KMP算法学习以及小结(好马不吃回头草系列)
首先请允许我对KMP算法的三位创始人Knuth,Morris,Pratt致敬,这三位优秀的算法科学家发明的这种匹配模式可以大大避免重复遍历的情况,从而使得字符串的匹配的速度更快,效率更高。
首先引入对kmp算法的引例:
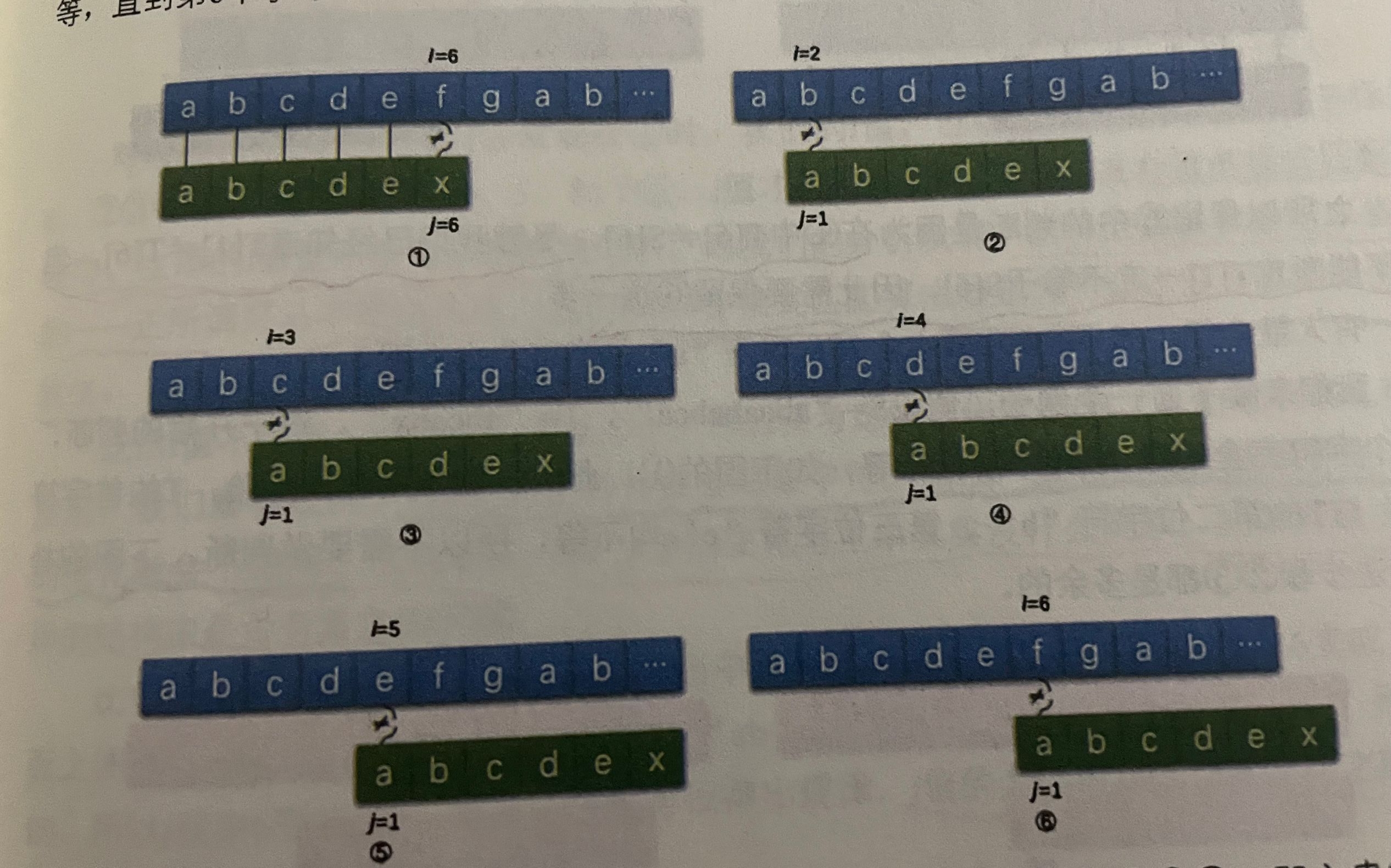
如果按照暴力算法来看,这6步一步也少不了,是很麻烦的;
但是对于要匹配的子串来讲,子串T的首字母与后面的任何一个字母都不想等,拿图1来看首字母'a’与主串S的第2位到第5位的任意一个字母都是不相通的
换言之:图2345的步骤都是多余的
如果知道T子串的首字符‘a'与T以后的字符均不相等的话,也就是说T的首字符'a’与s串的第二位不需要判断也是可以知道相不相同了;
在举个例子来看的话,那如果知道首字符T与子串的后面字符都不相等的情况下,s串与T串的判断情况也就知晓了
所以说保留1,6两步即可
但是为什么保留6呢?
原因也很简单:
你虽然知道T1!=T6,但是也不能严格保证T1!=S6,也就是说S6和T6可能不相等
还有一种情况是子串后面的字符出现重复,比如:abababa此类的字符串
模拟一下:
我们有主串S="ABCABABCA"(自动看成小写,手滑了),子串T=“abcabx"

图1,子串T的首字符与第二,第三字符均不相等,,所以不用判断,跳过23即可
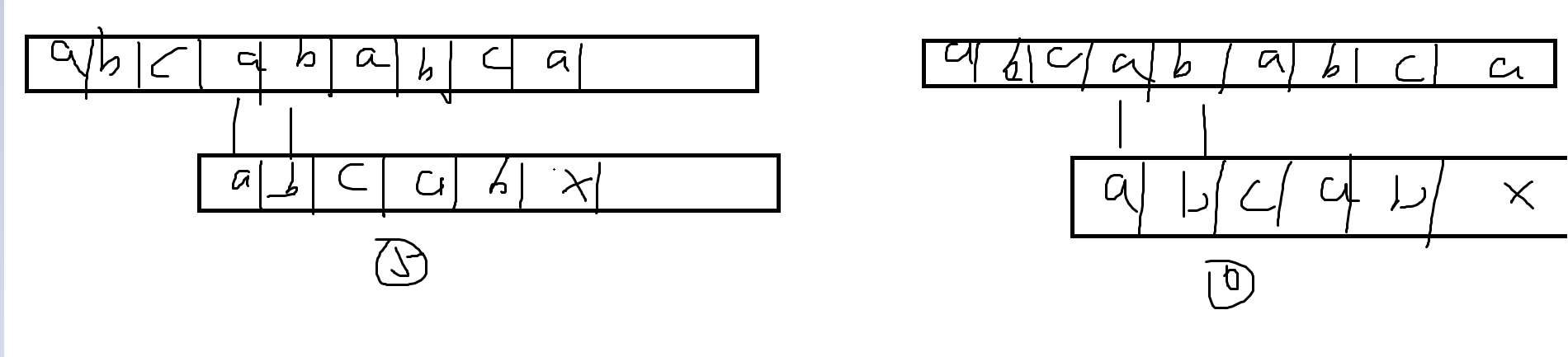
T子串的首位和S第四位相等,第二位和S第五位相等,但很遗憾的是,这一步其实在开始1的时已经判断过了,于是呼首位和第四位,第二位和第五位也是不需要判断了,所以说4,5这两部也是可以省略的
可以看出,对于子串中国有与首字符相等的字符,完完全全是可以省略一些不必要的判断的
对比一下的话,在开始的时候,i的下标是6,经过2345步,i的值相应的变成了2,3,4,5一直到了第6步,i的值又重新变回了6,也就是说,i的值是通过下标不断回溯得到的,而这种回溯通过上面2345的推断,是可以省略的,类似于好马不吃回头草
那这样的话,i的值可以不回溯,当然也不可以减小,只能往前走,那就只能在j上开刀了;
上面我们说到了关于子串T中重复元素的问题,如果发现有相同元素,j的值就会不一样,也就是说j的值是和子串T重复元素个数的问题是相关的
一句话来说的话:j的大小是由当前T子串的前后缀的相似度决定的;
什么是前后缀,很简单:
"前缀"指除了最后一个字符以外,字符串的所有头部组合;
"后缀"指除了第一个字符以外,字符串的所有尾部组合。
举个例子来讲”
abcdab;
ta的前缀集合是(a,ab,abc,abcd,abcda)
后缀集合是(b,ab,dab,cdab,bcdab)
再来判断一个吧:abcabfabcab的最长前后缀是什么,长度多少?
很好写:abcab,5
介绍完前后缀,我们来正式引入kmp
在我们正式查找字符串之前,需要对子串做一个前后缀分析,来提高查找速度:
我们可以定义一个int 类型的数组next[]来记录各个位置j的变化情况,next的长度就是T串的长度:
 下面我们来展开一下对于next数组的求法:
下面我们来展开一下对于next数组的求法:
其实对于next数组,有一套简单求法:

设一个子串T=“ababaaa”
首先next[0]=0;
当i=1的时候是b那,没有前后缀相同的元素,next[1]=0;
当i=2的时候在a,有共同元素a,next[2]=0;
.............
一直到i=6在a,next[6]=1;


得到的序列是0012311
这时候我们将得到的序列最后一位舍弃,其余的全部往右推进一位,就是用前一位覆盖后一位,第一位用-1补齐,得到的新序列是
-1,0,0,1,2,3,1,在将得到的新序列全部加1,
变成0,1,1,2,3,4,2
就是求得的next的数组,
这种方法比教科书上板式求法方便好记多了,适合考场和比赛时候对于next数组的求解,既高效又快速,正确率还高
主要的原理还是利用了前后缀的问题
我们再来拿算法本身做做文章:
在朴素方法中,每次新的匹配都需要对比 S和 T的全部 m个字符,这实际上做了重复操作。例如第一轮匹配 S 的前3个字符 “aaa”和 T的“aab”,第二轮从 S的第2个字符 ‘a’开始,与和T的第一个字符 a’比较,这其实不必要,因为在第一轮比较时已经检查过这两个字符,知道它们相同。如果能记住每次的比较,用于指导下一次比较,使得 S的 i指针不用回溯,就能提高效率。
如何让i不回溯?分析两种情况:
(1) P在失配点之前的每个字符都不同
例如S =“abcabcd",P=“abcd",第一次匹配的失配点是i=3,j = 3。失配点之前的P的每个字符都不同,P[0] ≠
P[1]≠P[2];而失配点之前的S与P相同,即P[0]= S[0]、P[1]= S[1]、P[2]= S[2]。下一步如果按朴素方法,j要回到位置
0, i要回到1,去比较P[0]和S[1]。 但的回溯是不必要的。由P[0]≠P[1]、P[1]= S[1]推出P[0]≠S[1],所以没有必要回到位置
1。同理,P[0]≠S[2], 也没有必要回溯到位置2。所以i不用回溯, 继续从i= 3、j = 0开始下一轮的匹配。

当 p滑动到左图位置时, i和 j所处的位置是失配点,S与 P的阴影部分相同,且阴影内部的P的字符都不同。下一步直接把 P滑到 S的 i 位置,此时i不变、 j回到0,然后开始下一轮的匹配。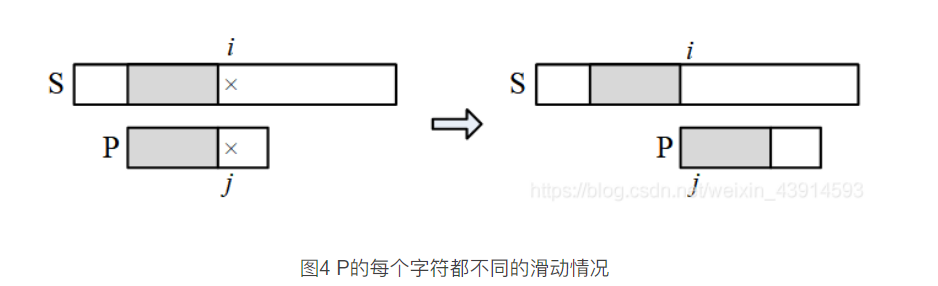
(2) P在失配点之前的字符有部分相同
再细分两种情况:
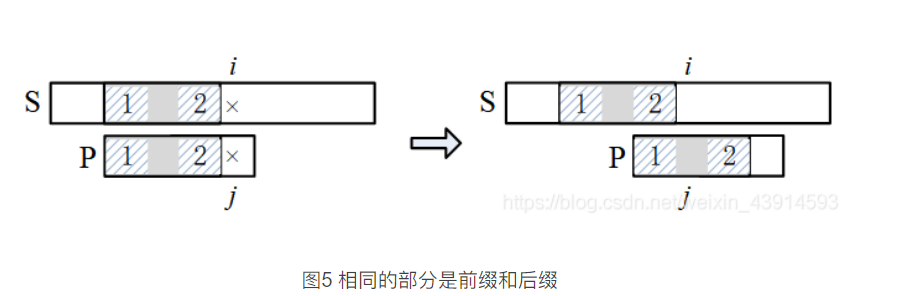
1)相同的部分是前缀(位于P的最前面)和后缀(位于j的前面)。
这里给出前缀和后缀的定义:字符串A和B,若存在A= BC,其中C是任意的非空字符串,称B为A的前缀;同理可定义后缀,
若存在A= CB,C是任意非空字符串,称B为A的后缀。从定义可知,一个字符串的前缀和后缀不包括自己。
当P滑动到下面左图位置时,i和j所处的位置是失配点,j之前的部分与S匹配,且子串1 (前缀) 和子串2 (后缀)相同,设子串长
度为L。下一步把P滑到右图位置,让P的子串1和S的子串2对齐,此时坏变、j = L,然后开始下一轮的匹配。注意,前缀和后缀可以
部分重合。
2)相同部分不是前缀或后缀。
下面左图,P滑动到失配点i和j,前面的阴影部分是匹配的,且子串1和2相同,但是1不是前缀(或者2不是后缀),这种情况
与“(1)失配点之前的P的每个字符都不同”类似,下一 步滑动到右图位置,即坏变, j回溯到0。

通过.上面的分析可知,不回溯i完全可行。KMP算法的关键在于模式P的前缀和后缀,计算每个P[j]的前缀、后缀,记录在N ext[]
数组(也有写成shift或者fail的) 中,Next[j]的值等于P[0] - P[j - 1]这部分子串的前缀集合和后缀集合的交集的最长元素的长
度。把这个最长元素称为“最长公共前后缀”。
并且对于求解next数组的算法,可以直接或者间接去求nextval数组的算法:
假设已经计算出了Next[i],它对应P[0] - P[i - 1]这部分子串的后缀和前缀,见下面图8(1)所示。后缀的最后- -个字符是P[i -
1]。阴影部分w是最长交集,交集w的长度为Next[i],这个交集必须包括后缀的最后-个字符P[i - 1]和前缀的第-个字符P[0]。前缀
中阴影的最后一个字符是P[j],j = Next[i]- 1。
图8(2)推广到求Next[i + 1],它对应P[0] P[i]的后缀和前缀。此时后缀的最后- -个字符是P[i], 与这个字符相对应,把前缀的j也
往后移一个字符, j = Next[i]。判断两种情况:
(1)若P[i]= P[j],则新的交集等于“阴影w + P[i]", 交集的长度Next[i + 1] = Next[i] + 1。如图(2)所示。
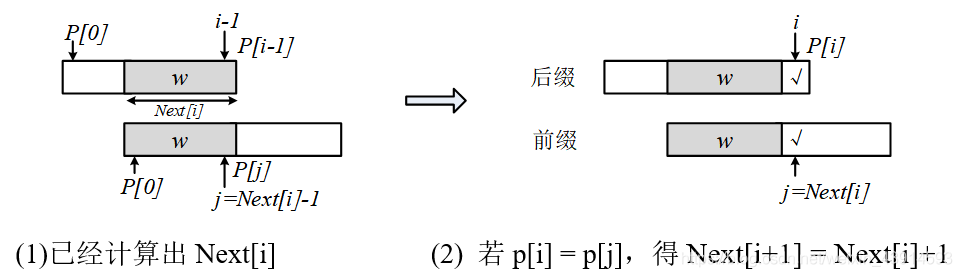
(2) 若P[i]≠P[j],说明后缀的“阴影w + P[]"与前缀的“阴影w + P[j]”不匹配, 只能缩小范围找新的交集。把前缀往后滑动,
也就是通过减小j来缩小前缀的范围,直到找到一个匹配的P[i]= P[j]为止。如何减小j?只能在w上继续找最大交集,这个新的最大交
集是Next[j],所以更新j = Next[j]。下图(2)画出了 完整的子串P[0] P[i],最后的字符P[i]和P[j]不等。斜线阴影0是w上的最大
交集,下一步判断:若P[i]= P[jl],则Next[i + 1]等于v的长度加1,即Next[j"] +1;若P[i≠P[j"], 继续更新j’。

一直重复这样的操作来延展i,直到求遍所以的next数组即可
下面以hdu 2087给出模板代码:
1 #include<bits/stdc++.h>
2 using namespace std;
3 const int N = 1005;
4 char str[N], pattern[N];
5 int Next[N];
6 int cnt;
7 void getNext(char *p, int plen){ //计算Next[1]~Next[plen]
8 Next[0]=0; Next[1]=0;
9 for(int i=1; i < plen; i++){ //把i的增加看成后缀的逐步扩展
10 int j = Next[i]; //j的后移:j指向前缀阴影w的后一个字符
11 while(j && p[i] != p[j]) //阴影的后一个字符不相同
12 j = Next[j]; //更新j
13 if(p[i]==p[j]) Next[i+1] = j+1;
14 else Next[i+1] = 0;
15 }
16 }
17 int kmp(char *s, char *p) { //在s中找p
18 int last = -1;
19 int slen=strlen(s), plen=strlen(p);
20 getNext(p, plen); //预计算Next[]数组
21 int j=0;
22 for(int i=0; i<slen; i++) { //匹配S和P的每个字符
23 while(j && s[i]!=p[j]) //失配了。注意j==0是情况(1)
24 j=Next[j]; //j滑动到Next[j]位置
25 if(s[i]==p[j]) j++; //当前位置的字符匹配,继续
26 if(j == plen) { //j到了P的末尾,找到了一个匹配
27 //这个匹配,在S中的起点是i+1-plen,末尾是i。如有需要可以打印:
28 // printf("at location=%d, %s\n", i+1-plen,&s[i+1-plen]);
29 //-------------------30--33行是本题相关
30 if( i-last >= plen) { //判断新的匹配和上一个匹配是否能分开
31 cnt++;
32 last=i; //last指向上一次匹配的末尾位置
33 }
34 //-------------------
35 }
36 }
37 }
38 int main(){
39 while(~scanf("%s", str)){ //读串
40 if(str[0] == '#') break;
41 scanf("%s", pattern); //读模式串
42 cnt = 0;
43 kmp(str, pattern);
44 printf("%d\n", cnt);
45 }
46 return 0;
47 }
练手题目:https://acm.sdut.edu.cn/onlinejudge3/problems/2772
1 #include<bits/stdc++.h>
2
3 using namespace std;
4 #define maxn 1000010
5
6 char s[maxn], t[maxn];
7 int Next[maxn];
8
9 void get_next()
10 {
11 int i = 0, j = -1;
12 Next[0] = -1;
13 int tlen = strlen(t);
14 while(i < tlen)
15 {
16 if(j == -1 || t[i] == t[j])
17 {
18 i++;
19 j++;
20 Next[i] = j;
21 }
22 else
23 j = Next[j];
24 }
25 }
26
27 int kmp()
28 {
29 int i = 0, j = 0;
30 int tlen = strlen(t);
31 int slen = strlen(s);
32 while(i < slen && j < tlen)
33 {
34 if(j == -1 || s[i] == t[j])
35 {
36 i++;
37 j++;
38 }
39 else
40 j = Next[j];
41 }
42 if(j == tlen)
43 return i - j + 1;
44 else
45 return -1;
46 }
47 int main()
48 {
49 while(~scanf("%s",s))
50 {
51 scanf("%s",t);
52 get_next();
53 printf("%d\n", kmp());
54 }
55 return 0;
56 }
练手题目:https://acm.sdut.edu.cn/onlinejudge3/problems/2125
和上面差不多
1 #include<bits/stdc++.h>
2
3 using namespace std;
4 #define maxn 1000010
5
6 char s[maxn], t[maxn];
7 int Next[maxn];
8
9 void get_next()
10 {
11 int i = 0, j = -1;
12 Next[0] = -1;
13 int tlen = strlen(t);
14 while(i < tlen)
15 {
16 if(j == -1 || t[i] == t[j])
17 {
18 i++;
19 j++;
20 Next[i] = j;
21 }
22 else
23 j = Next[j];
24 }
25 }
26
27 int kmp()
28 {
29 int i = 0, j = 0;
30 int tlen = strlen(t);
31 int slen = strlen(s);
32 while(i < slen && j < tlen)
33 {
34 if(j == -1 || s[i] == t[j])
35 {
36 i++;
37 j++;
38 }
39 else
40 j = Next[j];
41 }
42 if(j == tlen)
43 printf("YES\n");
44 else
45 printf("NO\n");
46 return 0;
47 }
48 int main()
49 {
50 while(~scanf("%s",s))
51 {
52 scanf("%s",t);
53 get_next();
54 kmp();
55 }
56 return 0;
57 }
当然,kmp的应用还不止这些,还有升级版的kmp----AC自动机,还待我这个初级ACMer去探索挑战;
再次表达对于Knuth,Morris,Pratt三人的致敬,能发明出这样巧妙而实用的算法是真的天才中的天才
KMP算法学习以及小结(好马不吃回头草系列)的更多相关文章
- 字符串匹配算法——KMP算法学习
KMP算法是用来解决字符串的匹配问题的,即在字符串S中寻找字符串P.形式定义:假设存在长度为n的字符数组S[0...n-1],长度为m的字符数组P[0...m-1],是否存在i,使得SiSi+1... ...
- KMP算法学习(详解)
kmp算法又称“看毛片”算法,是一个效率非常高的字符串匹配算法.不过由于其难以理解,所以在很长的一段时间内一直没有搞懂.虽然网上有很多资料,但是鲜见好的博客能简单明了地将其讲清楚.在此,综合网上比较好 ...
- KMP算法学习
kmp算法完成的任务是:给定两个字符串O和f,长度分别为n和m,判断f是否在O中出现,如果出现则返回出现的位置.常规方法是遍历a的每一个位置,然后从该位置开始和b进行匹配,但是这种方法的复杂度是O(n ...
- KMP 算法 学习 整理
我自己整理的KMP算法的PDF文件:http://pan.baidu.com/s/1o8yKIi2提取密码:8291 别的就不多说啥了,感谢来自海子 博客园的 资料--
- 字符串匹配的BF算法和KMP算法学习
引言:关于字符串 字符串(string):是由0或多个字符组成的有限序列.一般写作`s = "123456..."`.s这里是主串,其中的一部分就是子串. 其实,对于字符串大小关系 ...
- kmp算法学习 与 传参试验(常回来看看)
之前在codeforces上做了一道类似KMP的题目,但由于之前没有好好掌握,现在又基本忘记,并没能解答.下面是对KMP算法的一点小总结. 首先KMP算法的核心是纸在匹配过程中,利用模式串的前后缀来加 ...
- KMP 算法学习
KMP算法是用来做字符串匹配的.关于字符串匹配,最简单最容易想到的方法是暴利查找,使用双重for循环处理. 该方法的时间复杂度为O((n-m+1)*m) (n为目标串T长度,m为模式串P长度, 从T中 ...
- KMP算法 学习例题 POJ 3461Oulipo
Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 37971 Accepted: 15286 Description The ...
- KMP算法 Next数组详解
题面 题目描述 如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置. 为了减少骗分的情况,接下来还要输出子串的前缀数组next.如果你不知道这是什么意思也不要问,去百 ...
随机推荐
- 13_奈奎斯特稳定性判据_Nyquist Stability Criterion_Part 1
A曲线内有4个极点两个零点,则B曲线绕(0,0)逆时针两圈 A曲线是nyqyict contour中的曲线,P是A曲线内的()极点个数,Z是()极点个数,N是曲线B逆时针围绕(-1,0)的圈数 没过( ...
- ios audio不能够正常播放
ios中audio不能直接通过audio.play()播放,需要用户在click事件或者touch事件中执行audio.play()才能播放. ajax回调中audio.play()音乐不能正常播放. ...
- 基于融云的IM通讯
一.业务场景 项目的发展需要吧原来自己的写的通讯换为第三方的,多家对比后选择了融云IM通讯,项目要实现的功能这要是单聊.群聊.聊天室.发送的内容为文字.图片.文件.语音通话与视频通话.听起来挺复杂的我 ...
- 网络安全—xss
1.xss的攻击原理 需要了解 Http cookie ajax,Xss(cross-site scripting)攻击指的是攻击者往Web页面里插入恶意html标签或者javascript代码.比如 ...
- Android 预置APK
1. 预置apk,使其不可卸载 第一步: 在 "/vendor/huawei/packages/apps" 目录下创建一个对应名称的文件夹. 第二步: 将 ...
- Shiro 安全框架详解一(概念+登录案例实现)
shiro 安全框架详细教程 总结内容 一.RBAC 的概念 二.两种常用的权限管理框架 1. Apache Shiro 2. Spring Security 3. Shiro 和 Spring Se ...
- Exchange 2013 中 NDR 常见的失败返回状态代码
增强状态代码 描述 可能的原因 其他信息 4.3.1 Insufficient system resources 发生内存不足错误.资源问题(例如磁盘已满)可能导致该问题.您可能会收到内存不足错误,而 ...
- uni-app中 未收藏和已收藏功能展示
效果图如下: 未收藏: 已收藏: 代码实现: 1 <view class="jichu"> 2 <view class="name">x ...
- pip导出项目依赖包名称及版本,再安装命令
A导出依赖 pip freeze >requirements.txt B导入安装依赖 pip install -r requirements.txt 使用下面的命令安装依赖能自动跳过安装错误的依 ...
- 前端框架小实验-在umi框架中以worker线程方式使用SQL.js的wasm
总述:在Win7环境下配置umijs框架,在框架中用worker线程方式使用SQL.js的wasm,在浏览器端实现数据的增删改查以及数据库导出导入. 一.安装node.js 1.Win7系统只支持no ...