记一次学习kibaba踩过的坑(Windows环境)
下载地址
ElasticSearch:https://www.elastic.co/cn/downloads/elasticsearch
Logstash:https://www.elastic.co/cn/downloads/logstash
Kibana:https://www.elastic.co/cn/downloads/kibana
安装Kibana的过程中遇到这样的问题

网上搜了好多帖子,如下

但是问题都没有解决
最终安装了head插件
1.下载head
https://github.com/mobz/elasticsearch-head
2.下载安装node
http://nodejs.cn/download/
3.编译head
进入E:\java\ELK\elasticsearch-head目录 执行npm install 命令npm install -g cnpm --registry=https://registry.npm.taobao.org
再执行 cnpm i 命令
4.执行成功之后启动head
npm run start
5.检验
http://localhost:9100/
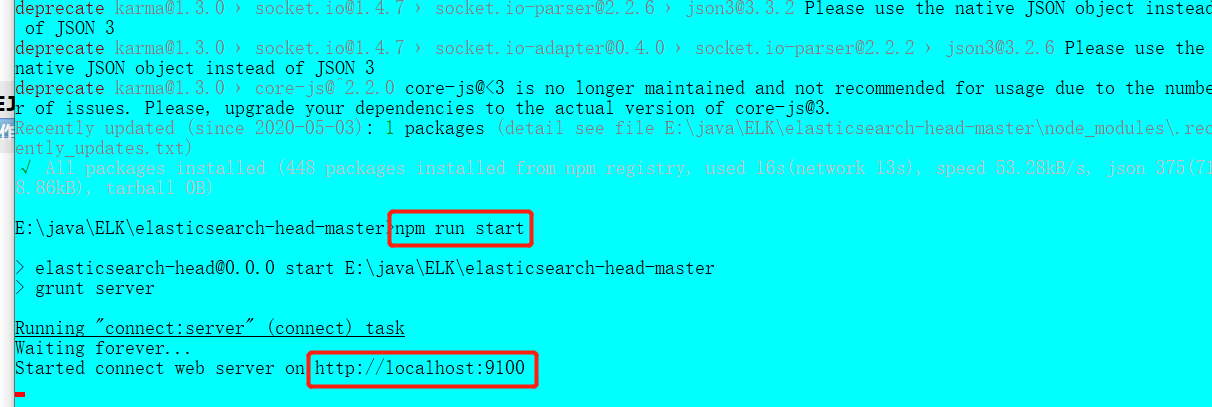
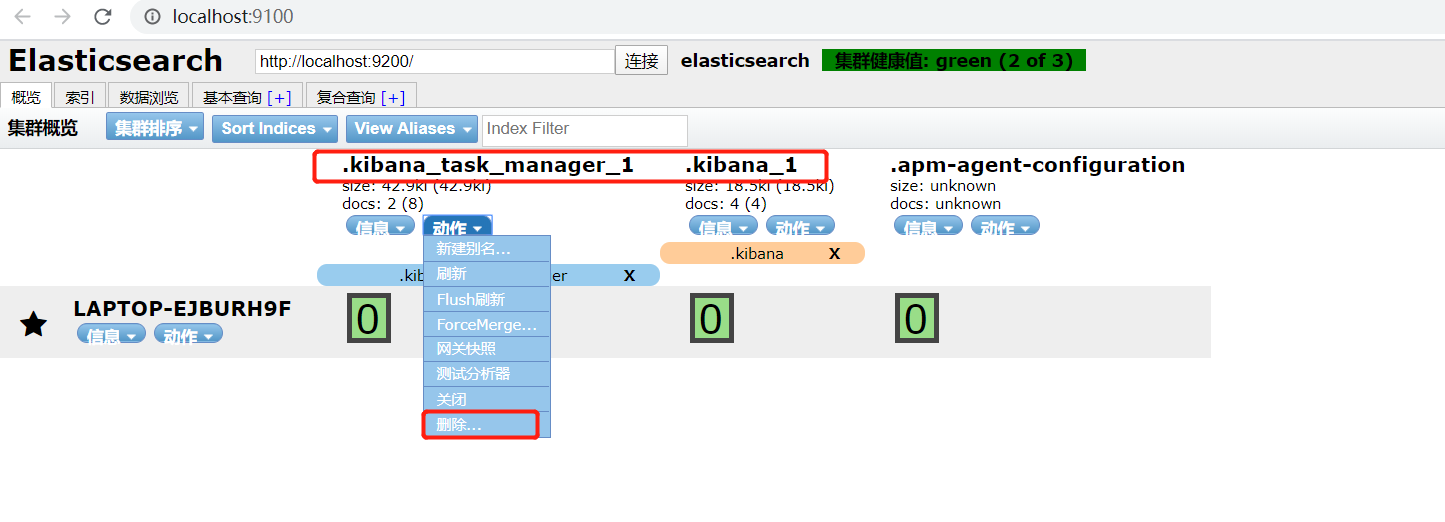
6.将这两个索引删除,重启Kibana就OK了

搭建elsticsearch集群 报错with the same id but is a different node instance解决办法
][o.e.c.c.JoinHelper ] [slave1] failed to join {master}{6AlOPeB3R4yYI4D6cCU7aw}{nr4lP8fLT6K0RoBJ7LCoJA}{192.222.1.222}{192.222.1.222:9300}{dilm}{ml.machine_memory=21370114048, ml.max_open_jobs=20, xpack.installed=true} with JoinRequest{sourceNode={slave1}{6AlOPeB3R4yYI4D6cCU7aw}{SAuV5W3QRRai8nlhxOVgOQ}{192.222.1.222}{192.222.1.222:9301}{dil}{ml.machine_memory=21370114048, xpack.installed=true, ml.max_open_jobs=20}, optionalJoin=Optional[Join{term=22, lastAcceptedTerm=17, lastAcceptedVersion=139, sourceNode={slave1}{6AlOPeB3R4yYI4D6cCU7aw}{SAuV5W3QRRai8nlhxOVgOQ}{192.222.1.222}{192.222.1.222:9301}{dil}{ml.machine_memory=21370114048, xpack.installed=true, ml.max_open_jobs=20}, targetNode={master}{6AlOPeB3R4yYI4D6cCU7aw}{nr4lP8fLT6K0RoBJ7LCoJA}{192.222.1.222}{192.222.1.222:9300}{dilm}{ml.machine_memory=21370114048, ml.max_open_jobs=20, xpack.installed=true}}]}
org.elasticsearch.transport.RemoteTransportException: [master][192.222.1.222:9300][internal:cluster/coordination/join]
Caused by: java.lang.IllegalArgumentException: can't add node {slave1}{6AlOPeB3R4yYI4D6cCU7aw}{SAuV5W3QRRai8nlhxOVgOQ}{192.222.1.222}{192.222.1.222:9301}{dil}{ml.machine_memory=21370114048, ml.max_open_jobs=20, xpack.installed=true}, found existing node {master}{6AlOPeB3R4yYI4D6cCU7aw}{nr4lP8fLT6K0RoBJ7LCoJA}{192.222.1.222}{192.222.1.222:9300}{dilm}{ml.machine_memory=21370114048, xpack.installed=true, ml.max_open_jobs=20} with the same id but is a different node instance
at org.elasticsearch.cluster.node.DiscoveryNodes$Builder.add(DiscoveryNodes.java:612) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.coordination.JoinTaskExecutor.execute(JoinTaskExecutor.java:147) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.coordination.JoinHelper$1.execute(JoinHelper.java:119) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.MasterService.executeTasks(MasterService.java:702) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.MasterService.calculateTaskOutputs(MasterService.java:324) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.MasterService.runTasks(MasterService.java:219) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.MasterService.access$000(MasterService.java:73) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.MasterService$Batcher.run(MasterService.java:151) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.TaskBatcher.runIfNotProcessed(TaskBatcher.java:150) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.TaskBatcher$BatchedTask.run(TaskBatcher.java:188) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:633) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:252) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:215) ~[elasticsearch-7.6.2.jar:7.6.2]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) ~[?:?]
at java.lang.Thread.run(Thread.java:830) [?:?]
因为复制虚拟机时,elsticsearch时,将elsticsearch文件夹下的data文件夹一并复制了。而在前面测试时,data文件夹下已经产生了data数据,于是报上面的错误。
解决办法:删除elsticsearch文件夹下的data文件夹下的节点数据
参考来源:https://blog.csdn.net/ctwctw/article/details/106027078
ES集群配置参考:https://blog.csdn.net/Zereao/article/details/89373246
记一次学习kibaba踩过的坑(Windows环境)的更多相关文章
- Selenium2学习-001-Selenium2 WebUI自动化Java开发 Windows 环境配置
此文主要介绍 Selenium2 WebUI自动化Java开发 Windows 环境配置,供各位亲们参考,若有不足之处,敬请各位大神指正,非常感谢! 所需软件列表如下所示: 所属分类 具体名称 备注 ...
- deeplearing4j学习以及踩过的坑
1. 添加dl4j后, run项目时, 一直run不起来, run按钮绿色但是点击没反应. 查看日志后发现: 是classpath太长导致的. 在本项目的.idea文件夹,找到文件夹中的works ...
- 记一次拿webshell踩过的坑(如何用PHP编写一个不包含数字和字母的后门)
0x01 前言 最近在做代码审计的工作中遇到了一个难题,题目描述如下: <?php include 'flag.php'; if(isset($_GET['code'])){ $code = $ ...
- Python3.7.1学习(六)RabbitMQ在Windows环境下的安装
Windows下安装RabbitMQ 环境配置 部署环境 部署环境:windows server 2008 r2 enterprise(本文安装环境Win7) 官方安装部署文档:http://www. ...
- 流媒体技术学习笔记之(十一)Windows环境运行EasyDarwin
流媒体平台框架下载安装 Github下载 下载地址:https://github.com/EasyDarwin/EasyDarwin/releases 解压安装 选择Windows 安装平台的安装包( ...
- 记一次Socket编程踩的坑
闲来无事研究了下Socket,想用它做个简单的聊天室模型,结果踩了个坑,整半天才出来,惭愧啊,先上完成的代码吧 服务端: public partial class Form1 : Form { pub ...
- 记一次ftp服务器搭建走过的坑
记一次ftp服务器搭建走过的坑 1.安装 ①下载 wget https://security.appspot.com/downloads/vsftpd-3.0.3.tar.gz #要FQ ②解压 ta ...
- 《C++之那些年踩过的坑(附录一)》
C++之那些年踩过的坑(附录一) 作者:刘俊延(Alinshans) 本系列文章针对我在写C++代码的过程中,尤其是做自己的项目时,踩过的各种坑.以此作为给自己的警惕. [版权声明]转载请注明原文来自 ...
- Django 踩过的坑(一)
平台:win10 工具:cmd python3 刚刚学习Django搭建环境,网站还木有发布,就直接来了个大麻烦. 一切按着<Django 学习笔记(二)>这篇文章来的,在最后cmd运行服 ...
随机推荐
- 基于Nginx实现反向代理
一.nginx的简介 Nginx 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务 其特点是占有内存少,并发能力强,事实上nginx的并发能力在同类型的网页服 ...
- 小米手环解锁MacOS系统笔记本MacBookPro
通过小米手环解锁笔记本 官方windows是提供了方法的. 我目前用的MacBookPro,所以说下苹果笔记本的解锁方式. 安装软件BLEUnlock 库 安装方式: brew 安装 brew ins ...
- eBPF Cilium实战(2) - 底层网络可观测性
在之前的平台中,对于组件之间的网络流向不具备直接的可观测性,用户组件间通信出现问题,只能通过传统命令行工具进行手动排查,而 cilium 的 Hubble 服务可以提供 UI 界面向用户展示实时的流量 ...
- Mysql学习day1
安装了Mysql以及SQLyog,将SQLyog和数据库做了连接. 学习了基础数据类型以及命令行语句 1 alter table `student` rename as `stu``lesson` 2 ...
- css 实现输入效果
<template> <h1>Pure CSS Typing animation.</h1> </template> <script> ...
- flex布局 一行4个元素 后面不够4个元素对齐
html 父元素 .container { display: flex; flex-wrap: wrap;} 子元素.list { width: 24%; height: 100px; backgro ...
- window 的简单使用
window 的延迟加载 js代码 window的原始用法 (缺点 : 只能使用一次) window.onload = function() { var btn = document.querySel ...
- JMeter配置Oauth2.0授权接口访问
本文主要介绍如何使用JMeter配置客户端凭证(client credentials)模式下的请求 OAuth2.0介绍 OAuth 2.0 是一种授权机制,主要用来颁发令牌(token) 客户端凭证 ...
- MySQL索引分类及相关概念辨析
本文链接:https://www.cnblogs.com/ibigboy/p/16198243.html 之前的一篇<MySQL索引底层数据结构及原理深入分析>很受读者欢迎,成功地帮大家揭 ...
- 1.2 Linux是什么,有哪些特点?
与大家熟知的 Windows 操作系统软件一样,Linux 也是一个操作系统软件,其 logo 是一只企鹅(如图 1 所示).与 Windows 不同之处在于,Linux 是一套开放源代码程序的.可以 ...