【重难点总结】DMA与kafka零拷贝机制之间的关系
一、DMA介绍
1、概念
DMA(Direct Memory Access,直接存储器访问) 是一种内存访问技术,独立于CPU, 直接读、写系统存储器、外设等
主存与I/0设备之间使用DMA控制器控制一个数据通路(专用数据总线)进行数据传输,无需依赖于CPU进行中断
I/O设备(字符设备和块设备):硬盘、USB、打印机
CPU除了在数据传输开始和结束时做一点处理外(开始和结束时候要做中断处理),在传输过程中CPU可以进行其他的工作。
2、不使用DMA方式时
CPU:将数据复制到CPU的暂存器,再写回到新位置,此时CPU无法使用
3、应用场景
主存与I/O设备之间进行数据交互
例如:运行一个程序,调用一段数据
二、零拷贝机制
1、解决的问题
从磁盘读取一个文件通过网络输出到一个客户端
步骤:从磁盘读取文件,将文件写入到socket(套接字,网卡驱动)
2、传统的传输方式-也需要经过DMA传输
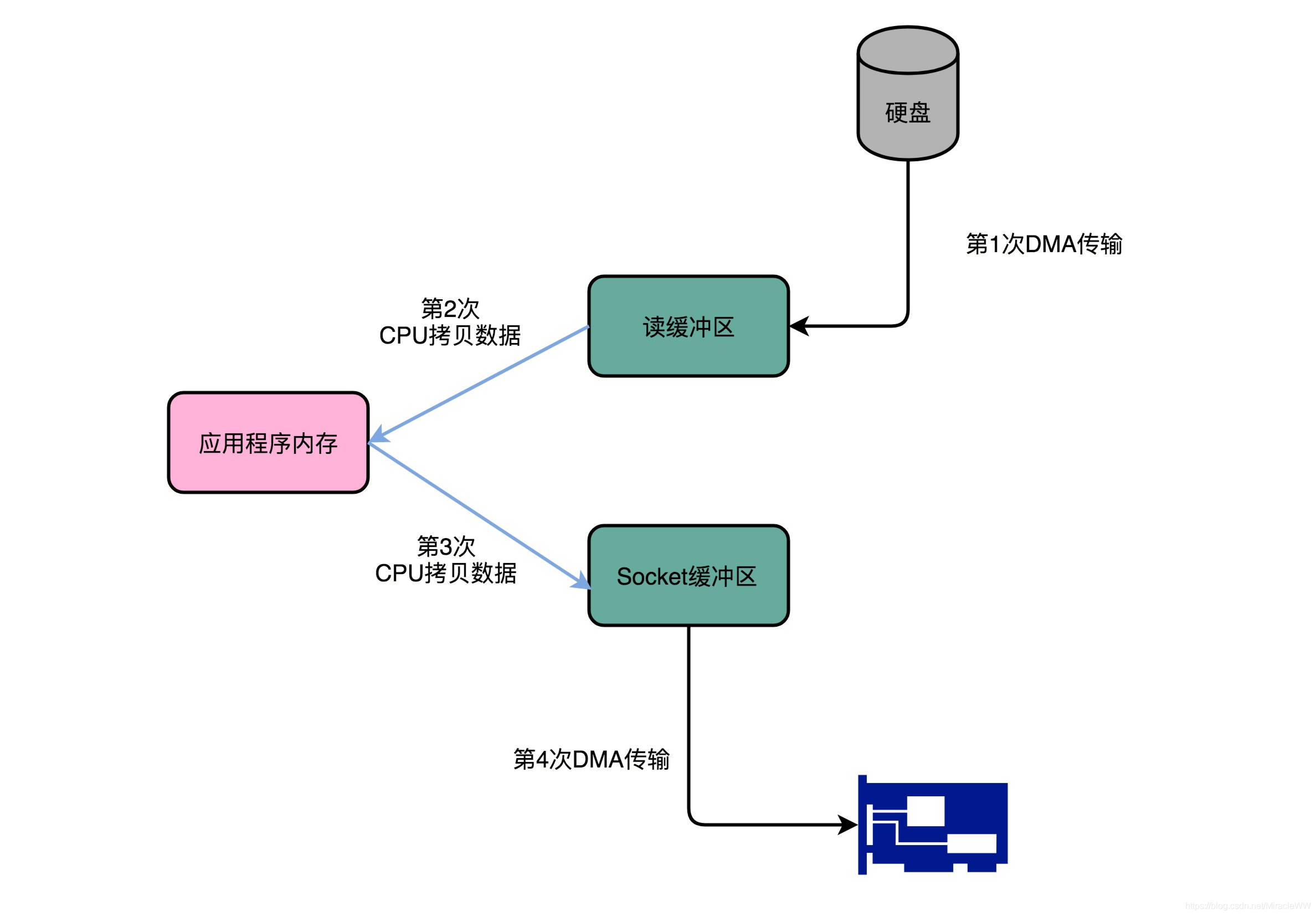
(1)过程描述-4次拷贝
数据从磁盘复制到内核缓冲区
从内核缓冲区复制到用户空间缓冲区【内存】(需要切换到用户态空间)
从用户缓冲区复制到内核的socket缓冲区
从socket缓冲区复制到协议引擎(这里是网卡驱动)
(2)kafka图解
硬盘-内存-socket缓冲区-网卡驱动
2、零拷贝方式-使用Linux内核中sendfile的系统调用(合并缓冲区-内存-socket)
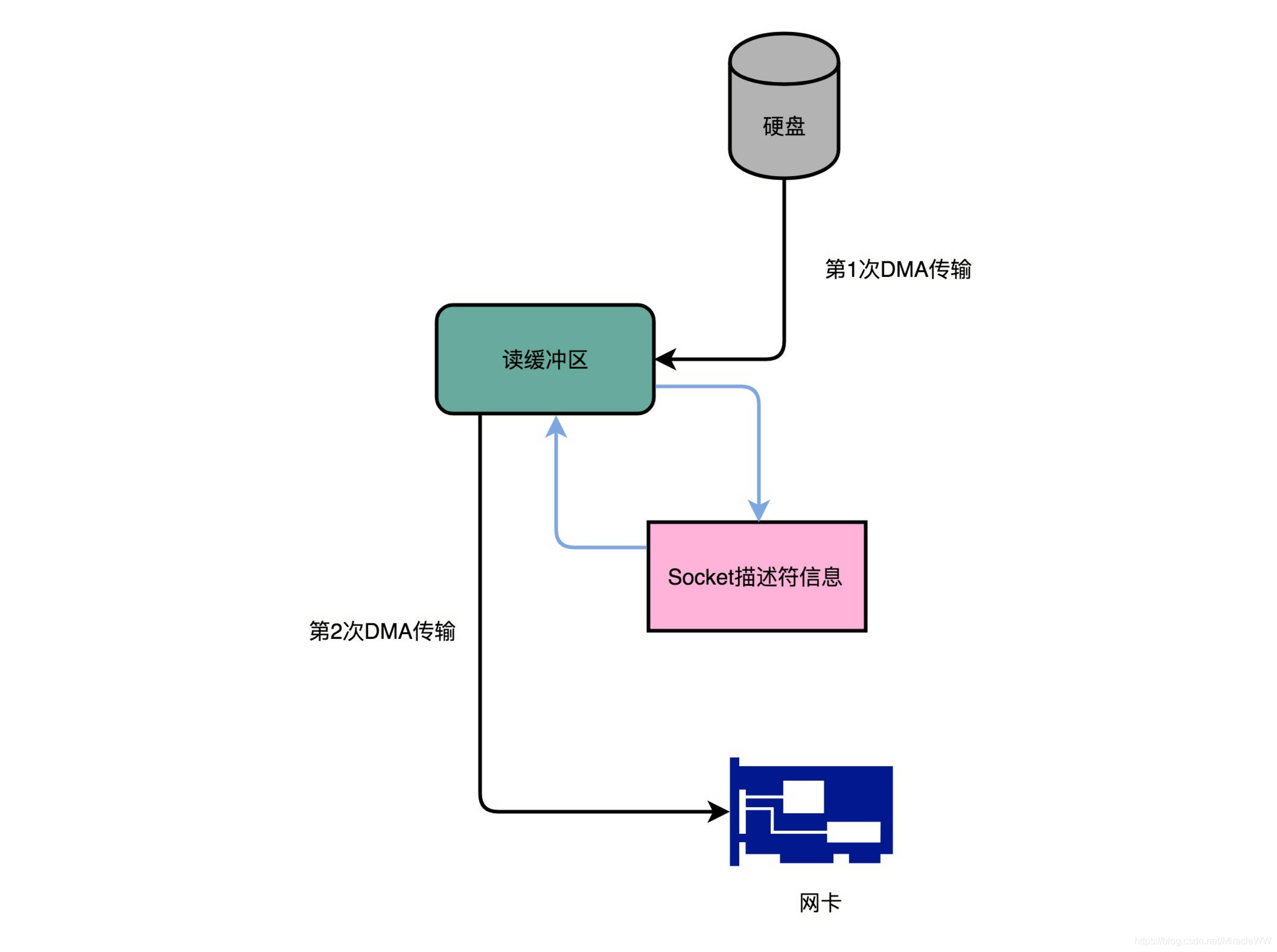
(1)过程描述
从磁盘读取文件内容到内核缓冲区
直接从内核缓冲区复制数据到socket缓冲区(原来:缓冲区-内存/用户空间,内存-socket)
从socket缓冲区复制到协议引擎(这里是网卡驱动)
(2)kafka过程图解
3、零拷贝机制与DMA的关系
无需经过CPU拷贝数据到内存中,直接将读缓冲区的地址写入socket
网卡根据 Socket 的描述符信息,直接从读缓冲区,写入到网卡驱动
应用程序通过调用mmap(),将不同的虚拟地址映射到了同一物理地址,即内核缓冲区,使程序在用户态可以直接读取并操作内核空间的数据
使用DMA方式将磁盘数据读取到内核缓冲区,通过内存映射,使用户缓冲区和内核读缓冲区的内存地址为同一内存地址
【重难点总结】DMA与kafka零拷贝机制之间的关系的更多相关文章
- kafka零拷贝机制
kafka之所以那么快,其中一个很大的原因就是零拷贝(Zero-copy)技术,零拷贝不会kafka的专利,而是操作系统的升级,又比如Netty,也用到了零拷贝. 传统IO kafka的数据是要落入磁 ...
- kafka 零拷贝
kafka通过零拷贝实现高效的数据传输 https://blog.csdn.net/lxlmycsdnfree/article/details/78973864 Kafka零拷贝 https://bl ...
- 深入剖析Linux IO原理和几种零拷贝机制的实现
深入剖析Linux IO原理和几种零拷贝机制的实现 来源 https://zhuanlan.zhihu.com/p/83398714 零壹技术栈 公众号[零壹技术栈] 前言 零拷贝(Zero ...
- 框架篇:Linux零拷贝机制和FileChannel
前言 大白话解释,零拷贝就是没有把数据从一个存储区域拷贝到另一个存储区域.但是没有数据的复制,怎么可能实现数据的传输呢?其实我们在java NIO.netty.kafka遇到的零拷贝,并不是不复制数据 ...
- Netty源码解析 -- 零拷贝机制与ByteBuf
本文来分享Netty中的零拷贝机制以及内存缓冲区ByteBuf的实现. 源码分析基于Netty 4.1.52 Netty中的零拷贝 Netty中零拷贝机制主要有以下几种 1.文件传输类DefaultF ...
- 转载一篇关于kafka零拷贝(zero-copy)通俗易懂的好文
原文地址 https://www.cnblogs.com/yizhou35/p/12026263.html 零拷贝就是一种避免CPU 将数据从一块存储拷贝到另外一块存储的技术. DMA技术是Direc ...
- kafka零拷贝
Kafka之所以那么快的另外一个原因就是零拷贝(zero-copy)技术.本文我们就来了解Kafka中使用的零拷贝技术为什么那么快. 传统的文件拷贝 传统的文件拷贝通常需要从用户态去转到核心态,经过r ...
- java的零拷贝机制
转:https://blog.csdn.net/zhouhao88410234/article/details/77574689?fps=1&locationNum=9 为何要懂零拷贝原理?因 ...
- Java后端进阶-网络编程(Netty零拷贝机制)
package com.study.hc.net.netty.demo; import io.netty.buffer.ByteBuf; import io.netty.buffer.Unpooled ...
- 零拷贝详解 Java NIO学习笔记四(零拷贝详解)
转 https://blog.csdn.net/u013096088/article/details/79122671 Java NIO学习笔记四(零拷贝详解) 2018年01月21日 20:20:5 ...
随机推荐
- 微服务系列之Api文档 swagger整合
1.前言 微服务架构随之而来的前后端彻底分离,且服务众多,无论是前后端对接亦或是产品.运营翻看,一个现代化.规范化.可视化.可尝试的文档是多么重要,所以我们这节就说说swagger. Swagger是 ...
- fastdfs-zyc管理FastDFS的web界面
俩压缩包根据大小重命名以下,按图片所示 把1_fastdfs-zyc.7z重命名为fastdfs-zyc.7z.001 把2_fastdfs-zyc.7z重命名为fastdfs-zyc.7z.002 ...
- CentOS7内置Realtek网卡驱动r8169降级r8168
前几天装了几台服务器测试,在使用的过程中发现,每次重启系统,登录界面会弹出网卡提示 "r8169 0000:02:00 eth0 Invalid ocp reg 17758!" ...
- flutter系列之:深入理解布局的基础constraints
目录 简介 Tight和loose constraints 理解constraints的原则 总结 简介 我们在flutter中使用layout的时候需要经常对组件进行一些大小的限制,这种限制就叫做c ...
- HM VNISEdit2.0.3修正版
HM VNISEdit,曾经是NSIS最强最佳开源免费编辑器/IDE,但2003年至今原作者已经接近20年未再更新,随着NSIS3.X版本的普及,NIS Edit不可避免的出现了大大小小的各种BUG, ...
- NSIS 去除字串中的汉字
!include "LogicLib.nsh" XPStyle on !include "WordFunc.nsh" #编写,水晶石 #去除字串中的汉字 #本例 ...
- Python实验报告(第四周
一.实验目的和要求 学会应用列表.元组.字典等序列: 二.实验环境 软件版本:Python 3.10 64_bit 三.实验过程 1.实例1:输出每日一贴 (1)在IDLE中创建一个名称为tips.p ...
- HDU3506 Monkey Party (区间DP)
一道好题...... 首先要将环形转化为线形结构,接着就是标准的区间DP,但这样的话复杂度为O(n3),n<=1000,要超时,所以要考虑优化. dp[i][j]=min( dp[i][k]+d ...
- 从源码分析 MGR 的流控机制
Group Replication 是一种 Shared-Nothing 的架构,每个节点都会保留一份数据. 虽然支持多点写入,但实际上系统的吞吐量是由处理能力最弱的那个节点决定的. 如果各个节点的处 ...
- .NET Core C#系列之XiaoFeng.Data.IQueryableX ORM框架
当前对象操作数据库写法和EF Core极度类似,因为现在大部分程序员都懒得去写SQL,再一个就是项目作大了或其它原因要改数据库,每次改数据库,那么写的SQL语句大部分要作调整,相当麻烦,并且写SQ ...