Transformer_Detection-(DETR) 引入视觉领域的首创DETR (ECCV2020)
End-to-End Object Detection with Transformers
paper: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2005.12872
project: https://github.com/facebookresearch/detr
Highlight: 端到端的目标检测,实现了真正的end-to-end,把检测问题视作是一个set prediction problem
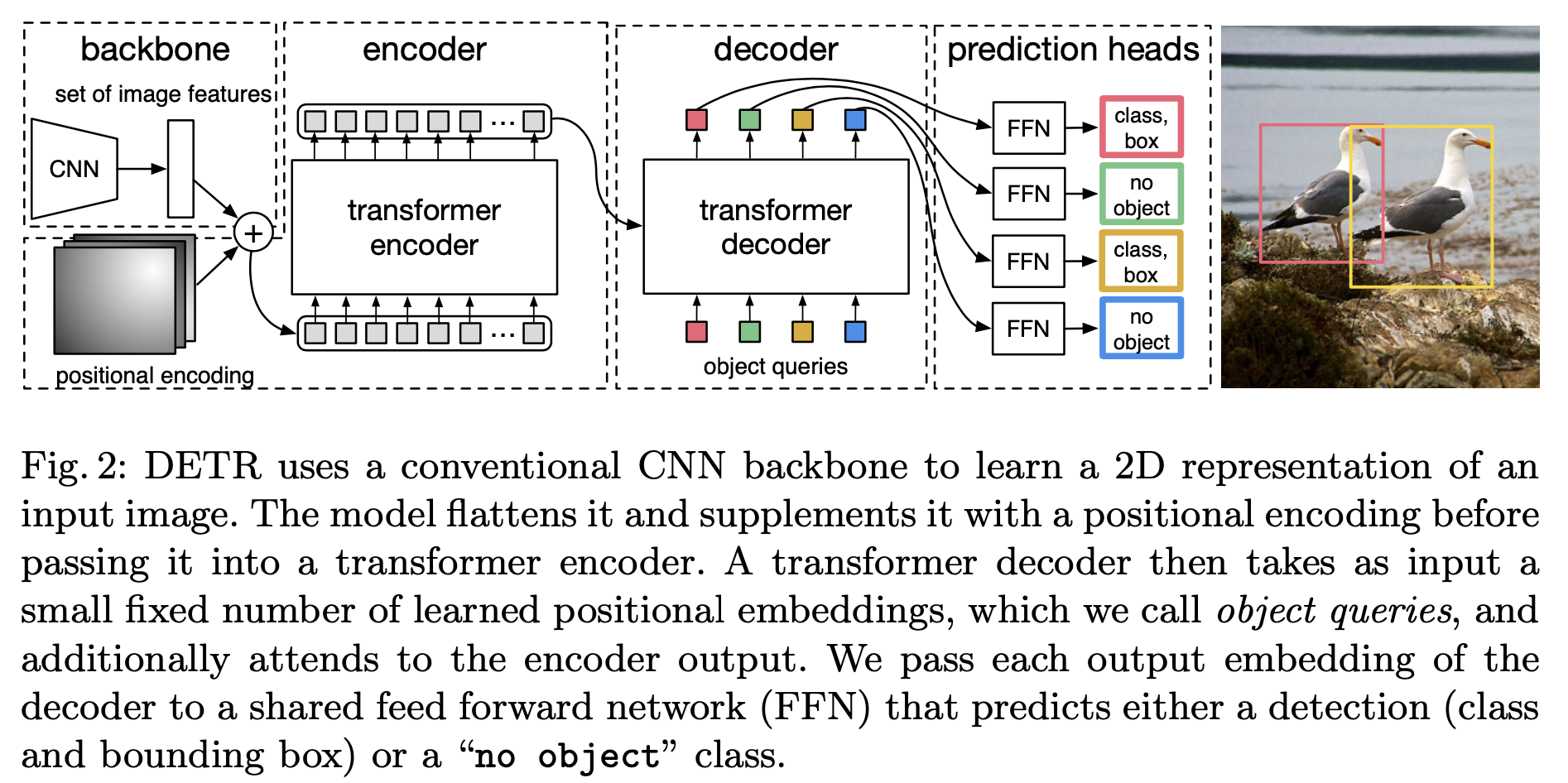
Step1: 利用CNN获取浅层特征(feature map)与位置编码进行相加,作为encoder的输入
Step2: Decoder一次性处理全部的object queries,即一次性输出全部的预测。而不像原始的Transformer从左到右一个词一个词地输出。
Decoder的输入由两部分组成:encoder的输出和object queries ;object queries是一个可学习的张量,矩阵内部通过学习建模了100个物体之间的全局关系,在推理的时候就可以利用全局注意力进行更好的解码预测输出
训练:训练集里面的一张图像,通过模型产生100个预测框,但这张图像内只有3个GT框,利用匈牙利算法(找到最优匹配关系)计算得到这3个GT框对应的label,并计算Loss;把所有的图片按照这个模式进行训练
训练完以后,模型学习到了一种能力,即:模型产生的100个预测框,它知道某个预测框该对应什么 ;个人理解其实训练的过程就是学习object queries矩阵的过程,训练结束之后,此时的Object queries看成100个格子,每个格子是个256维的向量。训练完以后,这100个格子里面注入了不同
的位置信息和类别信息。比如第1个格子里面的这个256维的向量代表着某个物体这种
的位置信息,这种信息是通过训练,考虑了所有图片的某个位置附近的该物体编码特征,属于和位置有关的全局统计信息。
可以将测试想象成匹配问题,Q想要寻找某个物体的特征,然后与获取到输入图像的特征(也就是K和V)进行匹配。
Transformer_Detection-(DETR) 引入视觉领域的首创DETR (ECCV2020)的更多相关文章
- paper 94:视觉领域博客资源1之中国部分
这是收录的图像视觉领域的博客资源的第一部分,包含:中国内地.香港.台湾 这些名人大家一般都熟悉,本文仅收录了包含较多资料的个人博客,并且有不少更新,还有些名人由于分享的paper.code或者数据集不 ...
- DeepMind已将AlphaGo引入多领域 Al泡沫严重
DeepMind已将AlphaGo引入多领域 Al泡沫严重 在稳操胜券的前提下,谷歌旗下的AlphaGo还是向柯洁下了战书.4月10日,由中国围棋协会.浙江省体育局.谷歌三方联合宣布,将于5月23日至 ...
- MoCo V1:视觉领域也能自监督啦
何凯明从 CVPR 2020 上发表的 MoCo V1(Momentum Contrast for Unsupervised Visual Representation Learning),到前几天挂 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(三)引入视觉哨兵的自适应attention机制
在此前的两篇博客中所介绍的两个论文,分别介绍了encoder-decoder框架以及引入attention之后在Image Caption任务上的应用. 这篇博客所介绍的文章所考虑的是生成captio ...
- paper 14 : 图像视觉领域部分开源代码
做图像处理,没有一定的知识储备是不可能的,但是一定要学会“借力打力”,搜集一些很实用的开源代码,你们看看是否需要~~ 场景识别: SegNet: A Deep Convolutional Encode ...
- Deformable 可变形的DETR
Deformable 可变形的DETR This repository is an official implementation of the paper Deformable DETR: Defo ...
- (转) SLAM系统的研究点介绍 与 Kinect视觉SLAM技术介绍
首页 视界智尚 算法技术 每日技术 来打我呀 注册 SLAM系统的研究点介绍 本文主要谈谈SLAM中的各个研究点,为研究生们(应该是博客的多数读者吧)作一个提纲挈领的摘要.然后,我 ...
- 转:SLAM算法解析:抓住视觉SLAM难点,了解技术发展大趋势
SLAM(Simultaneous Localization and Mapping)是业界公认视觉领域空间定位技术的前沿方向,中文译名为“同步定位与地图构建”,它主要用于解决机器人在未知环境运动时的 ...
- 面向视频的全新AI架构 —— 阿里云智能视觉技术全解
我们都知道,AI技术正在以可见的速度被应用于各行各业,然而绝大部分业务场景想应用AI技术,都需要算法工程师根据自身业务的标注数据,来进行单独训练,才能打磨出合适的AI模型.如此一来,如何以最低的门槛和 ...
- ICCV2021 | Swin Transformer: 使用移位窗口的分层视觉Transformer
前言 本文解读的论文是ICCV2021中的最佳论文,在短短几个月内,google scholar上有388引用次数,github上有6.1k star. 本文来自公众号CV技术指南的论文分享系 ...
随机推荐
- npm vue-router安装报错
因为2022年2月7日以后,vue-router的默认版本,为4版本,而且 vue-router4,只能在vue3中,只有vue-router3中,能用在vue 2中 如果把vue-router4强制 ...
- 基2和基4FFT
1.1 FFT的必要索引变换 基2算法需要位顺序的反转位逆序,而基4算法需要首先构成一个2位的数字,再反转这些数字,称为数字逆序. 1.1 位逆序和数字逆序 1.2 FFT的复数乘法转实数乘法 \[X ...
- Python占位符总结:%方式和format方式
Python中,我们在预定义某类具有相似格式的变量或者输出一句含有多个变量的提示语句时,往往用到占位符,而占位符有两种表达方式: %方式: 下面这段代码摘自matplotlib的_init_.py文件 ...
- 基于Antlr的Modelica3.5语言解析
背景 Modelica语言是一种统一面向对象的系统建模语言 官方文档中明确写明了语法规范 在附录的第一章词法,第二章语法都完整的罗列的语言规范,对于Antlr适配特别好 只需要把[]修改为Antlr的 ...
- Gradle 安装配置
1 下载 官网各版本下载地址如下: https://gradle.org/releases/ 2 安装 将下载后的压缩包(此处以 gradle-6.5-all.zip 为例)解压到某个目录进行安装. ...
- DOS批处理命令,自动获取本机系统及硬件配置信息
可以配合域策略自动下发执行, 批量收集域内电脑配置; 手动执行亦可; 如下保存成.bat批处理文件执行即可. /*&cls&echo off&cd /d "%~dp0 ...
- iptables(一)基础概念、filter表常用语法规则
iptables简介 netfilter/iptables(简称为iptables)组成Linux平台下的包过滤防火墙,与大多数的Linux软件一样,这个包过滤防火墙是免费的,它可以代替昂贵的商业防火 ...
- UltiSnips安装及设置
2022-10-05 10:56:50 星期三 安装了UltiSnips插件,然后开始学习 第一个命令 UltiSnipsEdit 不好使,创建了~/.vim/UltiSnips 还是 can not ...
- java的Stream
代码 List<Student> all = Student.getAll(); // 转换成数组 过滤所有的男性 Student[] students = all.stream().fi ...
- Rsync已过时?替代文件同步软件了解一下
随着企业结构分散化的不断扩大,企业内部和企业间的信息互动更加频繁.越来越多的企业要求内部各种业务数据在服务器.数据中心甚至云上能够有实时的同步留存.所以,企业需要文件同步软件,通过在两个或更多设备之间 ...