解读论文《Agglomerative clustering of a search engine query log》,以解决搜索推荐相关问题
《Agglomerative clustering of a search engine query log》
论文作者:Doug Beeferman 本文将解读此篇论文,此论文利用搜索日志中的<query,url>类型点击日志,实现忽略目标url内容,基于搜索词条用户的点击数据,聚合相关搜索和连接的算法。(本解读文章个人辛苦之作,请勿随意转载 文章链接 https://www.cnblogs.com/jiaomaster/p/16271663.html)
背景
随着互联网规模的扩大和普及,现在有超过10亿个静态网页(作者所写的年份),一些商业搜索引擎每天处理数以千万计的查询对组织这些数据的自动方法的迫切需求已经发展。为大规模的非结构化数据集带来一定程度的秩序的一种策略是将相似的项分组在一起。本文介绍了一种技术,用于通过Internet搜索从用户事务集合中找到相关查询和相关url的集群。作者列举了一些常用的文档的聚类计算方法,如HAC,k-means,但是这些都基于文档内容,但作者提出了一种基于用户点击数据日志的方法。
点击数据介绍
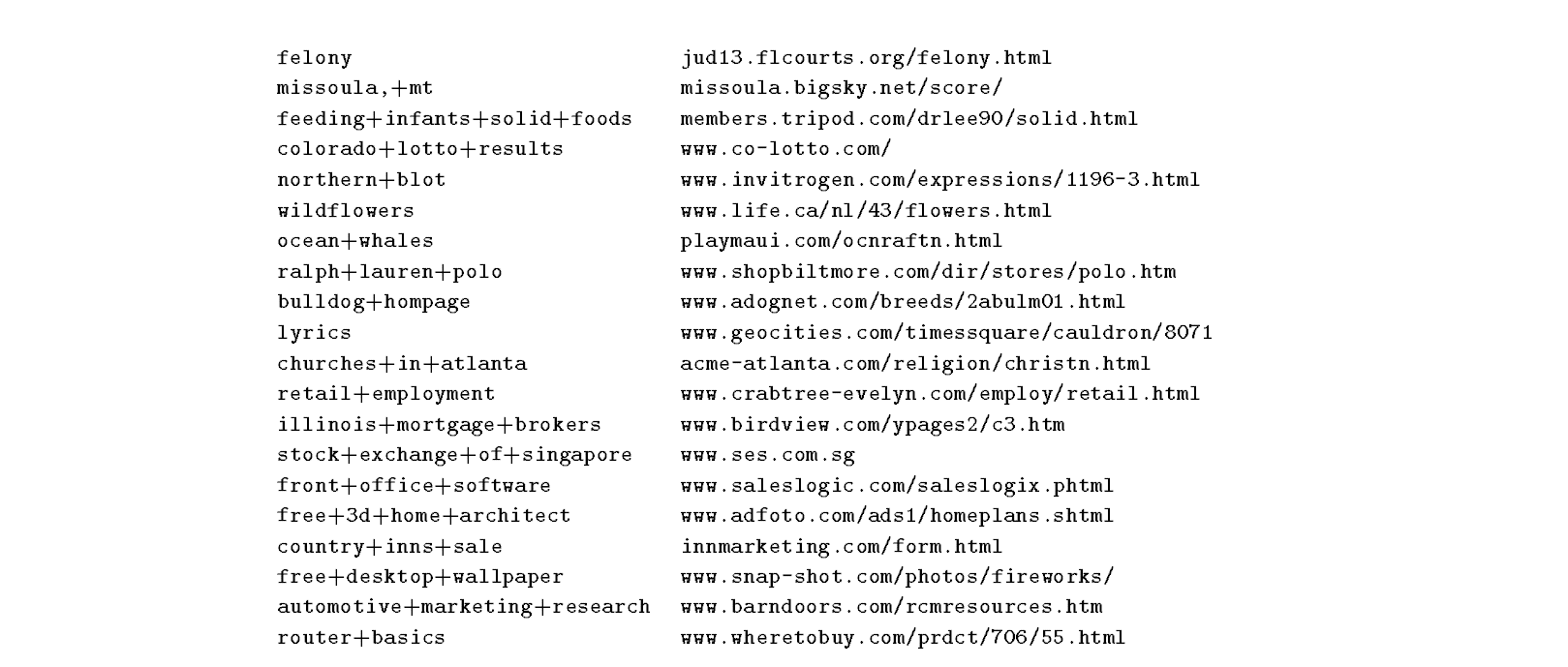
http协议允许商业搜索引擎记录关于用户的大量信息——发送请求的机器的名称和IP地址、机器上运行的web浏览器的类型、机器的屏幕分辨率,等等。这里,我们只对包含用户提交的查询的字符序列和用户从搜索引擎提供的选项中选择的URL感兴趣。表1列出了来自最近Lycos日志的点击记录(查询,URL)的一小段摘录。
表1:2000年2月某一天Lycos点击记录(用户查询和所选url)的一小段摘录。
算法设计
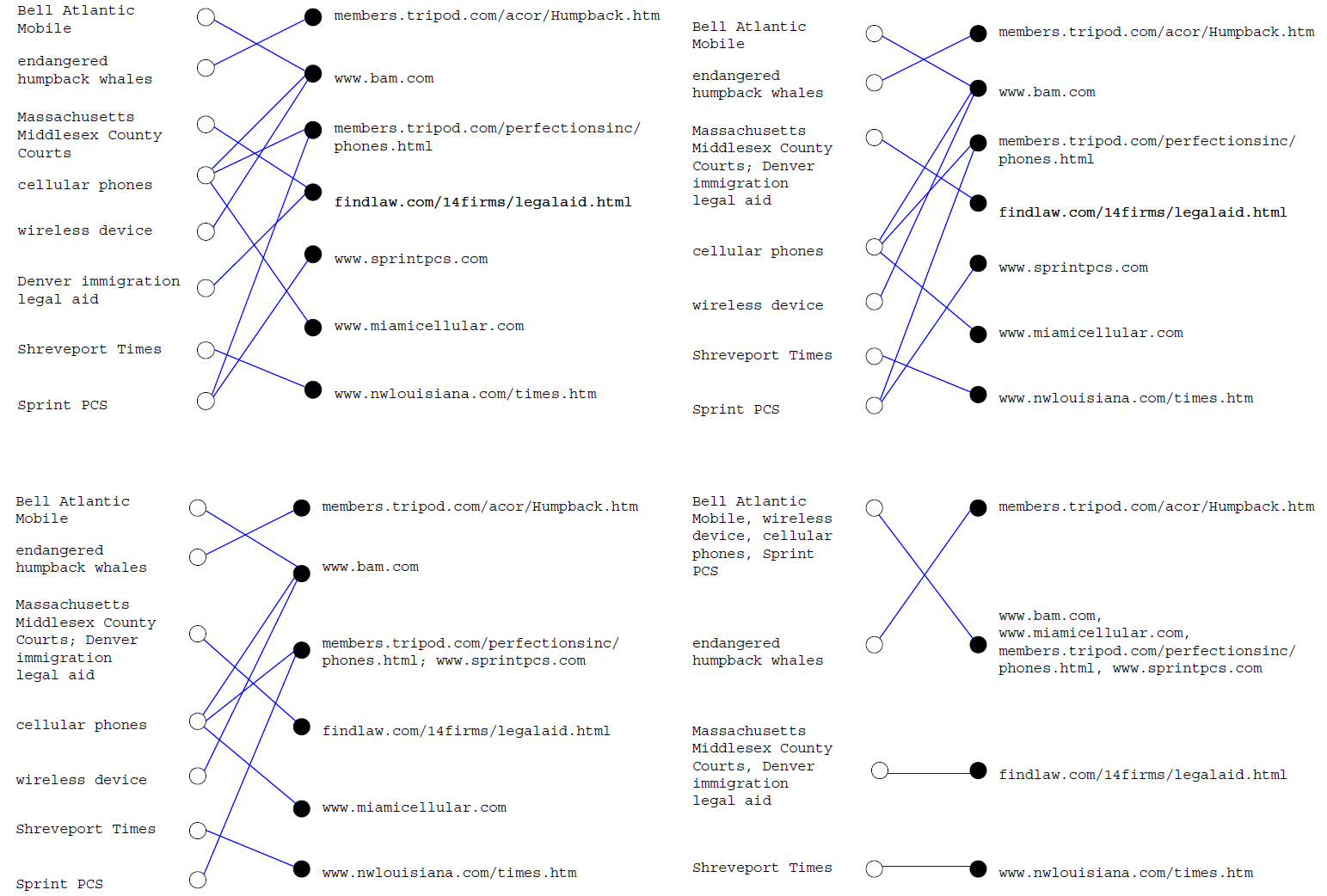
1.构造二部图 点击转跳二部图介绍
首先我们约定,用户查询词query为Q,Url则为U,构造出的图为G,二部图的query顶点W(白节点),Url顶点为B(黑节点),日志的数据集为C(数据集格式<query,url>)
- 从数据集C中获取一个独一无二的用户查询词query
- 从数据集C中获取一个独一无二的用户点击连接url
- 对每一个唯一的query,在二部图中创建一个W白节点
- 对每一个唯一的url,在二部图中创建一个B黑节点
- 如果<query,url>出现过,加给他们节点之间加边
2.节点间的相似度
为了对二部图进行聚合,需要计算每个顶点之间的相似度,引入公式
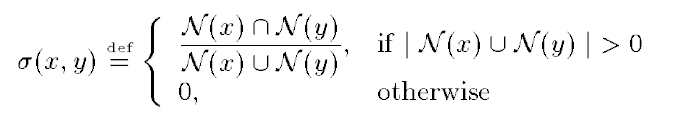
公式中σ(x,y)表示x和y顶点(黑和黑,白和白),N(x)代表顶点x和另一边顶点的总边数,N(y)代表顶点y和另一边顶点的总边数,所以公式的意思就是,两顶点重合的边和总共的边的比代表相似度
3.对二部图进行聚合
- 根据2中公式,对所以白顶点之间的相似度(查询词顶点)打分
- 把两个最相似的白顶点合并
- 根据2中公式,对所以黑顶点之间的相似度(Url顶点)打分
- 把两个最相似的黑顶点合并
- 迭代(重复前面步骤),直到一个条件
文中没有对停止条件详细规定,只是说到一个最相似的情况,我在下文会提供其他论文的解决办法
算法过程示意图
时间复杂度
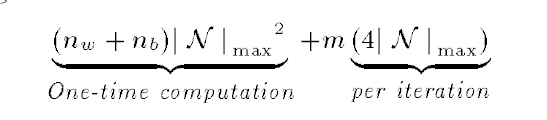
算法缺陷
在阅读其它文章,我发现有以下两个缺点
1.没有考虑噪声数据,即用户错误点击
对此问题 W ing Shun Chan 在论文《Query Log Containing Noisy Clickthroughs 》中,给出了优化的相似度计算公式

2.没有给出算法明确停止边界
如果计算的最大相似度度太低,会导致不相关的也被强行聚合,所以,我们通过设置一个阈值来解决
参考文献
[ 1] Doug Beeferman, Adam Berger. Agglomerative Clustering of a Search Engine Query Log[C], Proceedings of the sixth ACM S IGKDD interna2 tional con ference on knowledge discovery and data m ining, pp. 407 416, August 20~23, 2000, Boston, M assachusetts, United States.
[2] W ing Shun Chan, W ai Ting Leung, D ik Lun Lee. Clustering Search En2 gine Query Log Containing Noisy Clickthroughs [C], Proceedings ofthe 2004 International Symposium on App lications and the Internet( SAINTT04).
解读论文《Agglomerative clustering of a search engine query log》,以解决搜索推荐相关问题的更多相关文章
- Science论文"Clustering by fast search and find of density peaks"学习笔记
"Clustering by fast search and find of density peaks"是今年6月份在<Science>期刊上发表的的一篇论文,论文中 ...
- 微软的一篇ctr预估的论文:Web-Scale Bayesian Click-Through Rate Prediction for Sponsored Search Advertising in Microsoft’s Bing Search Engine。
周末看了一下这篇论文,觉得挺难的,后来想想是ICML的论文,也就明白为什么了. 先简单记录下来,以后会继续添加内容. 主要参考了论文Web-Scale Bayesian Click-Through R ...
- Science14年的聚类论文——Clustering by fast search and find of density peaks
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 这是一个比较新的聚类方法(文章中没看见作者对其取名,在这里我姑且称该方法为local density clu ...
- Clustering and Exploring Search Results using Timeline Constructions (paper2)
作者:Omar Alonso 会议:CIKM 2009 摘要: 截至目前(2009),通过提取文档中内嵌的时间信息来展现和聚类,这方面的工作并不多. 在这篇文章中,我们将提出一个“小插件”增添到现有的 ...
- [DataMining]WEEK1 - text-retrieval and search engine
What does a computer have to do in order to understand a natural language sentence? What is ambiguit ...
- [Search Engine] 搜索引擎分类和基础架构概述
大家一定不会多搜索引擎感到陌生,搜索引擎是互联网发展的最直接的产物,它可以帮助我们从海量的互联网资料中找到我们查询的内容,也是我们日常学习.工作和娱乐不可或缺的查询工具.之前本人也是经常使用Googl ...
- [CareerCup] 10.7 Simplified Search Engine 简单的搜索引擎
10.7 Imagine a web server for a simplified search engine. This system has 100 machines to respond to ...
- 开源搜索 Iveely Search Engine 0.6.0 发布 -- 黎明前的娇嫩
快两年了,Iveely Search Engine已经走过了5个版本的岁月,虽出生“贫寒”,没有任何开源基金会的支持,没有优秀的“干爹.干妈”,它凭着它的爱好者的支持,0.6.0终于破壳而出,7年前, ...
- [0.0]Analysis of Baidu search engine
Rencently, my two teammates and I is doing a project, a simplified Chinese search engine for childre ...
随机推荐
- Spring源码分析笔记--事务管理
核心类 InfrastructureAdvisorAutoProxyCreator 本质是一个后置处理器,和AOP的后置处理器类似,但比AOP的使用级别低.当开启AOP代理模式后,优先使用AOP的后置 ...
- 在小程序Canvas中使用measureText
有时候我们在使用Canvas绘制一段文本时,会需要通过measureText()方法获取文本的宽度,例如: 创建canvas标签 <canvas id="canvas"> ...
- Anaconda安装tensorflow和keras(gpu版,超详细)
本人配置:window10+GTX 1650+tensorflow-gpu 1.14+keras-gpu 2.2.5+python 3.6,亲测可行 一.Anaconda安装 直接到清华镜像网站下载( ...
- Java中if else条件判断语句的执行顺序
学习目标: 掌握 if else 条件判断的使用 学习内容: 1.if语法 if(boolean表达式) { 语句体; } if后面的{}表示一个整体-代码块,称之为语句体,当boolean表达式为t ...
- Python使用函数实现杨辉三角
运行效果: 可在函数中指定阶层数,输出对应的杨辉三角 源代码如下: 1 # -*-coding:utf-8 -*- 2 ''' 3 chapter4_do.py 4 函数yanghui(n)用于输出n ...
- 麒麟系统开发笔记(三):从Qt源码编译安装之编译安装Qt5.12
前言 上一篇,是使用Qt提供的安装包安装的,有些场景需要使用到从源码编译的Qt,所以本篇如何在银河麒麟系统V4上编译Qt5.12源码. 银河麒麟V4版本 系统版本: Qt源码下载 ...
- 时间盲注——AS别名让盲注不盲
用处 页面存在时间盲注,注入成功了,你啥也看不到. 这只是为了能够查看到注入后的结果 网站部分源代码 <?php $conn = mysqli_("127.0.0.1",&q ...
- C++---初识C++
C和C++的关系 C语言是结构化和模块化的语言, 面向过程. C++是在C语言的基础上, 增加了面向对象的机制, 并对C语言的功能进行了扩充. 变量的定义可以出现在程序中的任何行 提供了标准输入输出流 ...
- 虚拟机VMware的安装与Xshell的应用
先安装VMware 1.安装就按照提示一点点安装就行了 配置网络 打开VMware 这里的IOS映像文件在https://developer.aliyun.com/mirror/里下载 这里用方向键往 ...
- 6.Docker容器底层实现了解与安全机制
原文地址: 点击直达 0x00 底层实现 我们以 Docker 基础架构来探究Docke底层的核心技术,简单的包括: Linux 上的命名空间(Namespaces) 控制组(Control grou ...