pandas常用操作详解(复制别人的)——数据透视表操作:pivot_table()
原文链接:https://www.cnblogs.com/Yanjy-OnlyOne/p/11195621.html
一文看懂pandas的透视表pivot_table
一、概述
1.1 什么是透视表?
透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
1.2 为什么要使用pivot_table?
- 灵活性高,可以随意定制你的分析计算要求
- 脉络清晰易于理解数据
- 操作性强,报表神器
二、如何使用pivot_table
首先读取数据,数据集是火箭队当家球星James Harden某一赛季比赛数据作为数据集进行讲解。数据地址。
先看一下官方文档中pivot_table的函数体:pandas.pivot_table - pandas 0.21.0 documentation
pivot_table(data, values=None, index=None, columns=None,aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
pivot_table有四个最重要的参数index、values、columns、aggfunc,本文以这四个参数为中心讲解pivot操作是如何进行。
2.1 读取数据
- import pandas as pd
- import numpy as np
- df = pd.read_csv('h:/James_Harden.csv',encoding='utf8')
- df.tail()
数据格式如下:
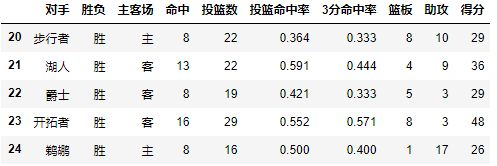
2.2 Index
每个pivot_table必须拥有一个index,如果想查看哈登对阵每个队伍的得分,首先我们将对手设置为index:
pd.pivot_table(df,index=[u'对手'])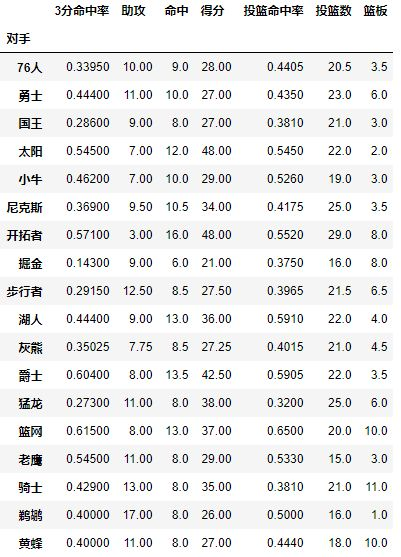
对手成为了第一层索引,还想看看对阵同一对手在不同主客场下的数据,试着将对手与胜负与主客场都设置为index,其实就变成为了两层索引
pd.pivot_table(df,index=[u'对手',u'主客场'])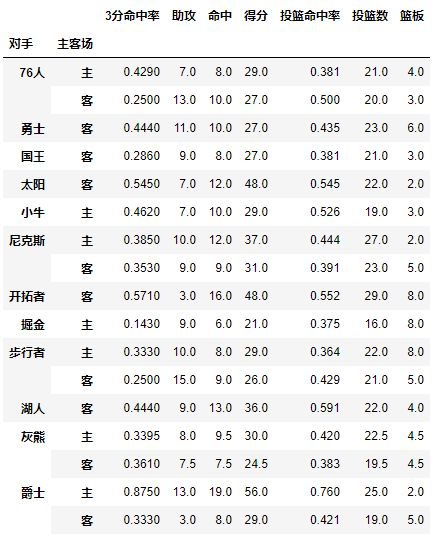
试着交换下它们的顺序,数据结果一样:
pd.pivot_table(df,index=[u'主客场',u'对手'])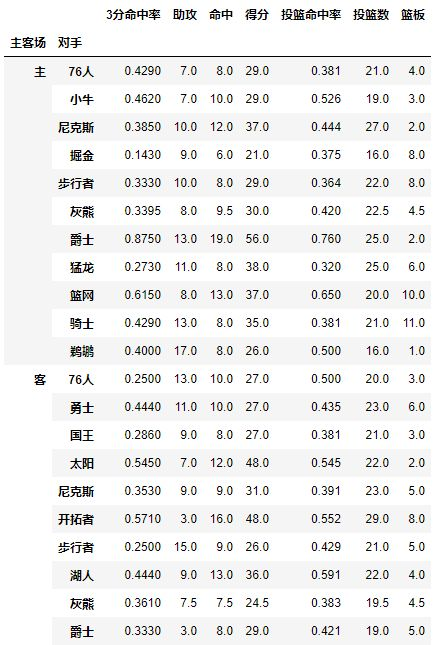
看完上面几个操作,Index就是层次字段,要通过透视表获取什么信息就按照相应的顺序设置字段,所以在进行pivot之前你也需要足够了解你的数据。
2.3 Values
通过上面的操作,我们获取了james harden在对阵对手时的所有数据,而Values可以对需要的计算数据进行筛选,如果我们只需要james harden在主客场和不同胜负情况下的得分、篮板与助攻三项数据:
pd.pivot_table(df,index=[u'主客场',u'胜负'],values=[u'得分',u'助攻',u'篮板'])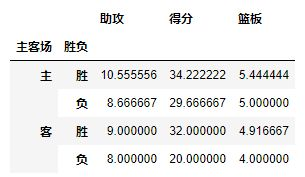
2.4 Aggfunc
aggfunc参数可以设置我们对数据聚合时进行的函数操作。
当我们未设置aggfunc时,它默认aggfunc='mean'计算均值。我们还想要获得james harden在主客场和不同胜负情况下的总得分、总篮板、总助攻时:
pd.pivot_table(df,index=[u'主客场',u'胜负'],values=[u'得分',u'助攻',u'篮板'],aggfunc=[np.sum,np.mean])
2.5 Columns
Columns类似Index可以设置列层次字段,它不是一个必要参数,作为一种分割数据的可选方式。
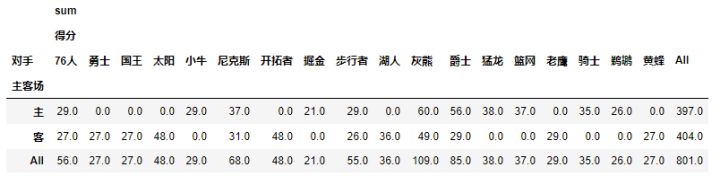
- #fill_value填充空值,margins=True进行汇总
- pd.pivot_table(df,index=[u'主客场'],columns=[u'对手'],values=[u'得分'],aggfunc=[np.sum],fill_value=0,margins=1)
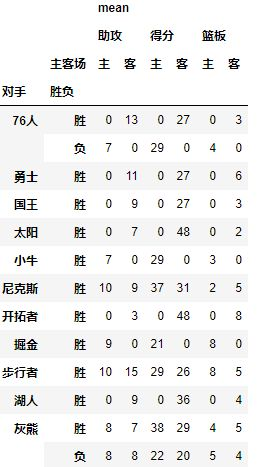
现在我们已经把关键参数都介绍了一遍,下面是一个综合的例子:
table=pd.pivot_table(df,index=[u'对手',u'胜负'],columns=[u'主客场'],values=[u'得分',u'助攻',u'篮板'],aggfunc=[np.mean],fill_value=0)结果如下:
aggfunc也可以使用dict类型,如果dict中的内容与values不匹配时,以dict中为准。
table=pd.pivot_table(df,index=[u'对手',u'胜负'],columns=[u'主客场'],values=[u'得分',u'助攻',u'篮板'],aggfunc={u'得分':np.mean, u'助攻':[min, max, np.mean]},fill_value=0)
结果就是助攻求min,max和mean,得分求mean,而篮板没有显示。
pandas常用操作详解(复制别人的)——数据透视表操作:pivot_table()的更多相关文章
- 小白学 Python 数据分析(12):Pandas (十一)数据透视表(pivot_table)
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- 【Excle数据透视表】如何复制数据透视表
左边创建完数据透视表,右边是复制过去的部分数据透视表---显示数值状态的内容,为什么复制过来的不是数据透视表呢? 解决办法: 全选定数据透视表再进行粘贴复制 步骤一 单击数据透视表任意单元格→分析→操 ...
- pandas常用操作详解——info()与descirbe()
概述 df.info():主要介绍数据集各列的数据类型,是否为空值,内存占用情况: df.describe(): 主要介绍数据集各列的数据统计情况(最大值.最小值.标准偏差.分位数等等). df.in ...
- VC++常用数据类型及其操作详解
原文地址:http://blog.csdn.net/ithomer/article/details/5019367 VC++常用数据类型及其操作详解 一.VC常用数据类型列表 二.常用数据类型转化 2 ...
- Pandas 常见操作详解
Pandas 常见操作详解 很多人有误解,总以为Pandas跟熊猫有点关系,跟gui叔创建Python一样觉得Pandas是某某奇葩程序员喜欢熊猫就以此命名,简单介绍一下,Pandas的命名来自于面板 ...
- Linux Shell数组常用操作详解
Linux Shell数组常用操作详解 1数组定义: declare -a 数组名 数组名=(元素1 元素2 元素3 ) declare -a array array=( ) 数组用小括号括起,数组元 ...
- SQLAlchemy02 /SQLAlchemy对数据的增删改查操作、属性常用数据类型详解
SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 目录 SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 1.用se ...
- SQLAlchemy(二):SQLAlchemy对数据的增删改查操作、属性常用数据类型详解
SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 目录 SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 1.用se ...
- [Android新手区] SQLite 操作详解--SQL语法
该文章完全摘自转自:北大青鸟[Android新手区] SQLite 操作详解--SQL语法 :http://home.bdqn.cn/thread-49363-1-1.html SQLite库可以解 ...
随机推荐
- Redis的最常被问到知识点总结 (转)
1.什么是redis? Redis 是一个基于内存的高性能key-value数据库. 2.Reids的特点 Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库 ...
- uniap tab list 滑动
效果如下 <uni-popup ref="bankListAll" type="dialog"> <ty-mutiple-select :mu ...
- JS实现new关键字的功能
一.前言 众所周知:没有对象怎么办?那就new一个! 那么在JS中,当我们new一个对象的时候,这个new关键字内部都干了什么呢? 现在我们就来剖析一下原生JS中new关键字内部的工作原理. 二.原始 ...
- MySQL事务以及存储引擎
MySQL事务以及存储引擎 目录 MySQL事务以及存储引擎 一.事务 1. 事务的概念 2. 事务的ACID特点 (1)原子性 (2)一致性 (3)隔离性 ①事务之间的相互影响 ②MySQL事务支持 ...
- python进阶(24)Python字典的底层原理以及字典效率
前言 问题1:python中的字典到底是有序还是无序 问题2:python中字典的效率如何 python字典底层原理 在Python 3.5以前,字典是不能保证顺序的,键值对A先插入字典,键值对B ...
- 计算机网络再次整理————tcp周边[八]
前言 tcp的包的格式可以看我以前的计算机网络整理,下面这些周边只是为了开发时候我们能用到一些理论知识. 正文 首先要介绍的就是域名,为啥有域名这东西呢?单纯站在网络的角度上讲这属于应用层的东西了. ...
- c++ 堆栈和内存管理
stack(栈),heap(堆) Stack:是存在于某作用域(scope)的一个内存空间(memory space).例如当你调用函数,函数本身即会形成一个stack用来放置它所接收的参数,返回地址 ...
- 利用LNMP实现wordpress站点搭建
一.部署MySQL 1.1 二进制安装mysql5.6 # 准备用户,依赖包,二进制程序 [root@nginx ~]# yum install -y libaio perl-Data-Dumper ...
- 大话devops
一.敏捷的局限性的促使devops诞生 敏捷的局限性:敏捷只注重开发阶段的敏捷,未涉及到整个产品生命周期流程其他环节导致采用敏捷开发流程后效果不明显. devops成为企业数字化转型的助推器,扮演基础 ...
- Solution -「ARC 126E」Infinite Operations
\(\mathcal{Description}\) Link. 给定序列 \(\{a_n\}\),定义一次操作为: 选择 \(a_i<a_j\),以及一个 \(x\in\mathbb R ...