Split to Be Slim: 论文复现
摘要:在本论文中揭示了这样一种现象:一层内的许多特征图共享相似但不相同的模式。
本文分享自华为云社区《Split to Be Slim: 论文复现》,作者: 李长安 。
Split to Be Slim: An Overlooked Redundancy in Vanilla Convolution 论文复现
1、问题切入
已经提出了许多有效的解决方案来减少推理加速模型的冗余。然而,常见的方法主要集中在消除不太重要的过滤器或构建有效的操作,同时忽略特征图中的模式冗余。
在本论文中揭示了这样一种现象:一层内的许多特征图共享相似但不相同的模式。但是,很难确定具有相似模式的特征是否是冗余的或包含基本细节。因此,论文作者不是直接去除不确定的冗余特征,而是提出了一种基于分割的卷积操作,即 SPConv,以容忍具有相似模式但需要较少计算的特征。
具体来说,论文将输入特征图分为Representative部分和不Uncertain冗余部分,其中通过相对繁重的计算从代表性部分中提取内在信息,而对不确定冗余部分中的微小隐藏细节进行一些轻量级处理手术。为了重新校准和融合这两组处理过的特征,我们提出了一个无参数特征融合模块。此外,我们的 SPConv 被制定为以即插即用的方式替换 vanilla 卷积。在没有任何花里胡哨的情况下,基准测试结果表明,配备 SPConv 的网络在 GPU 上的准确性和推理时间上始终优于最先进的基线,FLOPs 和参数急剧下降。
2、特征冗余问题

然而,如上图所示,同一层的特征中存在相似模式,也就是说存在特征冗余问题。但同时,并未存在完全相同的两个通道特征,进而导致无法直接剔除冗余通道特征。 因此,可以选择一些有代表性的特征图来补充内在信息,而剩余的冗余只需要补充微小的不同细节。
3、SPConv详解
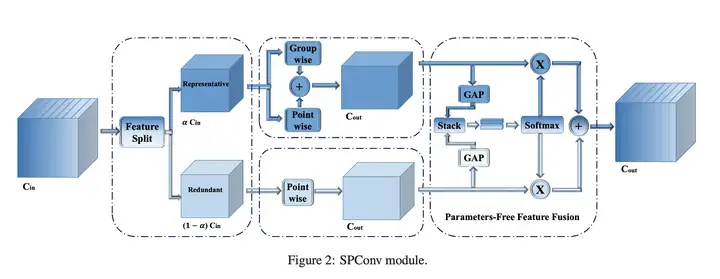
在现有的滤波器中,比如常规卷积、GhostConv、OctConv、HetConv均在所有输入通道上执行k*k卷积。然而,如上图所示,同一层的特征中存在相似模式,也就是说存在特征冗余问题。但同时,并未存在完全相同的两个通道特征,进而导致无法直接剔除冗余通道特征。
受此现象启发,作者提出将所有输入特征按比例拆分为两部分:
- Representative部分执行k*k卷积提取重要信息;
- Uncertain部分执行1*1卷积补充隐含细节信息。
因此该过程可以描述为(见SPConv的左侧部分),公式如下图所示:
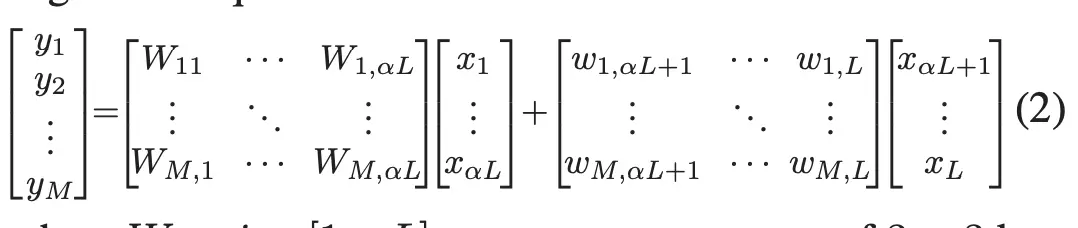
3.1 Further Reduction for Reprentative
在将所有输入通道分成两个主要部分后,代表部分之间可能存在冗余。换句话说,代表通道可以分为几个部分,每个部分代表一个主要类别的特征,例如颜色和纹理。因此,我们在代表性通道上采用组卷积以进一步减少冗余,如图 2 的中间部分所示。我们可以将组卷积视为具有稀疏块对角卷积核的普通卷积,其中每个块对应于通道,并且分区之间没有连接。这意味着,在组卷积之后,我们进一步减少了代表性部分之间的冗余,同时我们还切断了可能不可避免地有用的跨通道连接。我们通过在所有代表性通道上添加逐点卷积来弥补这种信息丢失。与常用的组卷积后点卷积不同,我们在相同的代表性通道上进行 GWC 和 PWC。然后我们通过直接求和来融合这两个结果特征,因为它们具有相同的通道来源,从而获得了额外的分数(这里我们将组大小设置为 2)。所以方程2的代表部分可以表述为方程3:
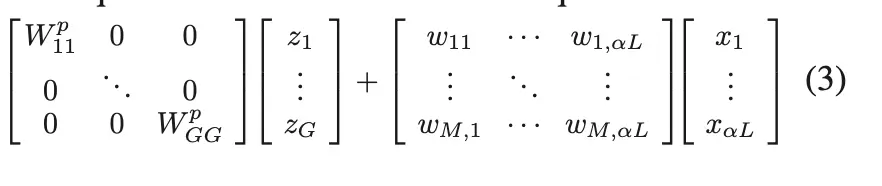
3.2 Parameter Free Feature Fusion Module
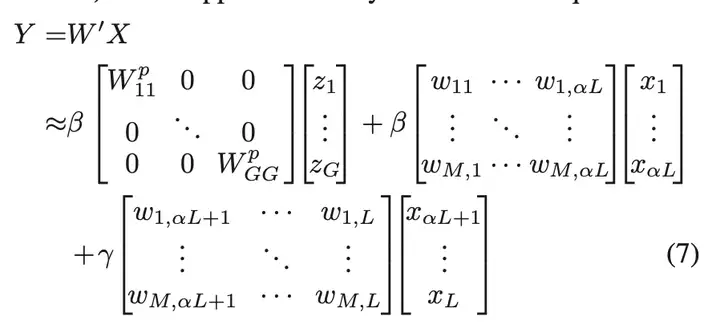
到目前为止,我们已经将 vanilla 3×3 卷积拆分为两个操作:对于代表部分,我们进行 3×3 组卷积和 1×1 逐点卷积的直接求和融合,以抵消分组信息丢失;对于冗余部分,我们应用 1 × 1 内核来补充一些微小的有用细节。结果,我们得到了两类特征。因为这两个特征来自不同的输入通道,所以需要一种融合方法来控制信息流。与等式 2 的直接求和融合不同,我们为我们的 SP-Conv 设计了一个新颖的特征融合模块,无需导入额外的参数,有助于实现更好的性能。如图 2 右侧所示,
3.3 代码复现
import paddle
import paddle.nn as nn
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2D(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, dilation=dilation)
class SPConv_3x3(nn.Layer):
def __init__(self, inplanes=32, outplanes=32, stride=1, ratio=0.5):
super(SPConv_3x3, self).__init__()
self.inplanes_3x3 = int(inplanes*ratio)
self.inplanes_1x1 = inplanes - self.inplanes_3x3
self.outplanes_3x3 = int(outplanes*ratio)
self.outplanes_1x1 = outplanes - self.outplanes_3x3
self.outplanes = outplanes
self.stride = stride
self.gwc = nn.Conv2D(self.inplanes_3x3, self.outplanes, kernel_size=3, stride=self.stride,
padding=1, groups=2)
self.pwc = nn.Conv2D(self.inplanes_3x3, self.outplanes, kernel_size=1)
self.conv1x1 = nn.Conv2D(self.inplanes_1x1, self.outplanes,kernel_size=1)
self.avgpool_s2_1 = nn.AvgPool2D(kernel_size=2,stride=2)
self.avgpool_s2_3 = nn.AvgPool2D(kernel_size=2, stride=2)
self.avgpool_add_1 = nn.AdaptiveAvgPool2D(1)
self.avgpool_add_3 = nn.AdaptiveAvgPool2D(1)
self.bn1 = nn.BatchNorm2D(self.outplanes)
self.bn2 = nn.BatchNorm2D(self.outplanes)
self.ratio = ratio
self.groups = int(1/self.ratio)
def forward(self, x):
# print(x.shape)
b, c, _, _ = x.shape
x_3x3 = x[:,:int(c*self.ratio),:,:]
x_1x1 = x[:,int(c*self.ratio):,:,:]
out_3x3_gwc = self.gwc(x_3x3)
if self.stride ==2:
x_3x3 = self.avgpool_s2_3(x_3x3)
out_3x3_pwc = self.pwc(x_3x3)
out_3x3 = out_3x3_gwc + out_3x3_pwc
out_3x3 = self.bn1(out_3x3)
out_3x3_ratio = self.avgpool_add_3(out_3x3).squeeze(axis=3).squeeze(axis=2)
# use avgpool first to reduce information lost
if self.stride == 2:
x_1x1 = self.avgpool_s2_1(x_1x1)
out_1x1 = self.conv1x1(x_1x1)
out_1x1 = self.bn2(out_1x1)
out_1x1_ratio = self.avgpool_add_1(out_1x1).squeeze(axis=3).squeeze(axis=2)
out_31_ratio = paddle.stack((out_3x3_ratio, out_1x1_ratio), 2)
out_31_ratio = nn.Softmax(axis=2)(out_31_ratio)
out = out_1x1 * (out_31_ratio[:,:,1].reshape([b, self.outplanes, 1, 1]).expand_as(out_1x1))\
+ out_3x3 * (out_31_ratio[:,:,0].reshape([b, self.outplanes, 1, 1]).expand_as(out_3x3))
return out
# paddle.summary(SPConv_3x3(), (1,32,224,224))
spconv = SPConv_3x3()
tmp = paddle.randn([1, 32, 224, 224])
conv_out1 = spconv(tmp)
print(conv_out1.shape)
W0724 22:30:03.841145 13041 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0724 22:30:03.845882 13041 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
[1, 32, 224, 224]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:654: UserWarning: When training, we now always track global mean and variance.
"When training, we now always track global mean and variance.")
4、消融实验
为验证所提方法的有效性,设置SPConv中的卷积核k=3,g=2,同时整个网络设置统一的全局超参数(不同阶段设置不同的会更优,但会过于精细)。
在小尺度数据集Cifar10、resnet18网络进行对比分析,为公平对比,所有实验均在含1个NVIDIA Tesla V100GPU的服务器上从头开始训练,且采用默认的数据增广与训练策略,不包含其他额外Tricks。
import paddle
from paddle.metric import Accuracy
from paddle.vision.transforms import Compose, Normalize, Resize, Transpose, ToTensor
from sp_resnet import resnet18_sp
callback = paddle.callbacks.VisualDL(log_dir='visualdl_log_res_sp')
normalize = Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5],
data_format='HWC')
transform = Compose([ToTensor(), Normalize(), Resize(size=(224,224))])
cifar10_train = paddle.vision.datasets.Cifar10(mode='train',
transform=transform)
cifar10_test = paddle.vision.datasets.Cifar10(mode='test',
transform=transform)
# 构建训练集数据加载器
train_loader = paddle.io.DataLoader(cifar10_train, batch_size=128, shuffle=True, drop_last=True)
# 构建测试集数据加载器
test_loader = paddle.io.DataLoader(cifar10_test, batch_size=128, shuffle=True, drop_last=True)
res_sp = paddle.Model(resnet18_sp(num_classes=10))
optim = paddle.optimizer.Adam(learning_rate=3e-4, parameters=res_sp.parameters())
res_sp.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
res_sp.fit(train_data=train_loader,
eval_data=test_loader,
epochs=10,
callbacks=callback,
verbose=1
)
import paddle
from paddle.metric import Accuracy
from paddle.vision.transforms import Compose, Normalize, Resize, Transpose, ToTensor
from paddle.vision.models import resnet18
callback = paddle.callbacks.VisualDL(log_dir='visualdl_log_res_18')
normalize = Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5],
data_format='HWC')
transform = Compose([ToTensor(), Normalize(), Resize(size=(224,224))])
cifar10_train = paddle.vision.datasets.Cifar10(mode='train',
transform=transform)
cifar10_test = paddle.vision.datasets.Cifar10(mode='test',
transform=transform)
# 构建训练集数据加载器
train_loader = paddle.io.DataLoader(cifar10_train, batch_size=128, shuffle=True, drop_last=True)
# 构建测试集数据加载器
test_loader = paddle.io.DataLoader(cifar10_test, batch_size=128, shuffle=True, drop_last=True)
res_18 = paddle.Model(resnet18(num_classes=10))
optim = paddle.optimizer.Adam(learning_rate=3e-4, parameters=res_18.parameters())
res_18.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
res_18.fit(train_data=train_loader,
eval_data=test_loader,
epochs=10,
callbacks=callback,
verbose=1
)
5、实验结果分析
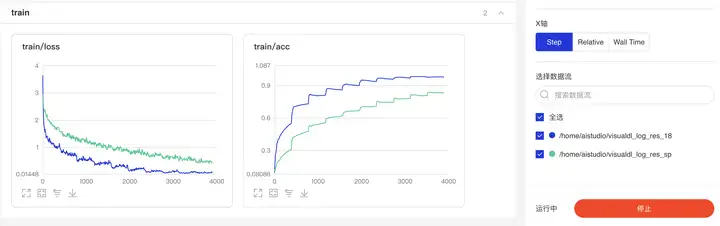
最后,我们再来看一下消融实验结果,见下图。可以看到:
- 添加了SPConV模块的ResNet18效果反而不如原始的ResNet18
在原作中,作者给出了ResNet20、VGG16在数据集Cifar10上的对比结果,原因也可能在于本实验中模型迭代次数不够,但是相比来看,特征图在进行了去冗余操作之后(类似于剪枝),精度下降似乎是正确的。
6、总结
在该文中,作者重新对常规卷积中的信息冗余问题进行了重思考,为缓解该问题,作者提出了一种新颖的SPConv,它将输入特征拆分为两组不同特征并进行不同的处理,最后采用简化版SK进行融合。最后作者通过充分的实验分析说明了所提方法的有效性,在具有更高精度的时候具有更快的推理速度、更少的FLOPs与参数量。
所提SPConv是一种“即插即用”型单元,它可以轻易与其他网络架构相结合,同时与当前主流模型压缩方法互补,如能精心组合设计,有可能得到更轻量型的模型。
7、参考资料
即插即用!北邮&南开大学开源SPConv:精度更高、速度更快的卷积
Split to Be Slim: An Overlooked Redundancy in Vanilla Convolution
Split to Be Slim: 论文复现的更多相关文章
- 【IJCAI2020】Split to Be Slim: An Overlooked Redundancy in Vanilla Convolution
Split to Be Slim: An Overlooked Redundancy in Vanilla Convolution, IJCAI 2020 论文地址: https://arxiv.or ...
- FCOS论文复现:通用物体检测算法
摘要:本案例代码是FCOS论文复现的体验案例,此模型为FCOS论文中所提出算法在ModelArts + PyTorch框架下的实现.本代码支持FCOS + ResNet-101在MS-COCO数据集上 ...
- Visualizing and Understanding Convolutional Networks论文复现笔记
目录 Visualizing and Understanding Convolutional Networks 论文复现笔记 Abstract Introduction Approach Visual ...
- 论文复现|Panoptic Deeplab(全景分割PyTorch)
摘要:这是发表于CVPR 2020的一篇论文的复现模型. 本文分享自华为云社区<Panoptic Deeplab(全景分割PyTorch)>,作者:HWCloudAI . 这是发表于CVP ...
- Facebook 发布深度学习工具包 PyTorch Hub,让论文复现变得更容易
近日,PyTorch 社区发布了一个深度学习工具包 PyTorchHub, 帮助机器学习工作者更快实现重要论文的复现工作.PyTorchHub 由一个预训练模型仓库组成,专门用于提高研究工作的复现性以 ...
- 小白经典CNN论文复现系列(一):LeNet1989
小白的经典CNN复现系列(一):LeNet-1989 之前的浙大AI作业的那个系列,因为后面的NLP的东西我最近大概是不会接触到,所以我们先换一个系列开始更新博客,就是现在这个经典的CNN复现啦(。・ ...
- 自监督图像论文复现 | BYOL(pytorch)| 2020
继续上一篇的内容,上一篇讲解了Bootstrap Your Onw Latent自监督模型的论文和结构: https://juejin.cn/post/6922347006144970760 现在我们 ...
- 复现ICCV 2017经典论文—PyraNet
. 过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“伪代码”.这是今年 AAAI 会议上一个严峻的 ...
- [论文理解] LFFD: A Light and Fast Face Detector for Edge Devices
LFFD: A Light and Fast Face Detector for Edge Devices 摘要 从微信推文中得知此人脸识别算法可以在跑2K图片90fps,仔细一看是在RTX2070下 ...
- 小白的经典CNN复现(三):AlexNet
小白的经典CNN复现(三):AlexNet 锵锵--本系列的第三弹AlexNet终于是来啦(≧∀≦),到了这里,我们的CNN的结构就基本上和现在我们经常使用或者接触的一些基本结构差不多了,并且从这一个 ...
随机推荐
- 实验2 C语言分支语句、循环语句应用编程
一.实验目的 掌握格式化输出函数printf()和格式化输入函数scanf()的用法 掌握单个字符输出函数putchar()和单个字符输入函数getchar()的用法 理解结构化程序设计的三种基本结构 ...
- Delphi集合增删的另一种操作
D7 1 unit Unit1; 2 3 interface 4 5 uses 6 Windows, Messages, SysUtils, Variants, Classes, Graphics, ...
- Pytorch中tensor的打印精度
1. 设置打印精 Pytorch中tensor打印的数据长度需要使用torch.set_printoptions(precision=xx)进行设置,否则打印的长度会很短,给人一种精度不够的错觉: & ...
- springboot的websocket因IP问题无法连接
首先遇到这个问题有点奇葩,出现在项目上线时的客户现场,头两天一直都无法确定原因,因为它的表现方式很奇怪,基于springboot实现的websocket,同样的代码在公司研发环境不会有问题,客户现场会 ...
- 使用loadrunner运行中问题(无代码生成解决方法)
开始录制之后,不能成功录制,工具栏events一直是2,打开新网站不跳动,结束录制之后没有代码生成 进入软件,点击工具栏的录制,选择录制选项,将http高级如下设置 同时也要修改套接字,如下配置 当开 ...
- element表格数据v-for替换期望文字
后端返回等级编码 "1","2"....并给你一个字典obj[ {dicCode: "4", dictFlag: "riskLev ...
- 一个关于 Linux环境下输出操作符 >和>>的问题
[>和>>的区别]命令>文件,表示以覆盖的方式,把命令正确输出到指定的文件或者设备当中:命令>>文件,表示以追加的方式,把命令正确输出到指定的文件或者设备当中. [ ...
- GO语言学习笔记-方法篇 Study for Go ! Chapter five - Method
持续更新 Go 语言学习进度中 ...... GO语言学习笔记-类型篇 Study for Go! Chapter one - Type - slowlydance2me - 博客园 (cnblogs ...
- Javaweb知识复习--MyBatis+Mapper代理开发
一种持久层框架,主要用于简化JDBC MyBatis应用步骤 1.在数据库里面创建一个表 2.创建模块,导入坐标 就是新建一个Maven项目,在pom.xml里面导入mybatis相应导包依赖代码: ...
- Spring Data Redis 框架
系统性学习,移步IT-BLOG 一.简介 对于类似于首页这种每天都有大量的人访问,对数据库造成很大的压力,严重时可能导致瘫痪.解决方法:一种是数据缓存.一种是网页静态化.今天就讨论数据缓存的实现 Re ...