ElasticSearch 论坛搜索查询语句
概述
研究论坛搜索如何综合时间和TF/IDF权重。
自定义权重计算的效率问题
数据结构
假设有一个论坛的搜索
字段包括:
subject:标题
message:内容
dateline:发布时间
tagid:论坛id
直接通过注释一个查询语句来直观了解如何使用json来查询数据。
{
//为每个全文索引字段定义highlight(高亮)格式
"highlight": {
"fields": {
"subject": {},
"message": {}
}
},
//不返回全部数据
"_source": false,
//只返回subject字段
"fields": [
"subject"
],
//一个查询语句
"query": {
//自定义score(分数)
"function_score": {
"query": {
//带过滤器的查询需要用filtered 包裹
"filtered": {
//过滤器部分
"filter": {
"term": {
"tagid": 1
}
},
//查询语句部分(全文索引)
"query": {
//要查的部分有2个,用or连接起来(should 类似or)
"bool": {
"should": [
{
//match来按照全文索引来查
"match": {
//查标题
"subject": {
//标题关键字
"query": "手榴弹",
//权重boost会做个乘法
"boost": 5
}
}
},
//内容字段权重较低,配置基本相同
{
"match": {
"message": {
"query": "手榴弹",
"boost": 1
}
}
}
]
}
}
}
},
//额外的发布时间权重,时间越大,权重越大,也是乘法(默认)
//但是由于log在输入值巨大的情况下(时间戳)y轴增长缓慢,几乎无法影响到score,所以下面这个配置,思想是好的,结果是废的
"field_value_factor": {
"field": "dateline",
//log(1 + dateline)
"modifier": "log1p",
"factor": 0.1,
"missing": 1//没有这个字段的处理方式,返回分数1
}
}
}
}
note: 你可能注意到我用了手榴弹一词,因为我们论坛中几乎不会出现这个词,所以在测试中可以方便测试词频、标题(subject),内容(message)的权重问题,而减少其他用户数据干扰
使用groovy语言来控制排序用的score字段
如果你使用比较新版本的ES,比如>=2.0,你可能需要先配置一下服务器以便支持groovy语句
_score是ES通过TF/IDF和其他自定义算法计算得到的一个分数,用来表达和搜索预期的接近程度,值越大越接近理想的结果。通过控制这个值,就可以改变搜索的排序结果。上面的boost是其中一种,通过设置boost,得到 _score = _score * boost的效果,相当于我们喜欢使用的“权重”。
而上面的field_value_factor的控制方式为:
_score = oldscore * log(1 + dateline * 0.1)
其实这个语句的目的就是为了让时间大的(靠近现在)的数据排序靠前一点,比如新闻什么的,时间越近也是越好的,然而这个分数在dateline有巨大差异的情况下,只有万分之几的变化,不能满足要求,一个简单的方法就是 1 /(当前时间 - 发布时间),由于这个分数的底数是从0开始算起的,而 f(x) = 1/x 靠近1的部分,数值差异比较大,远离的部分(旧数据,趋于0)。这个公式还有个问题,就是底数可能是0,如果你有N台服务器,而服务器之间有一定的时间差,就可能遇到这个问题。
改为下面这样:
1 / (当前时间 - 发布时间 > 0 ? 当前时间 - 发布时间 : 1)
但是如果旧数据时间趋于0也会导致一个新问题就是,基于TF/IDF的分数失效了,也不是我们想要的,所以简单办法就是给这个分数 + 1
还有一个问题就是当时间差异为2秒的时候,数值已经下降了50%,这也太快了一点,通过一个因数控制一下下降速度
1 / (当前时间 - 发布时间 >= 1000 ? (当前时间 - 发布时间)/ 1000 : 1) + 1
1000秒的效果
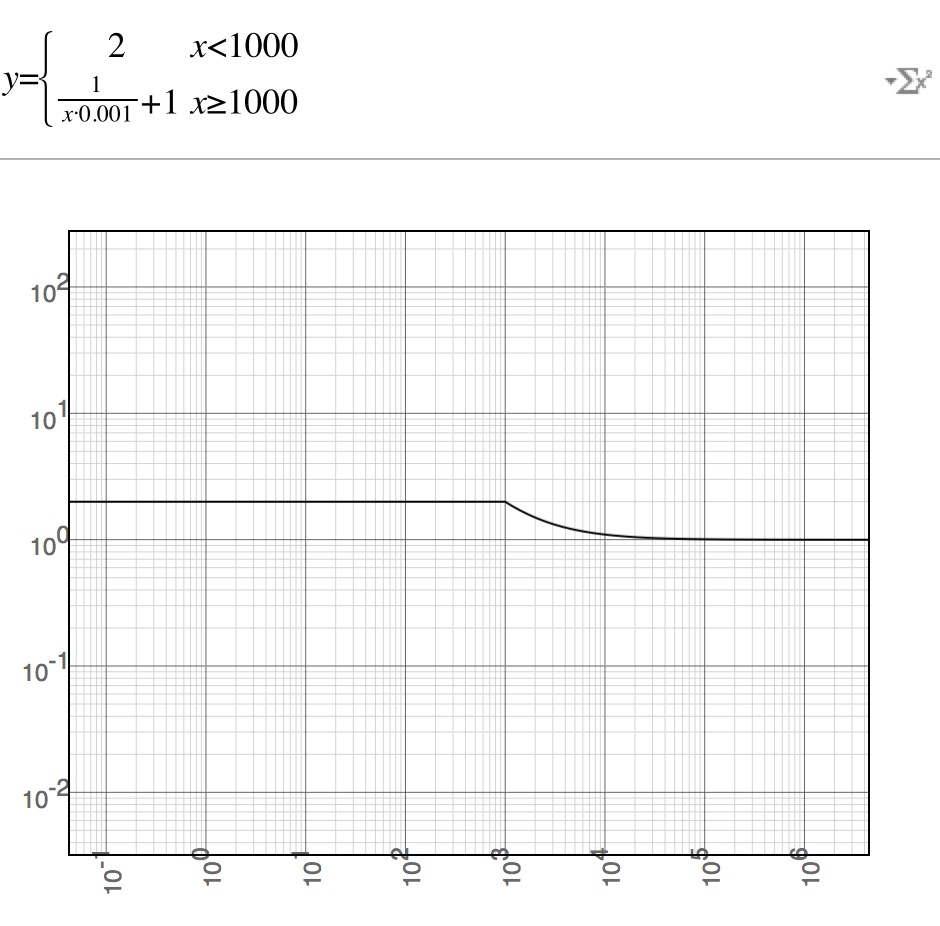
8小时的效果,基本上在10天后,分值趋近于1,也就是完全由TF/IDF决定
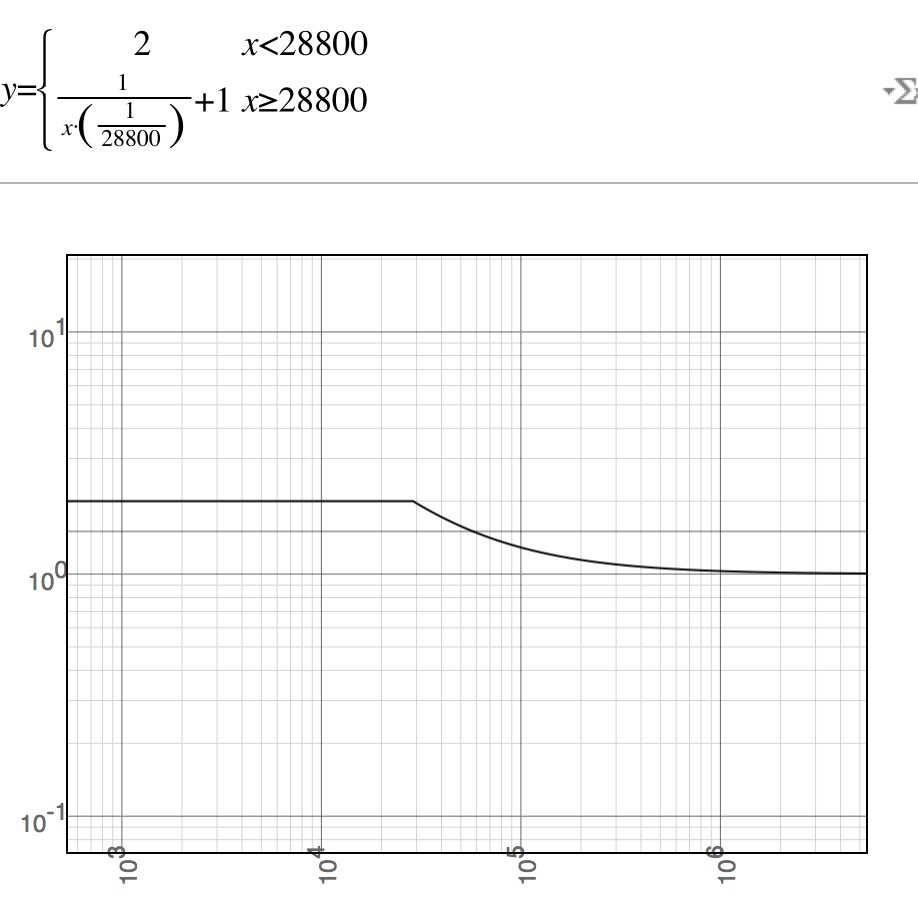
这样确保了结果在(1,2]之间变化,而分值衰减50%需要2000秒以后才会达到,最近1000秒内的数据分值相同,他们是平等的(除非新闻专题,半小时内发布的东西对于用户来说,先后的重要程度并不高,如果是论坛更是如此,在论坛中我可能会增加到4-8小时)。
{
"highlight": {
"fields": {
"subject": {},
"message": {}
}
},
"query": {
"function_score": {
"query": {
"filtered": {
"filter": {
"term": {
"tagid": 1
}
},
"query": {
"bool": {
"should": [
{
"match": {
"subject": {
"query": "手榴弹",
"boost": 1,
"operator": "or"
}
}
},
{
"match": {
"message": {
"query": "手榴弹",
"boost": 1,
"operator": "or"
}
}
}
]
}
}
}
},
//这里是差异的部分
"functions": [
{
"script_score": {
"script": "return 1 /( now - doc['dateline'].value > 1000 ? ( now - doc['dateline'].value ) / 1000 : 1);",
"params": {
"now": 1448806722
}
}
}
]
}
}
}
2015年12月03更新:groovy 效率极低
在实际应用的时候,我们数据量大概是 1400 万条,约12G。
测试机器硬件配置:
Intel(R) Xeon(R) CPU E5506 @ 2.13GHz 4核
内存16G
集群设置:
- 单节点
- 分片5,备份 0 分词插件为 ik
这个查询跑下来需要3000 ms 以上,关键的问题就是groovy,这个数据不是预先计算好的,而是每次重新计算。
其实除了groovy,ES还支持多种脚本语言。
目前测试下来比较快的是expression ,内置,不需要插件,速度快,只支持数值运算,符合我们的需要。
//function 部分改为如下,注意:不需要return,这是个算数表达式。不需要分号结尾。
"functions": [
{
"script_score": {
"lang": "expression",
"script": "1 /( now - doc['dateline'].value > 259200 ? ( now - doc['dateline'].value ) / 259200 : 1)",
"params": {
"now": $time
}
}
}
]
对比情况为:
groovy 3000ms 以上
expression 35 - 50 ms 间浮动
- 速度相差约 60 倍 *
官方说法是expression的速度是可以匹敌原生java语言的插件。但是表达式的各个部分,只能是数字。
参考资料:
有关script_score的官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-scripting.html#_lucene_expressions_scripts
lucene expression 官方文档
http://lucene.apache.org/core/4_9_0/expressions/index.html?org/apache/lucene/expressions/js/package-summary.html
Es权威指南第二部分,Search in Depth - script-score
https://www.elastic.co/guide/en/elasticsearch/guide/current/script-score.html
ElasticSearch 论坛搜索查询语句的更多相关文章
- elasticsearch查询语句
1,安装es 安装java环境 # java --versionjava version "1.8.0_65" Java(TM) SE Runtime Environment (b ...
- SpringBoot使用注解的方式构建Elasticsearch查询语句,实现多条件的复杂查询
背景&痛点 通过ES进行查询,如果需要新增查询条件,则每次都需要进行硬编码,然后实现对应的查询功能.这样不仅开发工作量大,而且如果有多个不同的索引对象需要进行同样的查询,则需要开发多次,代码复 ...
- ElasticSearch 7.X版本19个常用的查询语句
整理一篇常用的CRUD查询语句,之前这篇文件是在17年左右发表的,从英文翻译过来,现在采用7.x 版本进行实验,弃用的功能或者参数,我这边会进行更新,一起来学习吧. 为了演示不同类型的 Elastic ...
- Func<T,T>应用之Elasticsearch查询语句构造器的开发
前言 之前项目中做Elasticsearch相关开发的时候,虽然借助了第三方的组件PlainElastic.Net,但是由于当时不熟悉用法,而选择了自己拼接查询语句.例如: string queryG ...
- elasticsearch结构化查询过滤语句-----4
1.之前三节讲述的都是索引结构及内容填充的部分,既然添加了数据那我们的目的无非就是增产改查crudp,我先来讲讲查询-----结构化查询 我们看上图截图两种方式: 1)第一种,在索引index5类型s ...
- Elasticsearch之四种查询类型和搜索原理(博主推荐)
Elasticsearch Client发送搜索请求,某个索引库,一般默认是5个分片(shard). 它返回的时候,由各个分片汇总结果回来. 官网API https://www.elastic.co/ ...
- ElasticSearch High Level REST API【2】搜索查询
如下为一段带有分页的简单搜索查询示例 在search搜索中大部分的搜索条件添加都可通过设置SearchSourceBuilder来实现,然后将SearchSourceBuilder RestHighL ...
- Elasticsearch 教程--搜索
搜索 – 基本工具 到目前为止,我们已经学习了Elasticsearch的分布式NOSQL文档存储,我们可以直接把JSON文档扔到Elasticsearch中,然后直接通过ID来进行调取.但是Elas ...
- Elasticsearch 数据搜索篇·【入门级干货】
ES即简单又复杂,你可以快速的实现全文检索,又需要了解复杂的REST API.本篇就通过一些简单的搜索命令,帮助你理解ES的相关应用.虽然不能让你理解ES的原理设计,但是可以帮助你理解ES,探寻更多的 ...
随机推荐
- shell定时统计Nginx下access.log的PV并发送给API保存到数据库
1,统计PV和IP 统计当天的PV(Page View) cat access.log | sed -n /`date "+%d\/%b\/%Y"`/p |wc -l 统计某一天的 ...
- JSP/Servlet开发——第七章 Servel基础
1.Servlet简介: ●Servlet是一个符合特定规范的 JAVA 程序 , 是一个基于JAVA技术的Web组件. ●Servlet允许在服务器端,由Servlet容器所管理,用于处理客户端请求 ...
- Vue-cli 3.0 使用Sass Scss Less预处理器
项目中使用预处理器,可以有效减少css代码量,使用Sass||Scss||Less; 预处理器 你可以在创建项目的时候选择预处理器 (Sass/Less/Stylus).如果当时没有选好, 内置的 w ...
- Java : Spring基础 IOC
使用 ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml" ...
- MFC非模态添加进程控件方法一(线程方法)
由于非模态对话框的自己没有消息循环,创建后无法进行消息处理.需要和父窗口共用消息循环.如果单独在子窗口进行控件由于自己没有单独的消息循环,更新是无法进行的. 如果在父窗口更新控件会造成程序假死.如以下 ...
- python3 package management 包管理 实例
包是一种组织管理代码的方式,包里面存放的是模块 用于将模块包含在一起的文件夹就是包 包内包含__init__.py标志性文件 定义一个学生类,一个sayhello函数,一个打印语句 # p01.py ...
- c语言中 *p++ 和 (*p)++ 有什么区别?以及C语言运算符的优先级。整理。
*p++是指下一个地址. (*p)++是指将*p所指的数据的值加一. C编译器认为*和++是同优先级操作符,且都是从右至左结合的,所以*p++中的++只作用在p上,和*(p++)意思一样:在(*p)+ ...
- vimrc 配置
" All system-wide defaults are set in $VIMRUNTIME/debian.vim and sourced by" the call to : ...
- .Net 面试题 汇总(六)
一.填空题 1.面向对象的语言具有(继承)性.(多态)性.(封装)性. 2.能用foreach遍历访问的对象需要实现 (IEnumberable)接口或声明(GetEnumberator)方法的类型. ...
- 【转】odoo装饰器:model
model装饰器的作用是返回一个集合列表,一般用来定义自动化动作里面,该方法无ids传入. 应用举例: 定义columns langs = fields.Selection(string=" ...