【SQL】窗口函数:求数据组内累计值和累计百分比
〇、概述
1、所需资料
窗口函数实现组内百分比、累计值、累计百分比:https://blog.csdn.net/weixin_39751959/article/details/88828922
2、背景
需求:不同场景不同规则下各区间内基线值的计算和MQ发送
计算位于场景列表内的各场景组合(scene),满足不同规则(rule)某区间dataRange(如20%-80%)的基线平均值
其他场景,计算平均数作为基线值
一、概述
1、输入信息
传入参数:
{"rules":
[{"dataRange":[20,80],"ruleTypeName":"标准基线","duration":30,"ruleType":"1","ruleId":"123"},
{"dataRange":[0,20],"ruleTypeName":"管理基线","duration":60,"ruleType":"2","ruleId":"234"},
{"dataRange":[80,100],"ruleTypeName":"异常基线","duration":90,"ruleType":"3","ruleId":"123"}],
"modules":
[{"moduleNumber":"ltc_contract_basic_info","moduleName":"合同基本信息","calField":"create_time","nextFields":["ltc_contract_basic_info_id"]},
{"moduleNumber":"ltc_contract_assess_basic_info","moduleName":"合同评审信息","preFields":["ltc_contract_basic_info_id"],"nextFields":["ltc_contract_assess_basic_info_id"]},
{"moduleNumber":"ltc_contract_assess_record","moduleName":"合同评审记录","preFields":["ltc_contract_assess_basic_info_id"],"calField":"contract_assess_end_date"}],"
scenes":
{"sceneKeys":
[{"values":["010101","010102","0102","0103","0103"],"key":"sales_scenario"},
{"values":["01","02","03","04","05"],"key":"contract_register_type_code"}],
"sceneGroups":
[{"contract_register_type_code":"03","sales_scenario":"0101"},
{"contract_register_type_code":"03","sales_scenario":"020102"}]},
"definition":
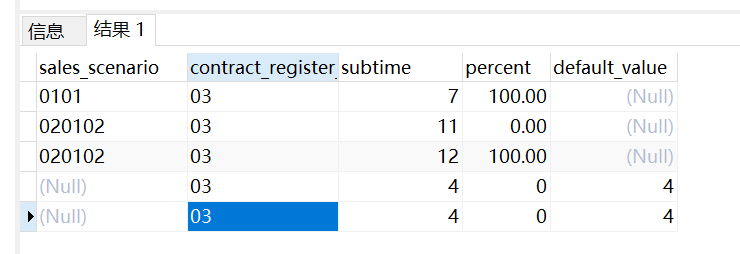
{"definitionName":"从注册到评审的时间基线","version":1,"definitionId":"123"}}2、SQL查询结果
二、实现过程
1、初始信息
根据json可以按照模板生成下列SQL
SELECT
sales_scenario,
contract_register_type_code,
-- ltc_contract_basic_info.create_time,
-- ltc_contract_assess_record.contract_assess_end_date,
DATE_PART('MINUTE', ltc_contract_assess_record.contract_assess_end_date - ltc_contract_basic_info.create_time) subtime,
1 num_every
FROM
ltc_contract_basic_info
LEFT JOIN ltc_contract_assess_basic_info
ON ltc_contract_basic_info.ltc_contract_basic_info_id = ltc_contract_assess_basic_info.ltc_contract_basic_info_id
LEFT JOIN ltc_contract_assess_record
ON ltc_contract_assess_basic_info.ltc_contract_assess_basic_info_id = ltc_contract_assess_record.ltc_contract_assess_basic_info_id
WHERE
ltc_contract_assess_record.contract_assess_end_date > now( ) - INTERVAL '90 days'
and
(sales_scenario,contract_register_type_code) in (('0101','03'),('0102','01'),('020102','03'))设置根据时间差排序,得到如下结果

下一步思路:计算subtime值的百分比
2、计算组内累计值
sum(num_every) over(partition by sales_scenario,contract_register_type_code order by subtime) rk_combine整体:
select
sales_scenario,
contract_register_type_code,
subtime,
sum(num_every) over(partition by sales_scenario,contract_register_type_code order by subtime) rk_combine
from (
SELECT
sales_scenario,
contract_register_type_code,
-- ltc_contract_basic_info.create_time,
-- ltc_contract_assess_record.contract_assess_end_date,
DATE_PART('MINUTE', ltc_contract_assess_record.contract_assess_end_date - ltc_contract_basic_info.create_time) subtime,
1 num_every
FROM
ltc_contract_basic_info
LEFT JOIN ltc_contract_assess_basic_info
ON ltc_contract_basic_info.ltc_contract_basic_info_id = ltc_contract_assess_basic_info.ltc_contract_basic_info_id
LEFT JOIN ltc_contract_assess_record
ON ltc_contract_assess_basic_info.ltc_contract_assess_basic_info_id = ltc_contract_assess_record.ltc_contract_assess_basic_info_id
WHERE
ltc_contract_assess_record.contract_assess_end_date > now( ) - INTERVAL '90 days'
and
(sales_scenario,contract_register_type_code) in (('0101','03'),('0102','01'),('020102','03'))
) res_start3、获得组内最大值
max(rk_combine) over(partition by sales_scenario,contract_register_type_code) max_rk_combine整体:
select
sales_scenario,
contract_register_type_code,
subtime,
rk_combine,
max(rk_combine) over(partition by sales_scenario,contract_register_type_code) max_rk_combine
from
(
select
sales_scenario,
contract_register_type_code,
subtime,
sum(num_every) over(partition by sales_scenario,contract_register_type_code order by subtime) rk_combine
from
(
SELECT
sales_scenario,
contract_register_type_code,
-- ltc_contract_basic_info.create_time,
-- ltc_contract_assess_record.contract_assess_end_date,
DATE_PART('MINUTE', ltc_contract_assess_record.contract_assess_end_date - ltc_contract_basic_info.create_time) subtime,
1 num_every
FROM
ltc_contract_basic_info
LEFT JOIN ltc_contract_assess_basic_info
ON ltc_contract_basic_info.ltc_contract_basic_info_id = ltc_contract_assess_basic_info.ltc_contract_basic_info_id
LEFT JOIN ltc_contract_assess_record
ON ltc_contract_assess_basic_info.ltc_contract_assess_basic_info_id = ltc_contract_assess_record.ltc_contract_assess_basic_info_id
WHERE
ltc_contract_assess_record.contract_assess_end_date > now( ) - INTERVAL '90 days'
and
(sales_scenario,contract_register_type_code) in (('0101','03'),('0102','01'),('020102','03'))
) res_start
) res_middle4、获得百分比
round(rk_combine/max_rk_combine,2)*100 percent整体:
(select
sales_scenario,
contract_register_type_code,
subtime,
round(rk_combine/max_rk_combine,2)*100 percent,
null default_value
from
(
select
sales_scenario,
contract_register_type_code,
subtime,
rk_combine,
max(rk_combine) over(partition by sales_scenario,contract_register_type_code) max_rk_combine
from
(
select
sales_scenario,
contract_register_type_code,
subtime,
sum(num_every) over(partition by sales_scenario,contract_register_type_code order by subtime) rk_combine
from
(
SELECT
sales_scenario,
contract_register_type_code,
-- ltc_contract_basic_info.create_time,
-- ltc_contract_assess_record.contract_assess_end_date,
DATE_PART('MINUTE', ltc_contract_assess_record.contract_assess_end_date - ltc_contract_basic_info.create_time) subtime,
1 num_every
FROM
ltc_contract_basic_info
LEFT JOIN ltc_contract_assess_basic_info
ON ltc_contract_basic_info.ltc_contract_basic_info_id = ltc_contract_assess_basic_info.ltc_contract_basic_info_id
LEFT JOIN ltc_contract_assess_record
ON ltc_contract_assess_basic_info.ltc_contract_assess_basic_info_id = ltc_contract_assess_record.ltc_contract_assess_basic_info_id
WHERE
ltc_contract_assess_record.contract_assess_end_date > now( ) - INTERVAL '90 days'
and
(sales_scenario,contract_register_type_code) in (('0101','03'),('0102','01'),('020102','03'))
) res_start
) res_middle
) res_end)获得位于场景组合的基线均值结果
5、获得默认基线值
(
SELECT
sales_scenario,
contract_register_type_code,
DATE_PART('MINUTE', ltc_contract_assess_record.contract_assess_end_date - ltc_contract_basic_info.create_time) subtime,
0 percent,
avg(DATE_PART('MINUTE', ltc_contract_assess_record.contract_assess_end_date - ltc_contract_basic_info.create_time)) over() default_value
FROM
ltc_contract_basic_info
LEFT JOIN ltc_contract_assess_basic_info
ON ltc_contract_basic_info.ltc_contract_basic_info_id = ltc_contract_assess_basic_info.ltc_contract_basic_info_id
LEFT JOIN ltc_contract_assess_record
ON ltc_contract_assess_basic_info.ltc_contract_assess_basic_info_id = ltc_contract_assess_record.ltc_contract_assess_basic_info_id
WHERE
ltc_contract_assess_record.contract_assess_end_date > now( ) - INTERVAL '90 days'
and
(
sales_scenario is null
or
contract_register_type_code is null
or
(sales_scenario,contract_register_type_code) not in (('0101','03'),('0102','01'),('020102','03')
)
)
)6、结果组合
(select
sales_scenario,
contract_register_type_code,
subtime,
round(rk_combine/max_rk_combine,2)*100 percent,
null default_value
from
(
select
sales_scenario,
contract_register_type_code,
subtime,
rk_combine,
max(rk_combine) over(partition by sales_scenario,contract_register_type_code) max_rk_combine
from
(
select
sales_scenario,
contract_register_type_code,
subtime,
sum(num_every) over(partition by sales_scenario,contract_register_type_code order by subtime) rk_combine
from
(
SELECT
sales_scenario,
contract_register_type_code,
-- ltc_contract_basic_info.create_time,
-- ltc_contract_assess_record.contract_assess_end_date,
DATE_PART('MINUTE', ltc_contract_assess_record.contract_assess_end_date - ltc_contract_basic_info.create_time) subtime,
1 num_every
FROM
ltc_contract_basic_info
LEFT JOIN ltc_contract_assess_basic_info
ON ltc_contract_basic_info.ltc_contract_basic_info_id = ltc_contract_assess_basic_info.ltc_contract_basic_info_id
LEFT JOIN ltc_contract_assess_record
ON ltc_contract_assess_basic_info.ltc_contract_assess_basic_info_id = ltc_contract_assess_record.ltc_contract_assess_basic_info_id
WHERE
ltc_contract_assess_record.contract_assess_end_date > now( ) - INTERVAL '90 days'
and
(sales_scenario,contract_register_type_code) in (('0101','03'),('0102','01'),('020102','03'))
) res_start
) res_middle
) res_end)
union all
(
SELECT
sales_scenario,
contract_register_type_code,
DATE_PART('MINUTE', ltc_contract_assess_record.contract_assess_end_date - ltc_contract_basic_info.create_time) subtime,
0 percent,
avg(DATE_PART('MINUTE', ltc_contract_assess_record.contract_assess_end_date - ltc_contract_basic_info.create_time)) over() default_value
FROM
ltc_contract_basic_info
LEFT JOIN ltc_contract_assess_basic_info
ON ltc_contract_basic_info.ltc_contract_basic_info_id = ltc_contract_assess_basic_info.ltc_contract_basic_info_id
LEFT JOIN ltc_contract_assess_record
ON ltc_contract_assess_basic_info.ltc_contract_assess_basic_info_id = ltc_contract_assess_record.ltc_contract_assess_basic_info_id
WHERE
ltc_contract_assess_record.contract_assess_end_date > now( ) - INTERVAL '90 days'
and
(
sales_scenario is null
or
contract_register_type_code is null
or
(sales_scenario,contract_register_type_code) not in (('0101','03'),('0102','01'),('020102','03')
)
)
)三、步骤总结
1、计算组内累计值
sum(saleroom) over(partition by area order by date) ---求组内累计值
2、计算组内总计值/最大值
sum(saleroom) over(partition by area order by area) ---求组内总计值
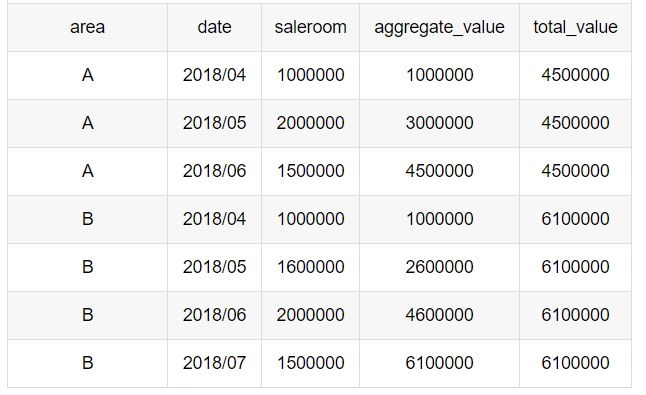
3、累计值/总计值
组内百分比= saleroom / total_value
累计百分比 = aggregate_value/total_value
四、总结
1、过程
用1表示每项的值
分组计算,按照subtime排序,得到累计值
求出最大的累计值,作为和
用各项累计值除以每一项的和,得到百分比
2、结果计算与返回
package com.boulderai.baseline.cal.service.impl;
import com.boulderai.baseline.cal.mq.MessageProducer;
import com.boulderai.baseline.cal.service.BaseLineCalService;
import cn.hutool.json.JSONUtil;
import com.boulderai.timeline.api.bigdata.BaseLineCalRequest;
import com.boulderai.timeline.api.bigdata.BaseLineMessage;
import org.apache.commons.lang3.StringUtils;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import lombok.extern.slf4j.Slf4j;
import javax.annotation.Resource;
import java.math.BigDecimal;
import java.util.*;
import java.util.concurrent.atomic.AtomicReference;
import java.util.stream.Collectors;
/**
* @Title:BaseLineCalServiceImpl
* @Descript:
* @author: yanwei (yanwei@yanxxcloud.cn)
* @date:2022/8/3
**/
@Service
@Slf4j
public class BaseLineCalServiceImpl implements BaseLineCalService {
@Resource
private MessageProducer messageProducer;
@Resource
private JdbcTemplate jdbcTemplate;
/**
* @author 刘金辉
* @param request
* @return 发送MQ是否成功
*/
@Override
public Boolean calculate(BaseLineCalRequest request) {
List<BaseLineMessage> messageList = new ArrayList<>();
request.getRules().forEach(rule -> {
String sql = request.computeSql(rule.getRuleType());
String[] union_sql_list = sql.split("union all");
String sql_in_scene_list = union_sql_list[0];
Integer[] dataRange = rule.getDataRange();
List<Map<String, Object>> resListMiddle = jdbcTemplate.queryForList(sql_in_scene_list);
//sceneKeysList为场景的集合,如[delivery_way_code,contract_register_type_code]
List<String> sceneKeysList = request.getScenes()
.getSceneKeys().stream()
.map(x -> x.getKey()).collect(Collectors.toList());
List<Map<String, Object>> resListUltimate = new ArrayList<>();
//inSceneListRes为查询到的拆分场景的结果集
List<Map<String, Object>> inSceneListRes = jdbcTemplate.queryForList(sql_in_scene_list).stream()
.filter(x -> Math.round(Double.valueOf(x.get("percent").toString())) >= dataRange[0]
&& Math.round(Double.valueOf(x.get("percent").toString())) <= dataRange[1])
.collect(Collectors.toList());
request.getScenes().getSceneGroups().forEach(sceneValueMap -> {
//sceneValueMap为每一个场景组合,如[delivery_way_code -> 01,contract_register_type_code -> 01,02]
Map<String, Object> resInMap = new HashMap<String, Object>(); //构建每个要插入的map
sceneValueMap.entrySet().forEach(everySceneCombine->{
resInMap.put(everySceneCombine.getKey(),everySceneCombine.getValue());
});
Double baselineValue = computeResult2New(sceneValueMap, sceneKeysList, inSceneListRes);
resInMap.put("value", baselineValue);
resListUltimate.add(resInMap);
});
int default_value = 0;
String sql_not_in_scene_list = union_sql_list[1];
List<Map<String, Object>> result = jdbcTemplate.queryForList(sql_not_in_scene_list);
if (!CollectionUtils.isEmpty(result)) {
default_value = Math.round(Float.parseFloat(result.get(0).get("default_value").toString()));
}
BaseLineMessage ansMsg = new BaseLineMessage();
ansMsg.setDefinition(request.getDefinition());
ansMsg.setRule(rule);
ansMsg.setValues(resListUltimate);
ansMsg.setDefaultValue(default_value);// 其他场景的平均值,如何确定
messageList.add(ansMsg);
});
log.info("cal:{}", JSONUtil.toJsonStr(request));
log.info("cal.return:{}", JSONUtil.toJsonStr(messageList));
messageProducer.SendCalMessageList(messageList);
return true;
}
/**
* 场景组合拆分为子场景,去数据库查询
* sceneValueMap为每一个场景组合,如[delivery_way_code -> 01,contract_register_type_code -> 01,02, value=10]
* sceneKeysList为场景的集合,如[delivery_way_code,contract_register_type_code]
* inSceneListRes为查询到的拆分场景的结果集
* @param group
* @param sceneKeys
* @param result
* @return
*/
private Double computeResult2New(Map<String, String> sceneValueMap, List<String> sceneKeysList, List<Map<String, Object>> inSceneListResList) {
Double avgOfCombineSceneVal = 0.0;
List<String> splitSceneValList = Arrays.asList("");
String[] sceneKeysArray = String.join(",", sceneKeysList).split(",");
for (String sceneKey : sceneKeysArray) {
String assignKeyValue = String.valueOf(sceneValueMap.get(sceneKey));
String[] splitValueArray = assignKeyValue.split(","); //assignKeyValue=01,02 | splitValueArray=[01][02]
splitSceneValList = calgroup(splitValueArray, splitSceneValList); //splitSceneValList=[01][02]=>splitSceneValList=[01,01][01,02]
}
for (String everySceneCombineStr : splitSceneValList) { //splitSceneValList=[“01,01”,"01,02"] everySceneCombineStr="01,02"
List<Map<String, Object>> filterEverySceneCombineResList = inSceneListResList.stream().filter(qryResMap -> {
boolean fetched = true;
String[] everySceneStr = everySceneCombineStr.split(","); //["01", "02"]
for (int i = 0; i < everySceneStr.length; i++) {
fetched = everySceneStr[i].equals(String.valueOf(qryResMap.get(sceneKeysArray[i]))); //找到满足条件的子数据
if (!fetched) {
return false;
}
}
return fetched;
}).collect(Collectors.toList());//过滤得到满足每个场景组合的数据
Double avgRes = filterEverySceneCombineResList.stream().map(p -> Math.round(Double.valueOf(p.get("subtime").toString())))
.collect(Collectors.averagingLong(Long::longValue));
avgOfCombineSceneVal += avgRes;
}
return avgOfCombineSceneVal/splitSceneValList.size();
}
/**
* @param group
* @param sceneKeys
* @param result
* @return
*/
private BigDecimal calResultBefore(Map<String, String> group, List<String> sceneKeys, List<Map<String, Object>> result) {
List<String> rarry = Arrays.asList("");
String[] arrKeys = String.join(",", sceneKeys).split(",");
for (String key : arrKeys) {
String v = String.valueOf(group.get(key));
String[] varr = v.split(",");
rarry = calgroup(varr, rarry);
}
//fetch data
List<Map<String, Object>> results = new ArrayList<>();
for (String r : rarry) { //,020102,03
List<Map<String, Object>> subList = result.stream().filter(rmap -> {
boolean fetched = true;
//String[] var = (String[]) Arrays.stream(r.split(",")).skip(0).collect(Collectors.toList()).toArray();
String[] var = r.split(","); //["", "020102", "03"]
for (int i = 0; i < var.length; i++) {
fetched = var[i].equals(String.valueOf(rmap.get(arrKeys[i])));
if (!fetched) {
return false;
}
}
return fetched;
}).collect(Collectors.toList());
results.addAll(subList);
}
//计算结果
return BigDecimal.ZERO;
}
/**
* @param vs
* @param sub
* @return
*/
private List<String> calgroup(String[] vs, List<String> sub) {
List<String> ans = new ArrayList<>();
for (String v : vs) {
sub.stream().forEach(s -> {
if (StringUtils.isBlank(s)) {
ans.add(v);
} else {
ans.add(s + "," + v);
}
});
}
return ans;
}
}【SQL】窗口函数:求数据组内累计值和累计百分比的更多相关文章
- SQL ROW_NUMBER()实现取组内最新(最大)的数据
SELECT * FROM(select ROW_NUMBER() over(partition BY sid order by cscore desc) as tid,sid,cname,cscor ...
- SQL分组求每组最大值问题的解决方法收集 (转载)
例如有一个表student,其结构如下: id name sort score 1 张三 语文 82 2 李四 数 ...
- sql server迁移数据(文件组之间的互相迁移与 文件组内文件的互相迁移)
转自:https://www.cnblogs.com/lyhabc/p/3504380.html?utm_source=tuicool SQLSERVER将数据移到另一个文件组之后清空文件组并删除文件 ...
- [SQL]用于提取组内最新数据,左连接,内连接,not exist三种方案中,到底谁最快?
本作代码下载:https://files.cnblogs.com/files/xiandedanteng/LeftInnerNotExist20191222.rar 人们总是喜欢给出或是得到一个简单明 ...
- 【HIVE高级笔试必备题型】(组内topN、相邻行的值比较问题)求语文大于数学_/_求文科大于理科成绩的学生
Hive SQL练习之成绩分析 数据:[id, 学号,班级,科目,成绩] 1,1,1,yuwen,80 2,1,1,shuxue,85 3,2,1,yuwen,75 4,2,1,shuxue,70 5 ...
- sql查询技巧,按时间分段进行分组,每半小时一组统计组内记录数量
今天拿到一个查询需求,需要统计某一天各个时间段内的记录数量. 具体是统计某天9:00至22:00时间段,每半小时内订单的数量,最后形成的数据形式如下: 时间段 订单数 9:00~9: ...
- 如何用SQL实现组内前几名的输出
关于问题 如何查询组内最大的,最小的,大家或许都知道,无非是min.max的函数使用.可是如何在MySQL中查找组内最好的前两个,或者前三个? 什么是相关子查询 在提出对于这个问题的对应方法之前,首先 ...
- mssql sqlserver 使用sql脚本获取群组后,按时间排序(asc)第一条数据的方法分享
摘要: 下文讲述使用sql脚本,获取群组后记录的第一条数据业务场景说明: 学校教务处要求统计: 每次作业,最早提交的学生名单下文通过举例的方式,记录此次脚本编写方法,方便以后备查,如下所示: 实现思路 ...
- 模拟QQ分组(具有伸缩功能) (添加开源框架的光闪烁效果)SimpleExpandableListAdapter 适配器的用法,并且可添加组及其组内数据。
package com.lixu.qqfenzu; import java.util.ArrayList; import java.util.HashMap; import java.util.Lis ...
- sql 分组取每组的前n条或每组的n%(百分之n)的数据
sql 分组取每组的前n条或每组的n%(百分之n)的数据 sql keyword: SELECT * ,ROW_NUMBER() OVER(partition by b.UserID order by ...
随机推荐
- kratos v2版本命令行工具使用
使用 下载 go install github.com/go-kratos/kratos/cmd/kratos/v2@latest 查看是否安装成功 kratos -v kratos version ...
- Elasticsearch: Cerebro 用户界面介绍
- PAT (Basic Level) Practice 1017 A除以B 分数 20
本题要求计算 A/B,其中 A 是不超过 1000 位的正整数,B 是 1 位正整数.你需要输出商数 Q 和余数 R,使得 A=B×Q+R 成立. 输入格式: 输入在一行中依次给出 A 和 B,中间以 ...
- Java导出带格式的Excel数据到Word表格
前言 在Word中创建报告时,我们经常会遇到这样的情况:我们需要将数据从Excel中复制和粘贴到Word中,这样读者就可以直接在Word中浏览数据,而不用打开Excel文档.在本文中,您将学习如何使用 ...
- Netty 学习(八):新连接接入源码说明
Netty 学习(八):新连接接入源码说明 作者: Grey 原文地址: 博客园:Netty 学习(八):新连接接入源码说明 CSDN:Netty 学习(八):新连接接入源码说明 新连接的接入分为3个 ...
- Dest0g3迎新赛misc部分解析
目录 1. Pngenius 2. EasyEncode 3. 你知道js吗 4. StrangeTraffic 5. EasyWord 6.4096 7.python_jail 8. codeg ...
- linux下rsync的同步
rsync是linux系统下的数据镜像备份工具.使用快速增量备份工具Remote Sync可以远程同步,支持本地复制,或者与其他SSH.rsync****主机同步 文件下载地址: 链接:https:/ ...
- Invalid bound statement (not found): com.zheng.mapper.UserMapper.login
错误的原因:mybatis中dao接口与mapper配置文件在做映射绑定的时候出现问题,简单说,就是接口与xml要么是找不到,要么是找到了却匹配不到. mapper接口开发规范 1.Mapper.xm ...
- JSON parse error: Cannot deserialize value of type `java.lang.Integer` from Boolean value
问题原因所在:前端Vue传输的数据字段类型和后端实体类字段不一致. 我的实体类字段是int类型.前端传输的数据是布尔类型. 文章目录 1.后端方法 2.实体类字段 2.前端传输的数据 1.后端方法 @ ...
- python dir函数解析
dir() 函数 不带参数,直接执行是返回当前环境中对象的名称列表.指定对象的名称作为参数执行,返回指定对象当中的属性(包括函数名,类名,变量名等) 下面我们具体找几个例子测试一下 dir() ...