解读论文《Agglomerative clustering of a search engine query log》,以解决搜索推荐相关问题
《Agglomerative clustering of a search engine query log》
论文作者:Doug Beeferman 本文将解读此篇论文,此论文利用搜索日志中的<query,url>类型点击日志,实现忽略目标url内容,基于搜索词条用户的点击数据,聚合相关搜索和连接的算法。(本解读文章个人辛苦之作,请勿随意转载 文章链接 https://www.cnblogs.com/jiaomaster/p/16271663.html)
背景
随着互联网规模的扩大和普及,现在有超过10亿个静态网页(作者所写的年份),一些商业搜索引擎每天处理数以千万计的查询对组织这些数据的自动方法的迫切需求已经发展。为大规模的非结构化数据集带来一定程度的秩序的一种策略是将相似的项分组在一起。本文介绍了一种技术,用于通过Internet搜索从用户事务集合中找到相关查询和相关url的集群。作者列举了一些常用的文档的聚类计算方法,如HAC,k-means,但是这些都基于文档内容,但作者提出了一种基于用户点击数据日志的方法。
点击数据介绍
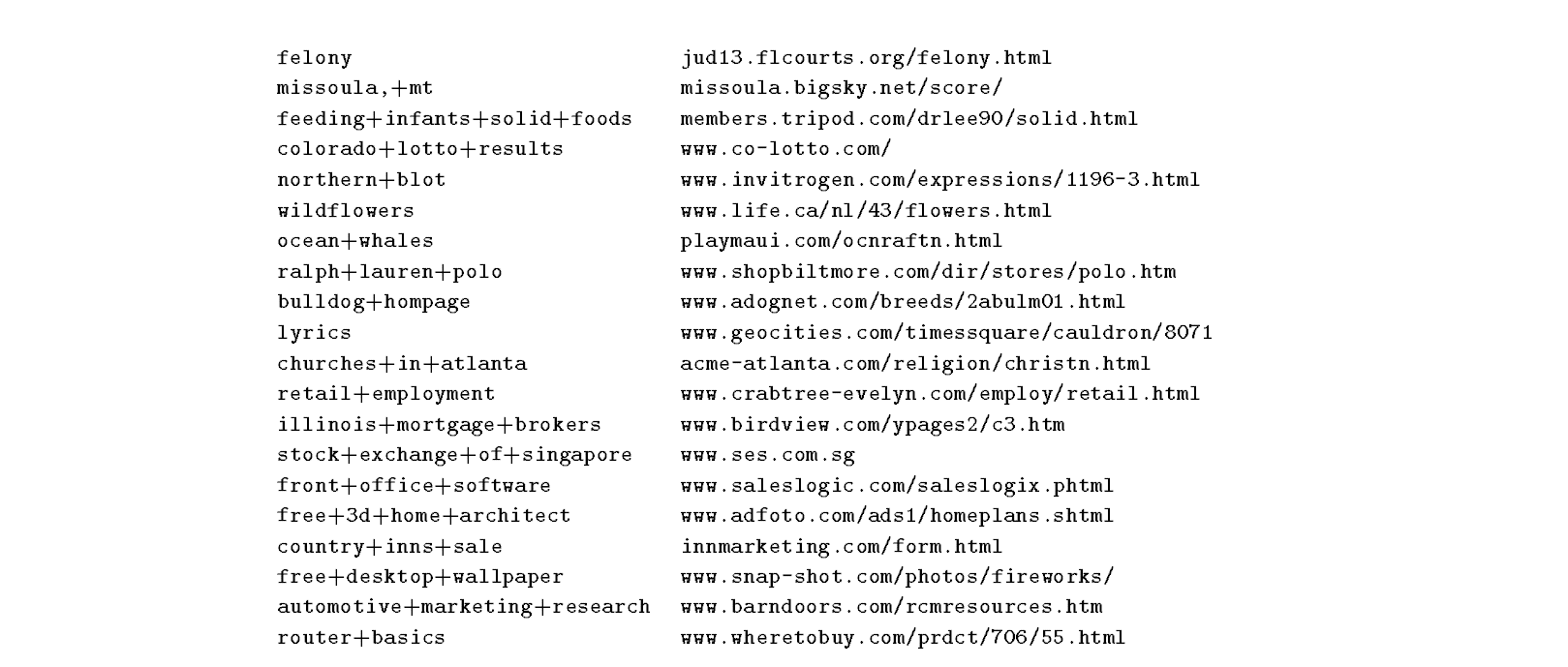
http协议允许商业搜索引擎记录关于用户的大量信息——发送请求的机器的名称和IP地址、机器上运行的web浏览器的类型、机器的屏幕分辨率,等等。这里,我们只对包含用户提交的查询的字符序列和用户从搜索引擎提供的选项中选择的URL感兴趣。表1列出了来自最近Lycos日志的点击记录(查询,URL)的一小段摘录。
表1:2000年2月某一天Lycos点击记录(用户查询和所选url)的一小段摘录。
算法设计
1.构造二部图 点击转跳二部图介绍
首先我们约定,用户查询词query为Q,Url则为U,构造出的图为G,二部图的query顶点W(白节点),Url顶点为B(黑节点),日志的数据集为C(数据集格式<query,url>)
- 从数据集C中获取一个独一无二的用户查询词query
- 从数据集C中获取一个独一无二的用户点击连接url
- 对每一个唯一的query,在二部图中创建一个W白节点
- 对每一个唯一的url,在二部图中创建一个B黑节点
- 如果<query,url>出现过,加给他们节点之间加边
2.节点间的相似度
为了对二部图进行聚合,需要计算每个顶点之间的相似度,引入公式
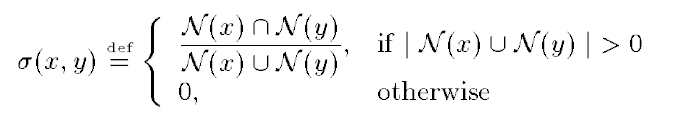
公式中σ(x,y)表示x和y顶点(黑和黑,白和白),N(x)代表顶点x和另一边顶点的总边数,N(y)代表顶点y和另一边顶点的总边数,所以公式的意思就是,两顶点重合的边和总共的边的比代表相似度
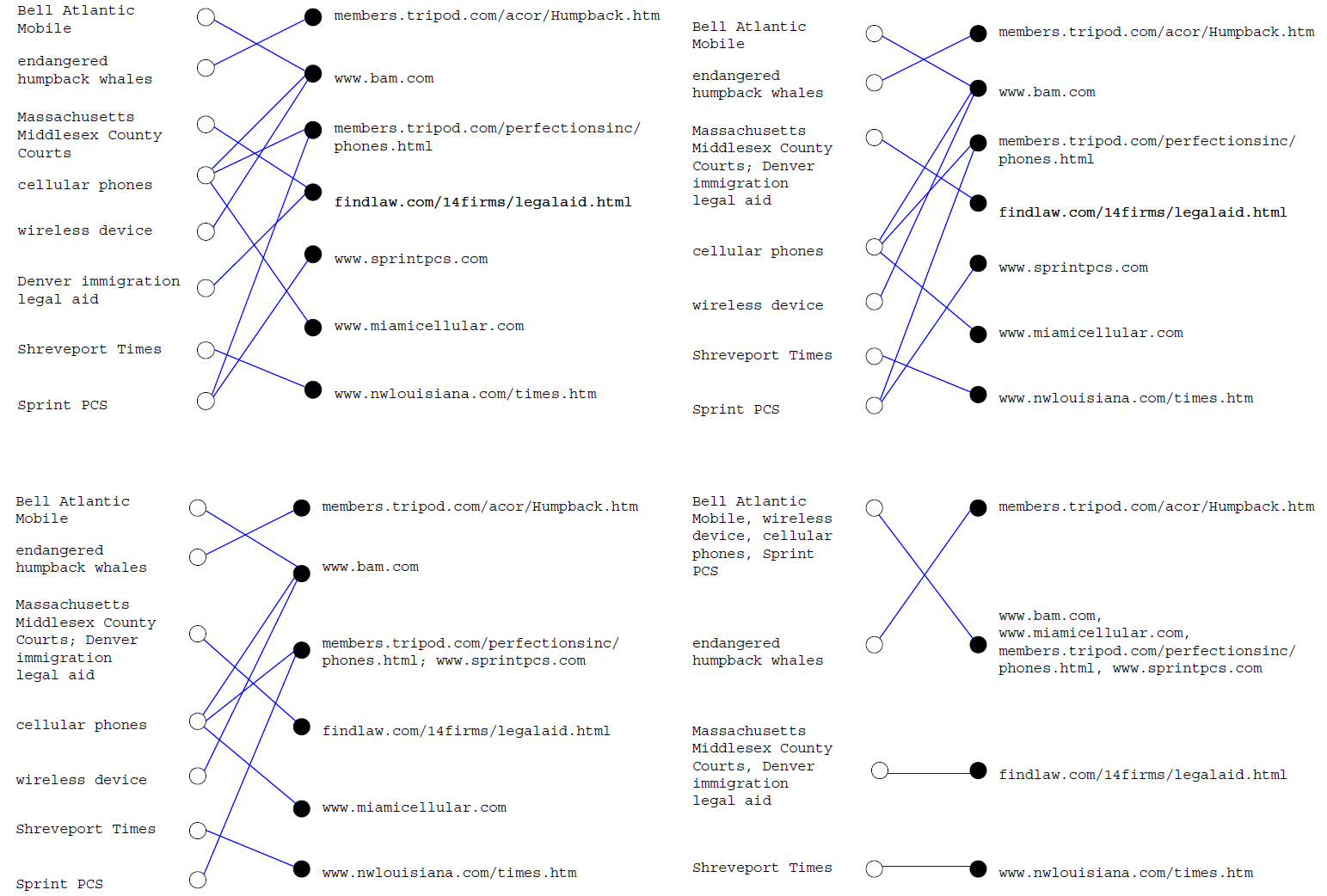
3.对二部图进行聚合
- 根据2中公式,对所以白顶点之间的相似度(查询词顶点)打分
- 把两个最相似的白顶点合并
- 根据2中公式,对所以黑顶点之间的相似度(Url顶点)打分
- 把两个最相似的黑顶点合并
- 迭代(重复前面步骤),直到一个条件
文中没有对停止条件详细规定,只是说到一个最相似的情况,我在下文会提供其他论文的解决办法
算法过程示意图
时间复杂度
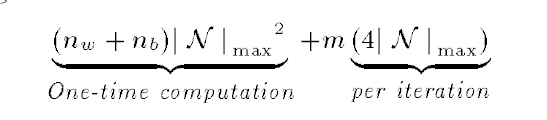
算法缺陷
在阅读其它文章,我发现有以下两个缺点
1.没有考虑噪声数据,即用户错误点击
对此问题 W ing Shun Chan 在论文《Query Log Containing Noisy Clickthroughs 》中,给出了优化的相似度计算公式

2.没有给出算法明确停止边界
如果计算的最大相似度度太低,会导致不相关的也被强行聚合,所以,我们通过设置一个阈值来解决
参考文献
[ 1] Doug Beeferman, Adam Berger. Agglomerative Clustering of a Search Engine Query Log[C], Proceedings of the sixth ACM S IGKDD interna2 tional con ference on knowledge discovery and data m ining, pp. 407 416, August 20~23, 2000, Boston, M assachusetts, United States.
[2] W ing Shun Chan, W ai Ting Leung, D ik Lun Lee. Clustering Search En2 gine Query Log Containing Noisy Clickthroughs [C], Proceedings ofthe 2004 International Symposium on App lications and the Internet( SAINTT04).
解读论文《Agglomerative clustering of a search engine query log》,以解决搜索推荐相关问题的更多相关文章
- Science论文"Clustering by fast search and find of density peaks"学习笔记
"Clustering by fast search and find of density peaks"是今年6月份在<Science>期刊上发表的的一篇论文,论文中 ...
- 微软的一篇ctr预估的论文:Web-Scale Bayesian Click-Through Rate Prediction for Sponsored Search Advertising in Microsoft’s Bing Search Engine。
周末看了一下这篇论文,觉得挺难的,后来想想是ICML的论文,也就明白为什么了. 先简单记录下来,以后会继续添加内容. 主要参考了论文Web-Scale Bayesian Click-Through R ...
- Science14年的聚类论文——Clustering by fast search and find of density peaks
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 这是一个比较新的聚类方法(文章中没看见作者对其取名,在这里我姑且称该方法为local density clu ...
- Clustering and Exploring Search Results using Timeline Constructions (paper2)
作者:Omar Alonso 会议:CIKM 2009 摘要: 截至目前(2009),通过提取文档中内嵌的时间信息来展现和聚类,这方面的工作并不多. 在这篇文章中,我们将提出一个“小插件”增添到现有的 ...
- [DataMining]WEEK1 - text-retrieval and search engine
What does a computer have to do in order to understand a natural language sentence? What is ambiguit ...
- [Search Engine] 搜索引擎分类和基础架构概述
大家一定不会多搜索引擎感到陌生,搜索引擎是互联网发展的最直接的产物,它可以帮助我们从海量的互联网资料中找到我们查询的内容,也是我们日常学习.工作和娱乐不可或缺的查询工具.之前本人也是经常使用Googl ...
- [CareerCup] 10.7 Simplified Search Engine 简单的搜索引擎
10.7 Imagine a web server for a simplified search engine. This system has 100 machines to respond to ...
- 开源搜索 Iveely Search Engine 0.6.0 发布 -- 黎明前的娇嫩
快两年了,Iveely Search Engine已经走过了5个版本的岁月,虽出生“贫寒”,没有任何开源基金会的支持,没有优秀的“干爹.干妈”,它凭着它的爱好者的支持,0.6.0终于破壳而出,7年前, ...
- [0.0]Analysis of Baidu search engine
Rencently, my two teammates and I is doing a project, a simplified Chinese search engine for childre ...
随机推荐
- JavaScript的取值小技巧之“中括号[]取值法”
一.简介 做下记录,今天看了一篇很有意思的文章,学到了这个取值的小技巧 正常的话我们一般都是用对象直接去'.'对应的属性名(也就是键值对的键)来获取对应的值 这里记录的是另一种取值方式,他是采用中括号 ...
- WzwJDBC 自定义工具类(获取连接,释放资源)
package wzwUtil;import java.io.IOException;import java.io.InputStream;import java.sql.*;import java. ...
- c源文件中为什么要包含自己对应的头文件
另一篇:.c文件和.h文件的关系 引言: 我们经常在c工程中发现,源文件中要包含自己的头文件.一直以来,都不知道为什么这样做.现在,我知道了. 以前的认知: 我认为,.c文件没有必要包含自己的.h文件 ...
- 2018 百度web前端面试
面试前 正式入职一年半左右,实习半年,勉强两年经验吧,然后很惊喜收到了百度的面试邀约,约得两点钟面试,然后本人一点钟就到了,通电话之后,面试官很热情,说正在吃饭吃完饭就去找我,让我去坐着等一会,然后一 ...
- H5进阶篇--实现微信摇一摇功能
在HTML5中,DeviceOrientation特性所提供的DeviceMotion事件封装了设备的运动传感器时间,通过改时间可以获取设备的运动状态.加速度等数据(另还有deviceOrientat ...
- Socket.io+Notification实现浏览器消息推送
前言 socket.io: 包含对websocket的封装,可实现服务端和客户端之前的通信.详情见官网(虽然是英文文档,但还是通俗易懂).Notification: Html5新特性,用于浏览器的桌面 ...
- Emscripten教程之代码可移植性与限制(一)
Emscripten教程之代码可移植性与限制(一) 翻译:云荒杯倾本文是Emscripten-WebAssembly专栏系列文章之一,更多文章请查看专栏.也可以去作者的博客阅读文章.欢迎加入Wasm和 ...
- 国际化相对时间格式化API:Intl.RelativeTimeFormat
原文:The Intl.RelativeTimeFormat API 作者:Mathias Bynens(@mathias) 现代 Web 应用程序通常使用"昨天","4 ...
- 玩别人玩剩下的:canvas大雪纷飞
canvas大雪纷飞 前言:正好业务触及到canvas,看完api顺手写个雪花效果,因为之前看到过很多次这个,主要看思路,想象力好的可以慢慢去创作属于自己的canvas效果 思路: 利用画圆arc() ...
- InputStream in = JdbcUtil.class.getClassLoader().getResourceAsStream("dbinfo.properties");
1.与普通程序不同的是,Java程序(class文件)并不是本地的可执行程序.当运行Java程序时,首先运行JVM(Java虚拟机),然后再把Java class加载到JVM里头运行,负责加载Java ...