"脑裂"。为了防止"脑裂",必须要切换之前杀掉原来active 的NN,这个脚本就是实现这个目的。当前支持两中fencing.method:shell 和 sshfence。另外,可能自定义org.apache.hadoop.ha.NodeFence来实现自己的保护程序。
7.1.sshfence(默认)
通过SSH登录到原来active的NN,并使用fuser命令KILL掉NN进程。要使用SSH,必须配置rsa-key参数:dfs.ha.fencing.ssh.private-key-files
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hdfs/.ssh/id_rsa</value>
</property>也可以用其它用户登录,同样可以配置超时参数:
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence([[username][:port]])</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>7.2.shell
自定义一个shell脚本业杀死NAMENODE
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/path/to/my/script.sh arg1 arg2 …)</value>
</property>shell脚本可以读取到当前已经配置的HDFS变量,将"."替换为"_" 即可。对于某些共用的条目,如dfs_namenode_rpc-address可以自动的指向特定节点如dfs.namenode.rpc-address.ns1.nn1。以下变量也可以使用:
| $target_host |
| $target_port |
| $target_address |
| $target_namenodeid |
示例:
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/path/to/my/script.sh --nameservice=$target_nameserviceid $target_host:$target_port)</value>
</property>如果shell返回0,表示执行成功。如果不为0,则继续执行其它的fencing.method.shell方式没有timeout.
这时里,我们也用ssh方式,比较简单,只需要生成key就行了.在NN1 NN2上执行:
[hdfs@hadoop1 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hdfs/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hdfs/.ssh/id_rsa.
Your public key has been saved in /home/hdfs/.ssh/id_rsa.pub.
The key fingerprint is:
6b:de:13:b7:55:ba:43:1c:28:ef:2e:b8:b7:0a:e0:15 hdfs@hadoop1
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| E . |
8.journal节点守护进程自己的数据目录 dfs.journalnode.edits.dir
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-2.8.0/journalEditDir</value>
</property>9.在core-site.xml中设置hdfs 服务 fs.defaultFS
一旦使用了HDFS HA,那么fs.defaultFS就不能写成host:port文件,而要写成服务方式,写上nameservice id:
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>这里改成hdfs://dockercluster
经过以上的配置,可以通过命令手动切换nemenode
配置自动HA
1.修改hdfs-site.xml
添加:
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>2.修改core-site.xml
添加zookeer的server列表:
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop3:2181,hadoop4:2181,hadoop5:2181</value>
</property>启动HDFS HA
1.在zookeeper中初始化HA状态
在其中一台namenode上执行:
[hdfs]$ $HADOOP_PREFIX/bin/hdfs zkfc -formatZK2.启动HDFS集群
1.启动所有journal节点`$HADOOP_HOME/sbin/hadoop-daemon.sh start journalnode`
2.执行journal 节点初始化`hdfs namenode -initializeSharedEdits`
3.启动原来的namenode `$HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode`
4.初始化standby,在standby上执行 `hdfs namenode -bootstrapStandby`,
5.启动standby `$HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode`
6.启动namenode自动HA进程zkfc,在每台namenode上执行:$HADOOP_PREFIX/sbin/hadoop-daemon.sh --script $HADOOP_PREFIX/bin/hdfs start zkfc3.检查HA情况
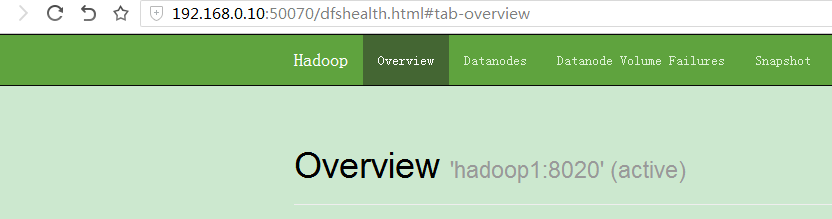
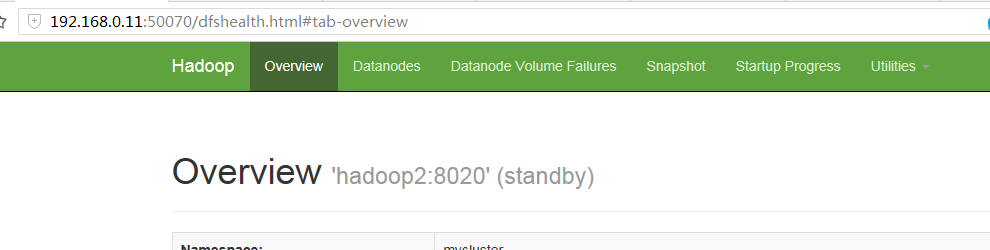
可以看到两台机器一个是active一个是standby
4.验证自动HA
现在在hadoop1 kill active的namenode

发现hadoop2成了active,说明自动HA配置成功.
3.配置HDFS HA的更多相关文章
- Hadoop 2、配置HDFS HA (高可用)
前提条件 先搭建 http://www.cnblogs.com/raphael5200/p/5152004.html 的环境,然后在其基础上进行修改 一.安装Zookeeper 由于环境有限,所以在仅 ...
- 部署hadoop2.7.2 集群 基于zookeeper配置HDFS HA+Federation
转自:http://www.2cto.com/os/201605/510489.html hadoop1的核心组成是两部分,即HDFS和MapReduce.在hadoop2中变为HDFS和Yarn.新 ...
- [转]HDFS HA 部署安装
1. HDFS 2.0 基本概念 相比于 Hadoop 1.0,Hadoop 2.0 中的 HDFS 增加了两个重大特性,HA 和 Federaion.HA 即为 High Availability, ...
- 【Hadoop 分布式部署 十:配置HDFS 的HA、启动HA中的各个守护进程】
官方参考 配置 地址 :http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabili ...
- 第6章 HDFS HA配置
目录 6.1 hdfs-site.xml文件配置 6.2 core-site.xml文件配置 6.3 启动与测试 6.4 结合ZooKeeper进行自动故障转移 在Hadoop 2.0.0之前,一个H ...
- HAWQ配置之HDFS HA
一.在ambari管理界面启用HDFS HA 在ambari中这步很简单,在所有安装的服务都正常之后,在HDFS的服务界面中,点击下拉菜单“Actions”,选择启用HDFS HA项 “Enable ...
- hadoop(二):hdfs HA原理及安装
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用.为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux ...
- hadoop2.610集群配置(包含HA和Hbase )
.修改Linux主机名2.修改IP3.修改主机名和IP的映射关系######注意######如果你们公司是租用的服务器或是使用的云主机(如华为用主机.阿里云主机等)/etc/hosts里面要配置的是内 ...
- Hadoop 学习笔记 (十) hadoop2.2.0 生产环境部署 HDFS HA Federation 含Yarn部署
其他的配置跟HDFS-HA部署方式完全一样.但JournalNOde的配置不一样>hadoop-cluster1中的nn1和nn2和hadoop-cluster2中的nn3和nn4可以公用同样的 ...
随机推荐
- Core Data实例
#import <UIKit/UIKit.h> #import <CoreData/CoreData.h> @interface CHViewController : UIVi ...
- 【usaco】1.1
你的飞碟在这儿Your Ride Is Here(难度:入门难度) 题目链接 题目大意 emmmm 输入两个字符串,问他们每个字母的asco码相乘后字符串是否相等. 思路 一道水题?(雾) 错误代码: ...
- MySQL学习之事务安全
事务安全 事务概念 事务(transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit),事务通常由高级数据操纵语言或编程语言 书写的用户程序的执行所引起.事务有事务开始(b ...
- 解决 ajax 跨域
用两个服务器处理一个项目的代码,其中一台服务器只处理接口请求. 本来PHP可以使用CURL来处理,但是领导不允许使用PHP来处理数据.会影响网站的功能.如果接口端出现问题会导致整个网站或其页面的崩溃, ...
- json提取嵌套数据
//数据 string html = "{\"code\":\"0000\",\"desc\":\"\",\& ...
- 关于“CheckBox”通过表单提交的问题
大多数时候CheckBox取值传到java后台都是通过js取值,ajax传值,今天改一离职同事的老代码,那家伙通过表单提交一些列的CheckBox设置,没想到的是后台死活接收不正常,name.valu ...
- 【Hive六】Hive调优小结
Hive调优 Hive调优 Fetch抓取 本地模式 表的优化 小表.大表Join 大表Join大表 MapJoin Group By Count(Distinct) 去重统计 行列过滤 动态分区调整 ...
- 实验吧web加了料的报错注入
知识点: SQL注入中用到的Concat函数详解 http://www.sohu.com/a/219966085_689961 http分割注入 直接根据提示,提交post请求的用户名和密码 结 ...
- docker 环境下创建 overlay 网络方案
一.环境 三台机器,其中一台安装 consul(192.168.1.21), 两台创建网络(192.168.1.32,33) 二.实现步骤 1.构建环境 1)三台机器部署docker环境 2)选择一台 ...
- Leecode刷题之旅-C语言/python-349两个数组的交集
/* * @lc app=leetcode.cn id=349 lang=c * * [349] 两个数组的交集 * * https://leetcode-cn.com/problems/inters ...