HDFS 机架感知与副本放置策略
HDFS 机架感知与副本放置策略
机架感知(RackAwareness)
通常,大型 Hadoop 集群会分布在很多机架上,在这种情况下,
- 希望不同节点之间的通信能够尽量发生在同一个机架之内,而不是跨机架。
- 为了提高容错能力,名称节点会尽可能把数据块的副本放到多个机架上。
综合考虑这两点的基础上 Hadoop 设计了机架感知功能
外在脚本实现机架感知
HDFS 不能够自动判断集群中各个 DataNode 的网络拓扑情况。这种机架感知需要 net.topology.script.file.name 属性定义的可执行文件(或者脚本)来实现,文件提供了 DataNode 的IP 地址与机架 rackid 之间的映射关系。NameNode 通过这个映射关系,获得集群中各个 DataNode 机器的机架 rackid。如果 topology.script.file.name 没有设定,则每个 DataNode 的 IP地址都会默认映射成 default-rack,即可同一个机架。
为了获取机架 rackid,可以写一个小脚本来定义 DataNode 的 IP 地址(或DNS域名),并把想要的机架 rackid 打印到标准输出 stdout
这个脚本必须要在配置文件 hadoop-site.xml 里通过属性 ’net.topology.script.file.name’ 来指定。
<property>
<name>net.topology.script.file.name</name>
<value>/root/apps/hadoop-3.2.1/topology.py</value>
</property>
用 Python 语言编写的脚本范例:
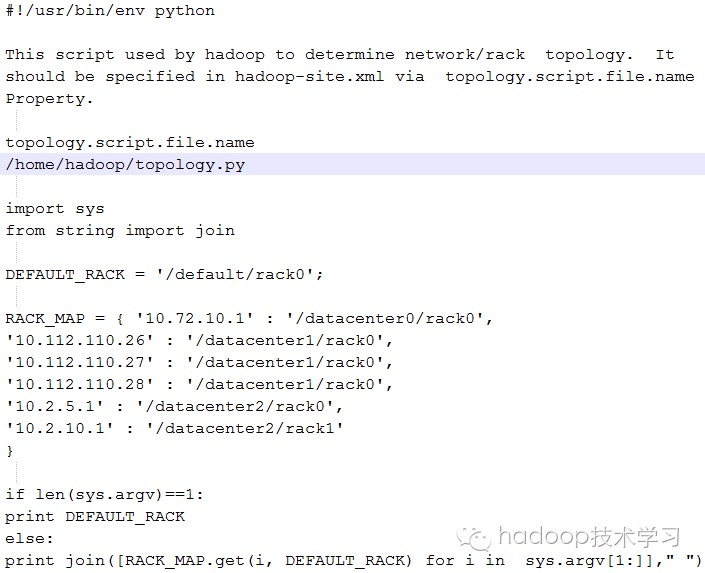
内部Java类实现机架感知
该处采用配置 topology.node.switch.mapping.impl 来实现机架感知,需在 core-site.xml 配置文件中加入以下配置项:
<property>
<name>topology.node.switch.mapping.impl</name>
<value>com.dmp.hadoop.cluster.topology.JavaTestBasedMapping</value>
</property>
还需编写一个JAVA类,一个示例如下所示:
public class JavaTestBasedMapping implements DNSToSwitchMapping {
//key:ip value:rack
private staticConcurrentHashMap<String,String> cache = new ConcurrentHashMap<String,String>();
static {
//rack0 16
cache.put("192.168.5.116","/ht_dc/rack0");
cache.put("192.168.5.117","/ht_dc/rack0");
cache.put("192.168.5.118","/ht_dc/rack0");
cache.put("192.168.5.120","/ht_dc/rack0");
cache.put("192.168.5.121","/ht_dc/rack0");
cache.put("host116","/ht_dc/rack0");
cache.put("host117","/ht_dc/rack0");
cache.put("host118","/ht_dc/rack0");
cache.put("host120","/ht_dc/rack0");
cache.put("host121","/ht_dc/rack0");
}
@Override
publicList<String> resolve(List<String> names) {
List<String>m = new ArrayList<String>();
if (names ==null || names.size() == 0) {
m.add("/default-rack");
return m;
}
for (Stringname : names) {
Stringrack = cache.get(name);
if (rack!= null) {
m.add(rack);
}
}
return m;
}
}
将上述Java类打成jar包,加上执行权限;然后放到$HADOOP_HOME/lib目录下运行。
网络拓扑(NetworkTopology)
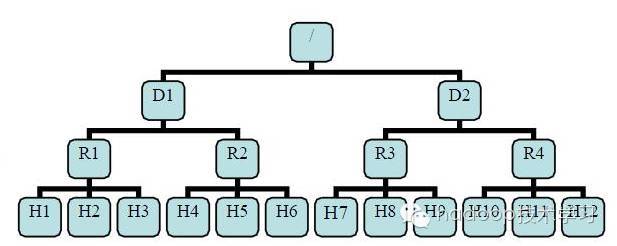
有了机架感知,NameNode 就可以画出上图所示的 DataNode 网络拓扑图。D1,R1都是交换机,最底层是 DataNode。则H1 的 rackid=/D1/R1/H1,H1 的 parent 是R1,R1 的是 D1。这些机架 rackid 信息可以通过 net.topology.script.file.name配置。有了这些机架 rackid 信息就可以计算出任意两台 DataNode 之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
副本放置策略(BPP:blockplacement policy)
- 第一个 block 副本放在和客户端所在的 node 里(如果client不在集群范围内,则这第一个node是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node)。
- 第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
- 第三个副本和第二个在同一个机架,随机放在不同的node中。
如果还有更多的副本,则在遵循以下限制的前提下随机放置。
- 1个节点最多放置1个副本
- 如果副本数少于2倍机架数,不可以在同一机架放置超过2个副本
当发生数据读取的时候,NameNode 节点首先检查客户端是否位于集群中。如果是的话,就可以按照由近到远的优先次序决定由哪个 DataNode 节点向客户端发送它需要的数据块。也就是说,对于拥有同一数据块副本的节点来说,在网络拓扑中距离客户端近的节点会优先响应。
Hadoop 的副本放置策略在可靠性(block 在不同的机架)和带宽(一个管道只需要穿越一个网络节点)中做了一个很好的平衡。
下图是副本数量为3的情况下一个管道的三个 DataNode的分布情况
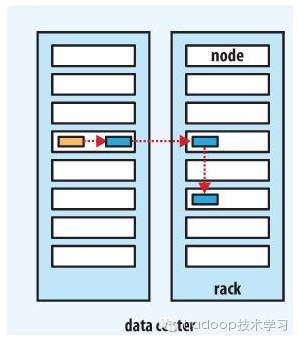
HDFS 机架感知与副本放置策略的更多相关文章
- HDFS副本放置策略和机架感知
副本放置策略 的副本放置策略的基本思想是: 第一block在复制和client哪里node于(假设client它不是群集的范围内,则这第一个node是随机选取的.当然系统会尝试不选择哪些太满或者太忙的 ...
- HDFS网络拓扑概念及机架感知(副本节点选择)
网络拓扑概念 在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺.这里将两个节点间的带宽作为距离的衡量标准. 节点距离:两个节点 ...
- HDFS机架感知功能原理(rack awareness)
转自:http://www.jianshu.com/p/372d25352d3a HDFS NameNode对文件块复制相关所有事物负责,它周期性接受来自于DataNode的HeartBeat和Blo ...
- hadoop(三):hdfs 机架感知
client 向 Active NN 发送写请求时,NN为这些数据分配DN地址,HDFS文件块副本的放置对于系统整体的可靠性和性能有关键性影响.一个简单但非优化的副本放置策略是,把副本分别放在不同机架 ...
- [HDFS_add_3] HDFS 机架感知
0. 说明 HDFS 副本存放策略 && 配置机架感知 1. HDFS 的副本存放策略 HDFS 的副本存放策略是将一个副本存放在本地机架节点上,另外两个副本放在不同机架的不同节点上 ...
- Hadoop 副本放置策略的源码阅读和设置
本文通过MetaWeblog自动发布,原文及更新链接:https://extendswind.top/posts/technical/hadoop_block_placement_policy 大多数 ...
- 014_HDFS存储架构、架构可靠性分析、副本放置策略、各组件之间的关系
1.HDFS存储架构
- HDFS副本放置策略
1.第一个副本放置在上传文件的DataNode上,如果是集群外提交,则随机挑选一个磁盘不太满,CPU不太忙的节点. 2.第二个副本放置在与第一个副本不同的机架上. 3.第三个副本放置在与第二个副本同机 ...
- hdfs 机架感知
一.背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高 ...
- HDFS机架感知
Hadoop版本:2.9.2 什么是机架感知 通常大型 Hadoop 集群是以机架的形式来组织的,同一个机架上的不同节点间的网络状况比不同机架之间的更为理想,NameNode 设法将数据块副本保存在不 ...
随机推荐
- 为什么 .NET应用推荐使用 await、async异步编程?
前言 1.什么是async/await? await和async是.NET Framework 4.5框架.C#5.0语法里面出现的技术,目的是用于简化异步编程模型. 2.async和await的关系 ...
- 了解了一下Cookie
昨天做接口测试被Cookie折腾得云里雾里的,今天下午有时间特意了解了一下. 一:Edge浏览器查看Cookie的路径:设置->Cookie和网站权限 二:一个cookies包含以下信息:(1) ...
- pytest 之conftest.py是什么
conftest.py是pytest框架的固定写法:可以把hook和fixture写在这个文件里,就会自动去调用:conftest.py相当于可以编写自己的插件: 也可以理解为pytest特有的本地测 ...
- 配置代码片段问题 Invalid characters in string. Control characters must be escaped.
在使用代码片段时报错 Invalid characters in string. Control characters must be escaped. " somethings" ...
- py正则与re模块
正则表达式符号介绍 按照博客中的表格罗列的去记即可 了解 \w,\s,\d与\W,\S,\D相反的匹配关系(对应的两者结合就是匹配全局) \t匹配制表符 \b匹配结尾的指定单词 优先掌握 ^:以什么什 ...
- linux 复合页( Compound Page )的介绍
1.复合页的定义: 复合页(Compound Page)就是将物理上连续的两个或多个页看成一个独立的大页,它可以用来创建hugetlbfs中使用的大页(hugepage), 也可以用来创建透明大页( ...
- OSPF配置常用命令知识总结
OSPF配置常用命令知识总结 1.display ospf abr-asbr 命令用来显示OSPF的区域边界路由器和自治系统边界路由器信息. [R3]dis ospf abr-asbr OSPF Pr ...
- NSQ(6)-nsq相关策略
1:nsq的流量控制 RDY 消息中间件的实现无非两种套路,一种让客户端pull,典型的比如kafka便是如此,而另一种则是push,也就是让客户端不需要做任何操作,只需要做好conn便可以源源不断收 ...
- Python学习:画K帮
import datetime import pandas_datareader.data as web df_stockload = web.DataReader("600797.SS&q ...
- jquery获取单选按钮选中的值
jQuery 取选中的radio的值方法 var val=$('input:radio[name="sex"]:checked').val(); 附三种方法都可以: $('inpu ...