Hadoop High Availability高可用
HDFS HA
Namenode HA 详解
hadoop2.x 之后,Clouera 提出了 QJM/Qurom Journal Manager,这是一个基于 Paxos 算法(分布式一致性算法)实现的 HDFS HA 方案,它给出了一种较好的解决思路和方案,QJM 主要优势如下:
不需要配置额外的高共享存储,降低了复杂度和维护成本。
消除 spof(单点故障)。
系统鲁棒性(Robust)的程度可配置、可扩展。

基本原理就是用 2N+1 台 JournalNode 存储 EditLog,每次写数据操作有>=N+1 返回成功时即认为该次写成功,数据不会丢失了。当然这个算法所能容忍的是最多有 N台机器挂掉,如果多于 N 台挂掉,这个算法就失效了。这个原理是基于 Paxos 算法。
在 HA 架构里面 SecondaryNameNode 已经不存在了,为了保持 standby NN 时时的与 Active NN 的元数据保持一致,他们之间交互通过 JournalNode 进行操作同步。
任何修改操作在 Active NN 上执行时,JournalNode 进程同时也会记录修改 log到至少半数以上的 JN 中,这时 Standby NN 监测到 JN 里面的同步 log 发生变化了会读取 JN 里面的修改 log,然后同步到自己的目录镜像树里面,如下图:
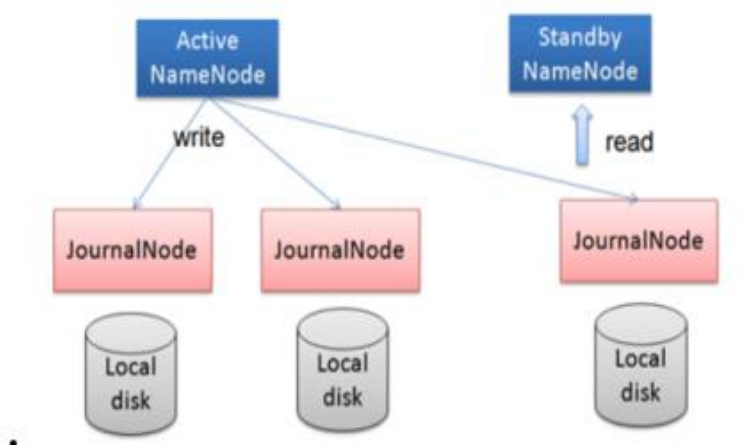
当发生故障时,Active 的 NN 挂掉后,Standby NN 会在它成为 Active NN 前,读取所有的 JN 里面的修改日志,这样就能高可靠的保证与挂掉的 NN 的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
在 HA 模式下,datanode 需要确保同一时间有且只有一个 NN 能命令 DN。为此:每个 NN 改变状态的时候,向 DN 发送自己的状态和一个序列号。
DN 在运行过程中维护此序列号,当 failover 时,新的 NN 在返回 DN 心跳时会返回自己的 active 状态和一个更大的序列号。DN 接收到这个返回则认为该 NN 为新的 active。
如果这时原来的 active NN 恢复,返回给 DN 的心跳信息包含 active 状态和原来的序列号,这时 DN 就会拒绝这个 NN 的命令。
Failover Controller
HA 模式下,会将 FailoverController 部署在每个 NameNode 的节点上,作为一个单独的进程用来监视 NN 的健康状态。 r FailoverController 主要包括三个组件:
HealthMonitor: 监控 NameNode 是否处于 unavailable 或 unhealthy 状态。当前通过RPC 调用 NN 相应的方法完成。
ActiveStandbyElector: 监控 NN 在 ZK 中的状态。
ZKFailoverController: 订阅 HealthMonitor 和 ActiveStandbyElector 的事件,并管理 NN 的状态,另外 zkfc 还负责解决 fencing(也就是脑裂问题)。
上述三个组件都在跑在一个 JVM 中,这个 JVM 与 NN 的 JVM 在同一个机器上。但是两个独立的进程。一个典型的 HA 集群,有两个 NN 组成,每个 NN 都有自己的 ZKFC 进程。
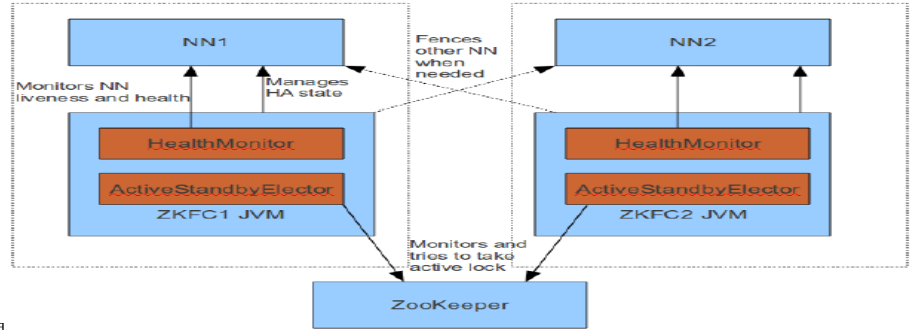
ZKFailoverController 主要职责:
- 健康监测:周期性的向它监控的 NN 发送健康探测命令,从而来确定某个 NameNode是否处于健康状态,如果机器宕机,心跳失败,那么 zkfc 就会标记它处于一个不健康的状态
- 会话管理:如果 NN 是健康的,zkfc 就会在 zookeeper 中保持一个打开的会话,如果 NameNode 同时还是 Active 状态的,那么 zkfc 还会在 Zookeeper 中占有一个类型为短暂类型的znode,当这个 NN 挂掉时,这个 znode 将会被删除,然后备用的NN 将会得到这把锁,升级为主 NN,同时标记状态为 Active
- 当宕机的 NN 新启动时,它会再次注册 zookeper,发现已经有 znode 锁了,便会自动变为 Standby 状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置 2 个 NN
- master 选举:通过在 zookeeper 中维持一个短暂类型的 znode,来实现抢占式的锁机制,从而判断那个 NameNode 为 Active 状态
Yarn HA
Yarn 作为资源管理系统,是上层计算框架(如 MapReduce,Spark)的基础。在 Hadoop2.4.0 版本之前,Yarn 存在单点故障(即 ResourceManager 存在单点故障),一旦发生故障,恢复时间较长,且会导致正在运行的 Application 丢失,影响范围较大。从 Hadoop 2.4.0版本开始,Yarn 实现了 ResourceManager HA,在发生故障时自动 failover,大大提高了服务的可靠性。
ResourceManager(简写为 RM)作为 Yarn 系统中的主控节点,负责整个系统的资源管理和调度,内部维护了各个应用程序的 ApplictionMaster 信息、NodeManager(简写为 NM)信息、资源使用等。由于资源使用情况和 NodeManager 信息都可以通过 NodeManager 的心跳机制重新构建出来,因此只需要对 ApplicationMaster 相关的信息进行持久化存储即可。
在一个典型的 HA 集群中,两台独立的机器被配置成 ResourceManger。在任意时间,有且只允许一个活动的 ResourceManger,另外一个备用。切换分为两种方式:
手动切换:在自动恢复不可用时,管理员可用手动切换状态,或是从 Active 到 Standby,或是从 Standby 到 Active。
自动切换:基于 Zookeeper,但是区别于 HDFS 的 HA,2 个节点间无需配置额外的 ZFKC守护进程来同步数据。

Hadoop High Availability高可用的更多相关文章
- Hadoop部署方式-高可用集群部署(High Availability)
版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客的高可用集群是建立在完全分布式基础之上的,详情请参考:https://www.cnblogs.com/yinzhengjie/p/90651 ...
- 大数据Hadoop的HA高可用架构集群部署
1 概述 在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题,幸运的是Hadoop 2.0.0之后解决了这个问题,即支持N ...
- hadoop和hbase高可用模式部署
记录apache版本的hadoop和hbase的安装,并启用高可用模式. 1. 主机环境 我这里使用的操作系统是centos 6.5,安装在vmware上,共三台. 主机名 IP 操作系统 用户名 安 ...
- Kafka(三)High Availability 高可用
参考文档: http://www.jasongj.com/2015/04/24/KafkaColumn2/#ACK%E5%89%8D%E9%9C%80%E8%A6%81%E4%BF%9D%E8%AF% ...
- 搭建Hadoop的HA高可用架构(超详细步骤+已验证)
一.集群的规划 Zookeeper集群: 192.168.182.12 (bigdata12)192.168.182.13 (bigdata13)192.168.182.14 (bigdata14) ...
- 【Hadoop故障处理】高可用(HA)环境DataNode问题
[故障背景] NameNode和DataNode进程正常运行,但是网页找不到DataNode,DataNode为空.各个节点机器之间可以ping同主机名. [日志排查] 众多日志中找到如下关键点错误信 ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- hadoop在zookeeper上的高可用HA
(参考文章:https://www.linuxprobe.com/hadoop-high-available.html) 一.技术背景 影响HDFS集群不可用主要包括以下两种情况:一是NameNode ...
- 配置LVS + Keepalived高可用负载均衡集群之图文教程
负载均衡系统可以选用LVS方案,而为避免Director Server单点故障引起系统崩溃,我们可以选用LVS+Keepalived组合保证高可用性. 重点:每个节点时间都同步哈! C++代码 [r ...
随机推荐
- mysql出现 Unknown column 'bname' in 'where clause'和Unknown column 'bid' in 'field list'
在用mysql数据库建表和修改数据库数据时,出现 Unknown column 'bname' in 'where clause'和Unknown column 'bid' in 'field li ...
- IO概念解析------同步异步阻塞非阻塞
各个IO Model的比较如图所示: 阻塞和非阻塞强调的是程序在等待调用结果(消息,返回值)时的状态. 阻塞调用是指调用结果返回之前,当前线程会被挂起.调用线程只有在得到结果之后才会返回.非阻塞调用 ...
- 初次使用github的艰难尝试。
序言 github是全英文的网站,初次使用在没有翻译成中文的情况下很容易做出很多无意义或误操作. 当对本地的文件进行修改后,有时候只是想更新到fork下来的自己的仓库里,看看改得效果如何 .有时候是想 ...
- DataTable对象
DataTable表示一个内存中的关系数据表,可以独立创建和使用,也可以有其他.NET Framework对象使用,最常见的情况是作为DataSet的成员使用.DataTable对象由DataColu ...
- hadoop集群搭建过程中遇到的问题
在安装配置Hadoop集群的过程中遇到了很多问题,有些是配置导致的,有些是linux系统本身的问题造成的,现在总结如下. 1. hdfs namenode -format出现错误:hdfs namen ...
- HttpUtils 封装类
作为一个web开发人员,对Http 请求,并不陌生.有时候,我们请求的时候,需要使用代码实现,一般情况,我们使用Apache Jakarta Common 下的子项目.的HttpClient. 可是我 ...
- mysql linux下表名忽略大小写注意事项
在Unix中使用lower_case_tables_name=0,在Windows中使用lower_case_tables_name=2.这样了可以保留数据库名和表名的大小写.不利之处是必须确保在Wi ...
- MySQL事务实现原理
MySQL事务隔离级别的实现原理 知识储备 只有InnoDB支持事务,所以这里说的事务隔离级别是指InnoDB下的事务隔离级别 隔离级别 读未提交:一个事务可以读取到另一个事务未提交的修改.这会带来脏 ...
- log4j记录日志 和 webAppRootKey关系
今天发现一个问题,就是后台从某天开始不再记录日志了,最后发现是 webAppRootKey 的 value 的值必须要和log4j的注入变量要一致. 如下:web.xml文件的 webAppRootK ...
- [转]error MSB4018: The "GenerateResource" task failed unexpectedly
本文转自:https://github.com/Microsoft/msbuild/issues/364 After uninstall Visual Studio 2015 Update 1 RC ...