nifi从入门到实战(保姆级教程)——flow
本文章首发于博客园,转载请标明出处
经过前两篇文章(环境篇,身份验证),我们已经有了nifi可以运行的基础,今天就来实现一个案例吧。
假设我们要从ftp上获取一个zip包,里面有两个csv文件,一个是manufacture.csv,一个是brand.csv.然后要把这两个文件导入到sqlserver数据库中。其中brand是manufacture的下一级,但是brand里没有manufacture的主键,必须要通过一些关键字段的匹配来找出它们。
在实现这个场景之前,我们需要认识一下nifi中的几个重要组件。
Processor : 主要用来处理flowfile,也就是我们的数据。nifi提供了上百个不同功能的processor,一般的需求都能满足。当然它也支持自定义processor,需要用java自行开发。
Processor Group :简单地理解就是把processor的流程组合成一个整体。只有Processor Group有version,所以它对于后续流程的迁移很重要。
Input Port,Output Port : 这两个主要是用于联接group.
有这些了解后就开始吧!
先看看流程的整体吧
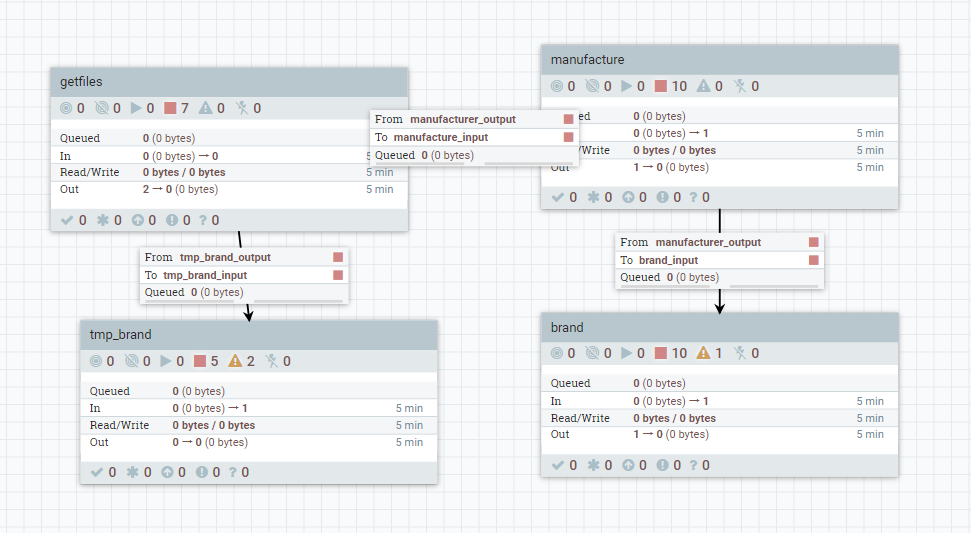
- 首先拖拽一个group在画布中,并为这个group命名为Import,如下图
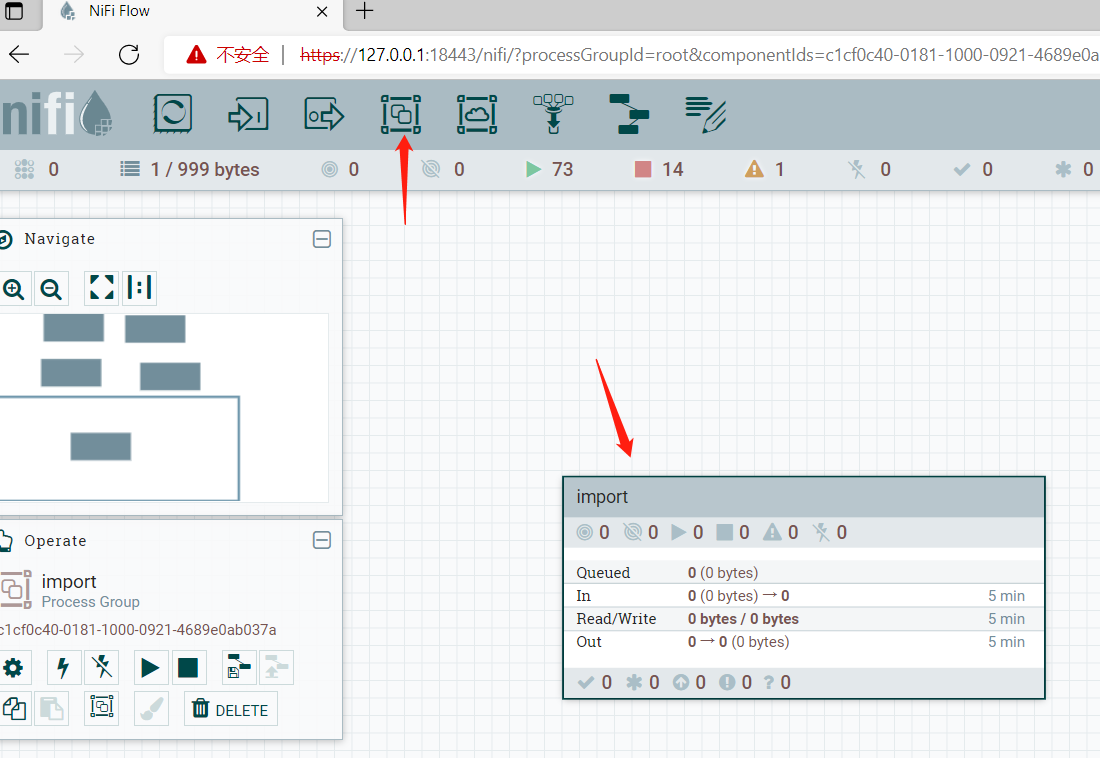
双击group进入。再建一个group,命名为getfiles.这个group主要负责从ftp上获取文件,并解压。
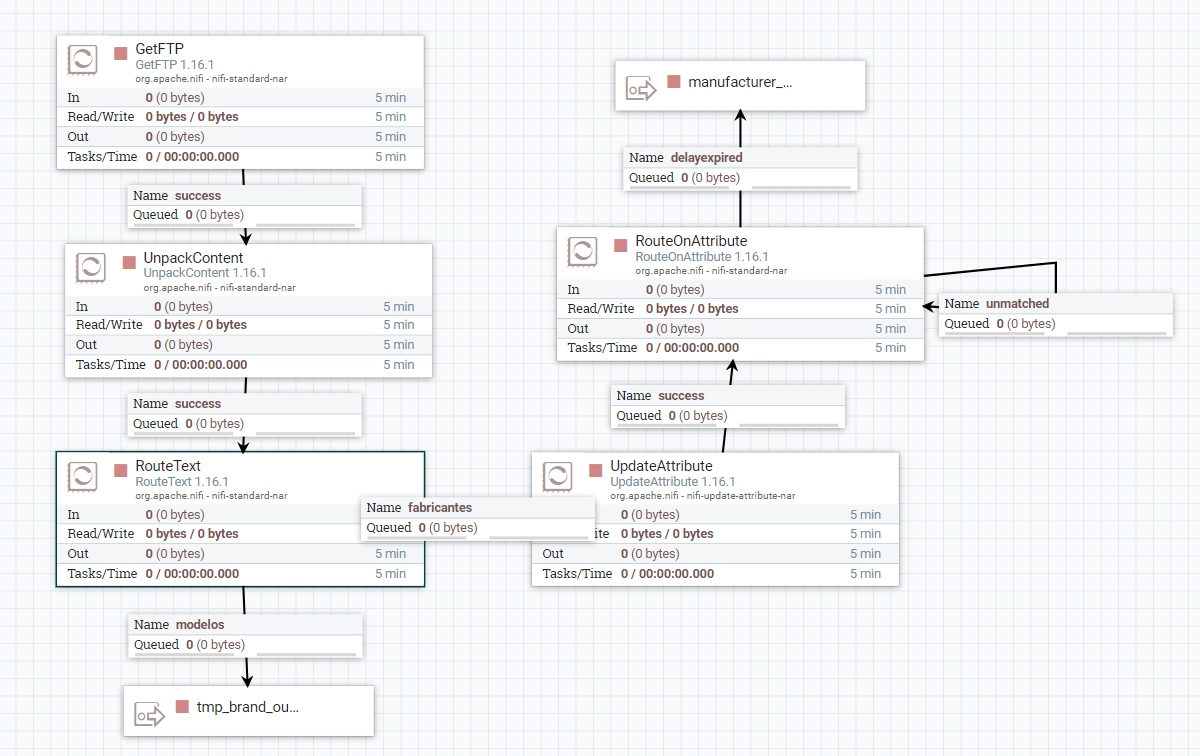
GetFTP:主要填以下几个属性。
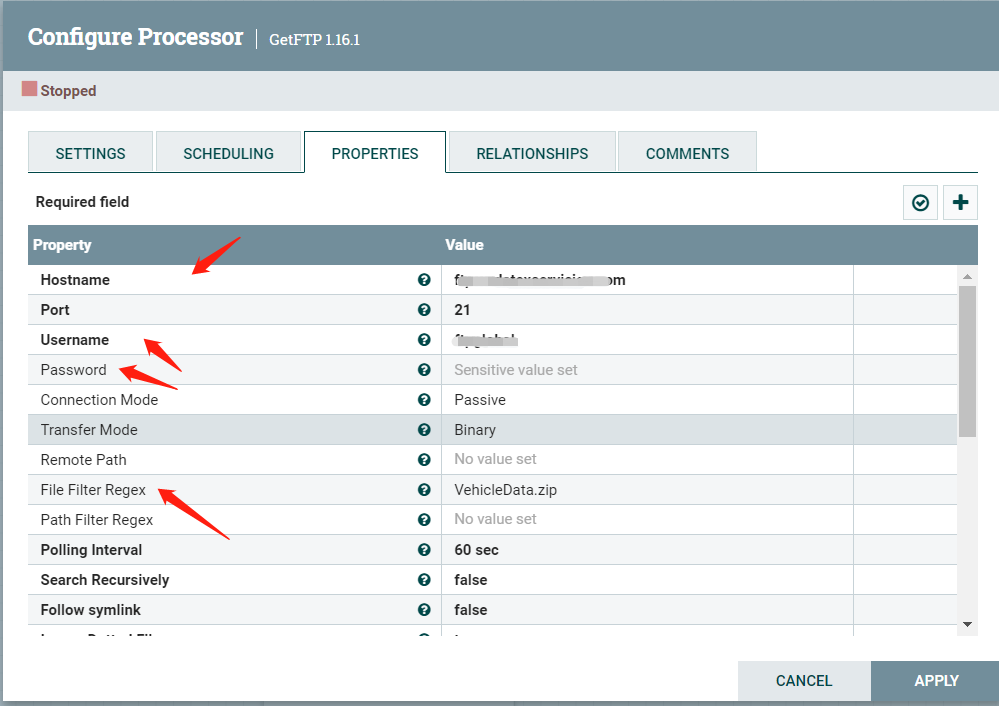
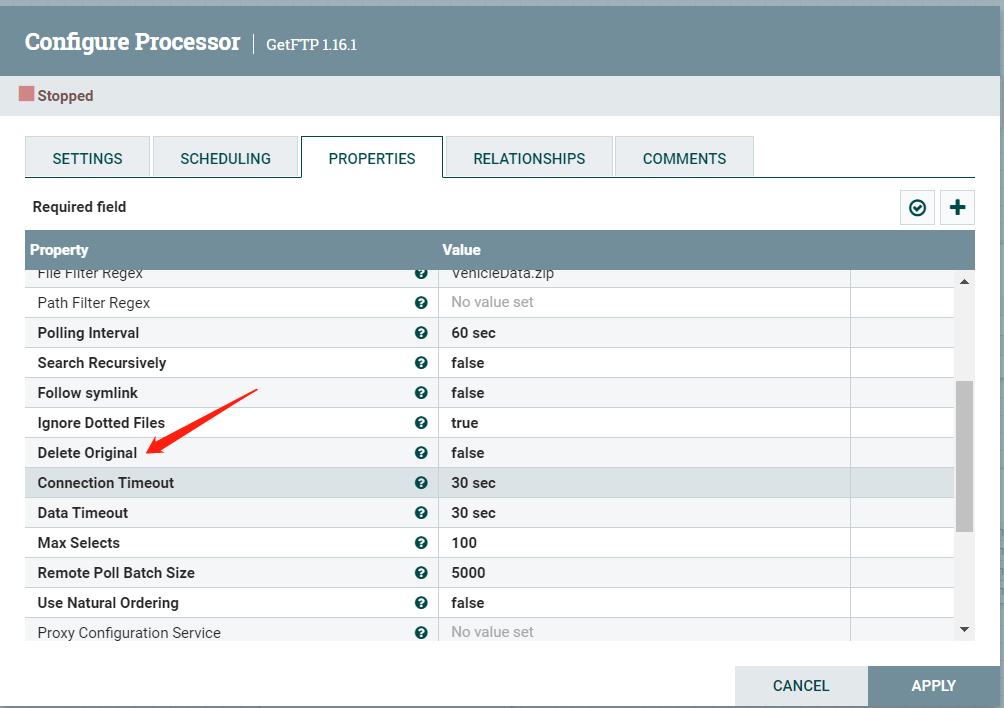
Delete Origianl默认为true,会删除ftp上的文件,所以最好设置为false.类似的Processor还有getfile,使用时一定要注意。
因为我们获取的是一个zip包,所以需要解压。这个比较简单,默认就行了。如果压缩文件有密码,设置一下password属性就好了。

接下来就有点复杂了。因为我们的manufacture和brand是要进不同的表,所以就要路由了。这里就要用到route的processor,我用的是RouteText,也可以用RouteOnAttribute,只是一些设置不同。后面我也会用到。
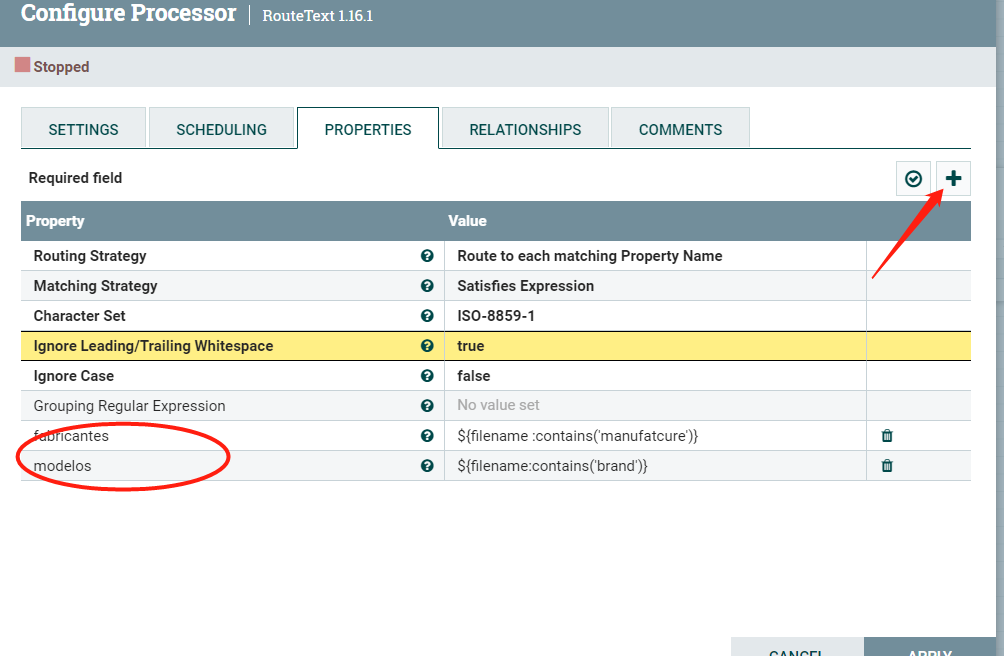
添加了两个路由属性:fabricantes,modelos.这个名字你可以随便取。如果filename包含manufacture就走fabricantes分支,包含brand就走modelos分支。
后面我做了一个延时,大家可以根据实际情况自由选择。这里我也介绍一下。
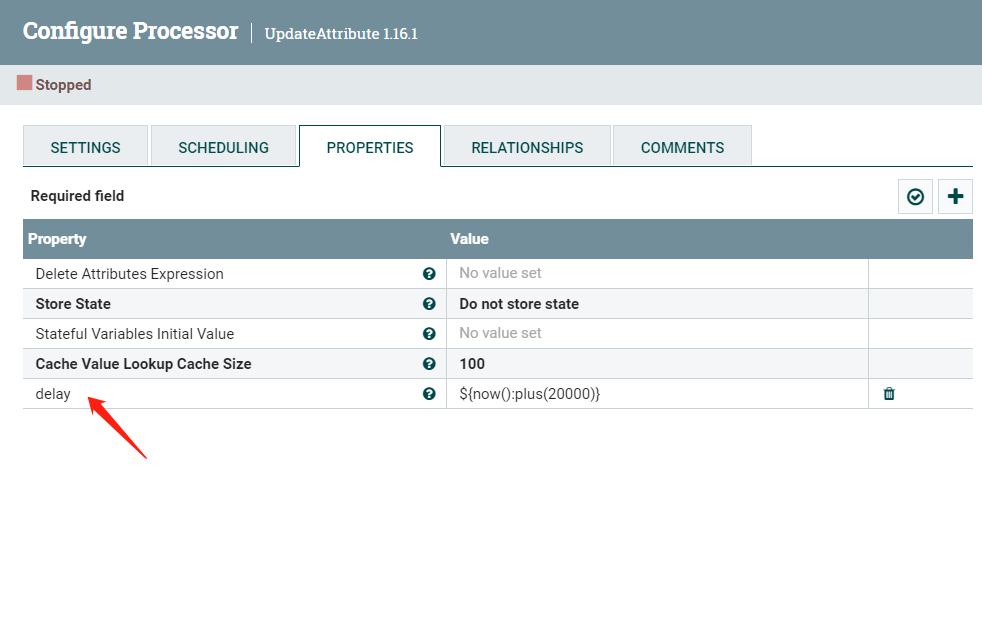
先用UpdateAttribute添加一个属性delay,值为当前时间加20s.
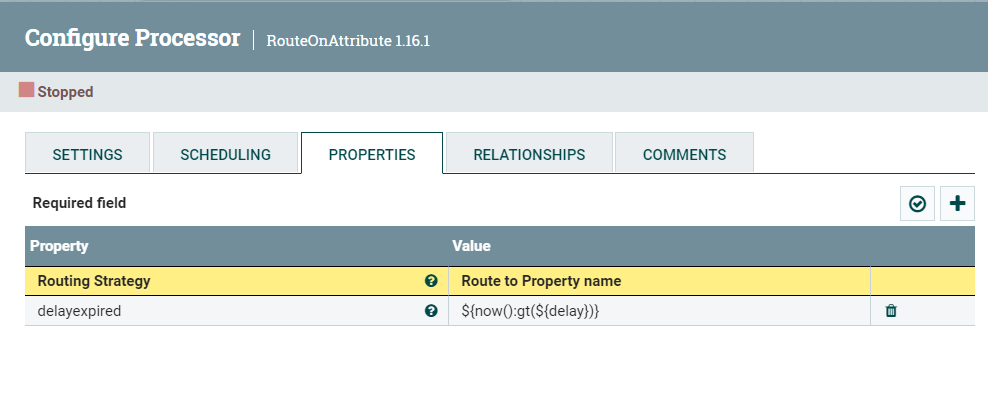
再用RouteOnAttribute来在规定时间内死循环,直到当前时间大于规定时间。
最后用两个output port结束当前group. - 将brand的数据存储到SQL SERVER的一张临时表里。
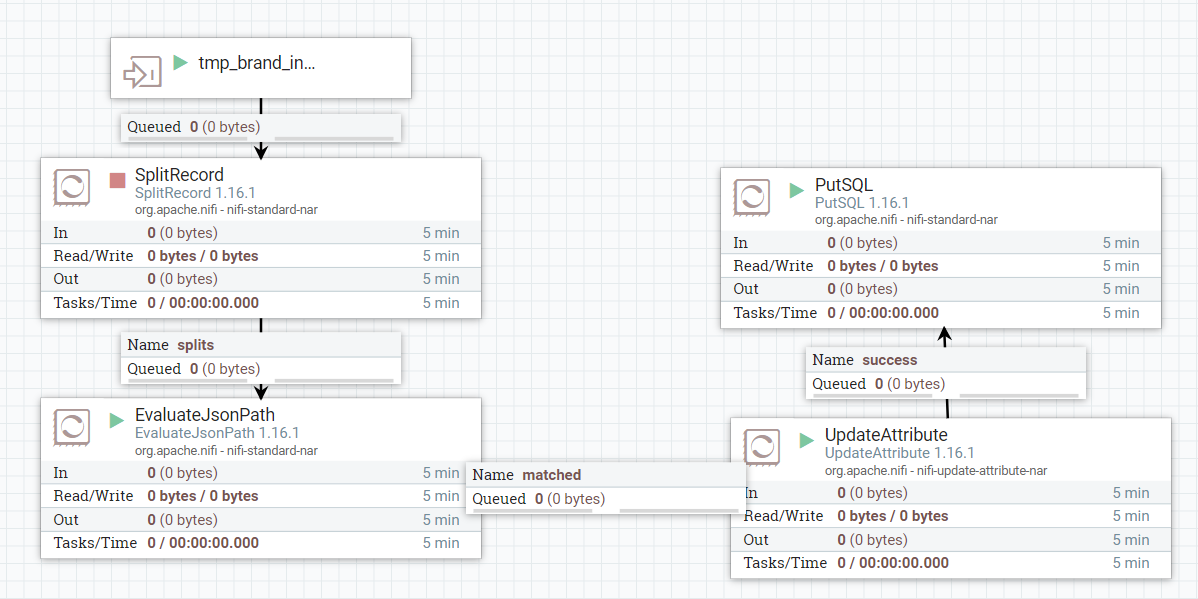
建立一个group,名为tmp_barnd.这个group一开始必须是input port,用于接收上一个group传出的数据。
SplitRecord:
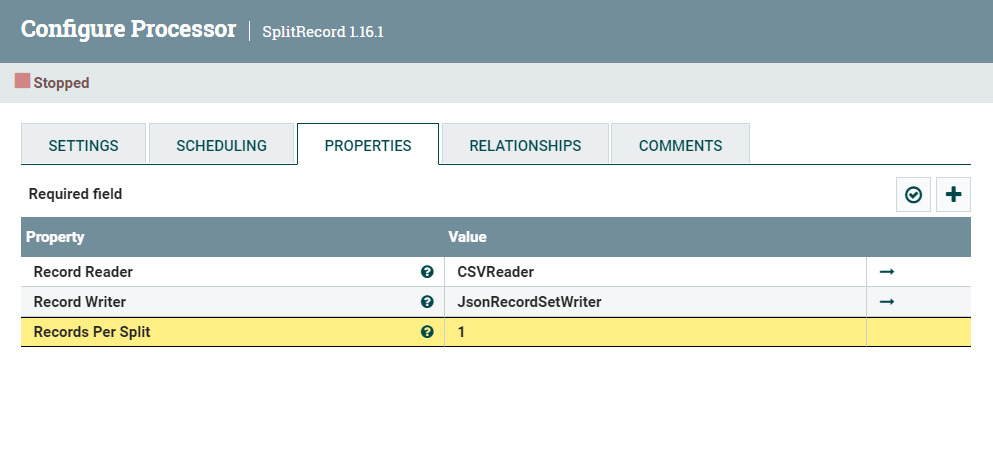
这里用到两个controller service: CSVReader,JsonRecordSetWriter.

根据实际情况修改一下相应属性。我觉得比较重要的是Value Separator(默认是","但是很自定义的csv可能是";""),Character Set(默认是UTF-8,比如我的文档里有特殊符号,用的是ISO-8859-1)。
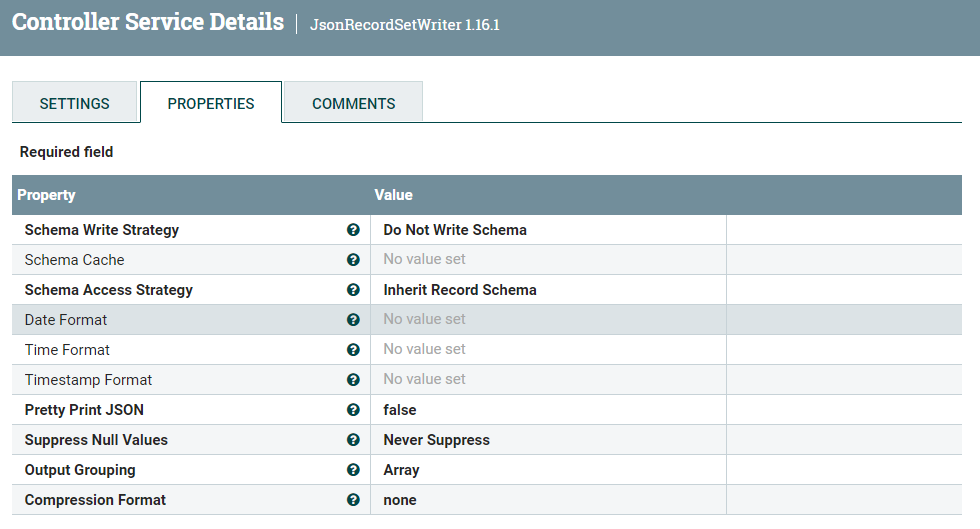
因为是进数据库,所以为了防止SQL注入,需要先做一些准备工作。
经过上一步,数据已经被拆分成一条条的json,现在就用EvaluateJsonPath提取相应的字段
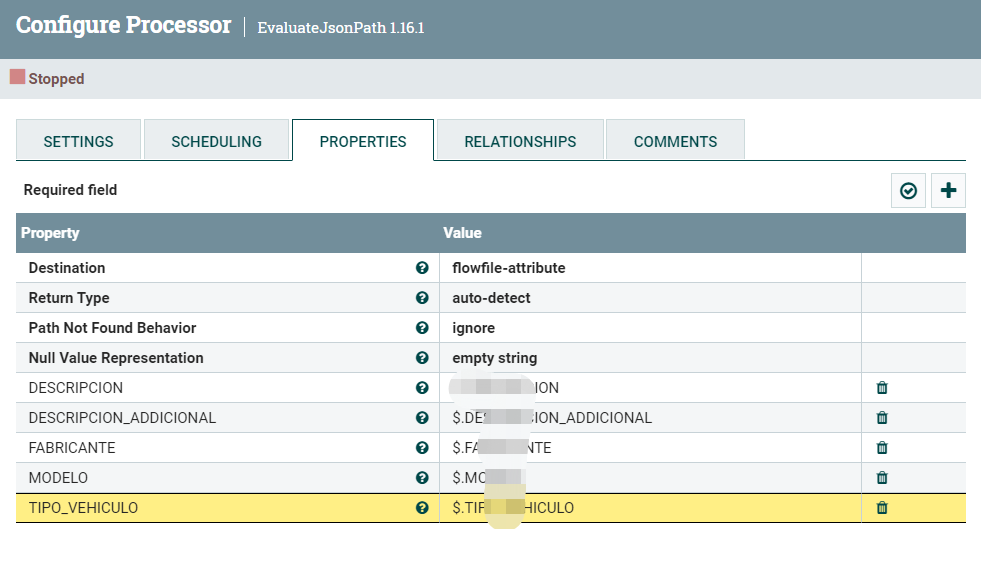
再用UpateAttribute组装成Sql语句需要的参数。关于sql.args.[*].type的值,请参考java.sql.Types
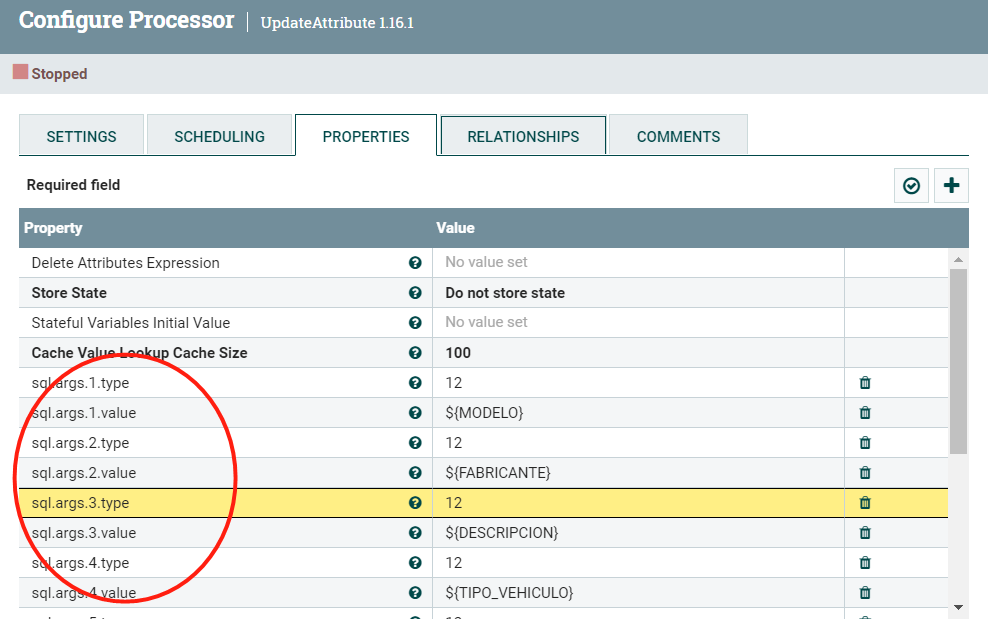
最后就是执行SQL语句了。这里有很多选择,可以用PutSQL,ExcuteSQL等。
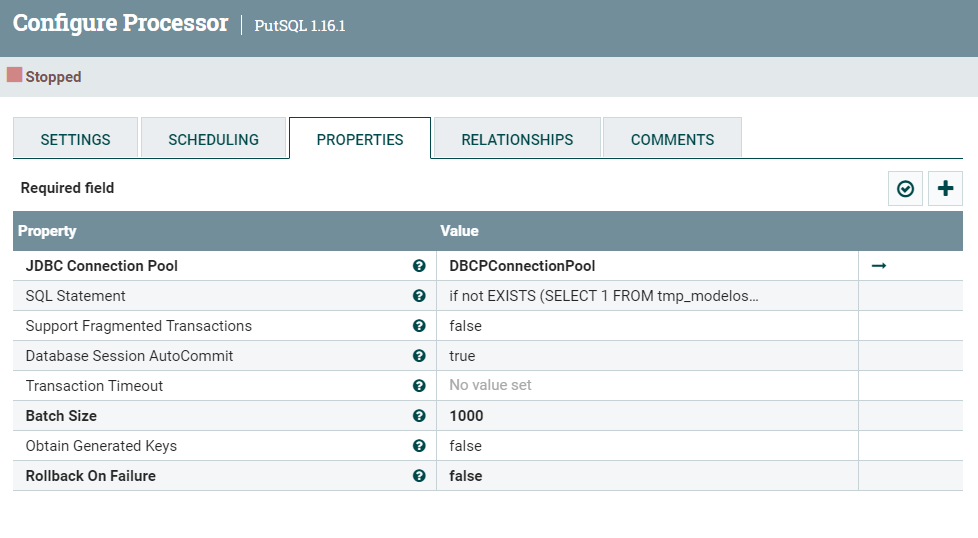
SQL Statement是这样的:
点击查看代码
if not EXISTS (SELECT 1 FROM tmp_modelos
WHERE MODELO=? AND FABRICANTE=? AND DESCRIPCION=? AND TIPO_VEHICULO=?)
INSERT INTO tmp_modelos (MODELO, FABRICANTE, DESCRIPCION, DESCRIPCION_ADDICIONAL, TIPO_VEHICULO) VALUES (?, ?, ?, ?, ?);
?代表参数,有多少?,sql.args属性就相对有几个,否则执行时会报参数不匹配。
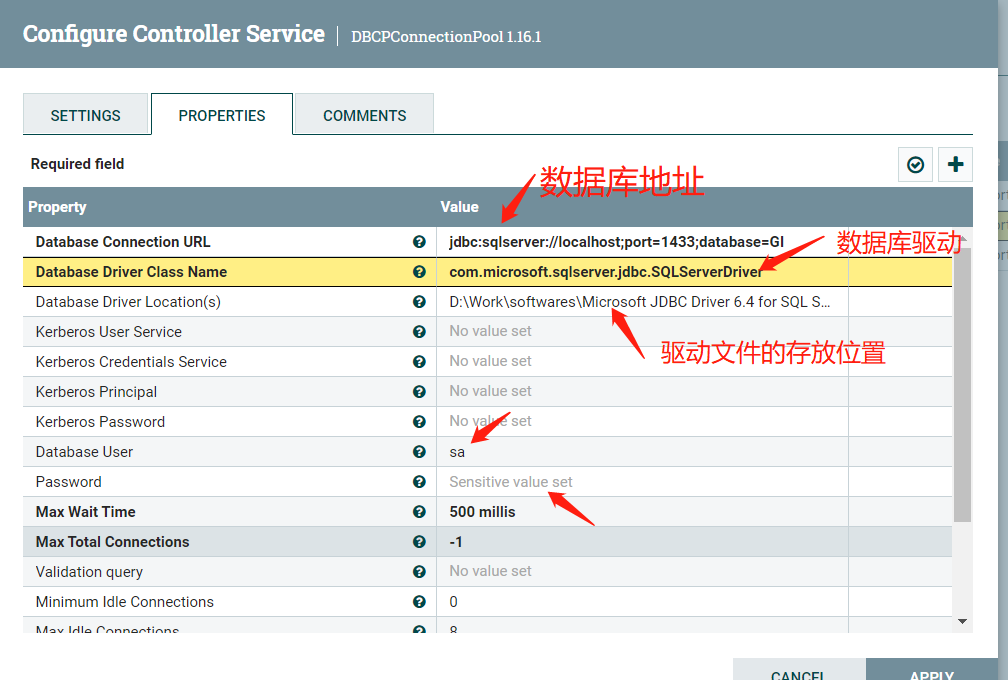
DBCPConnectionPool的设置如下:
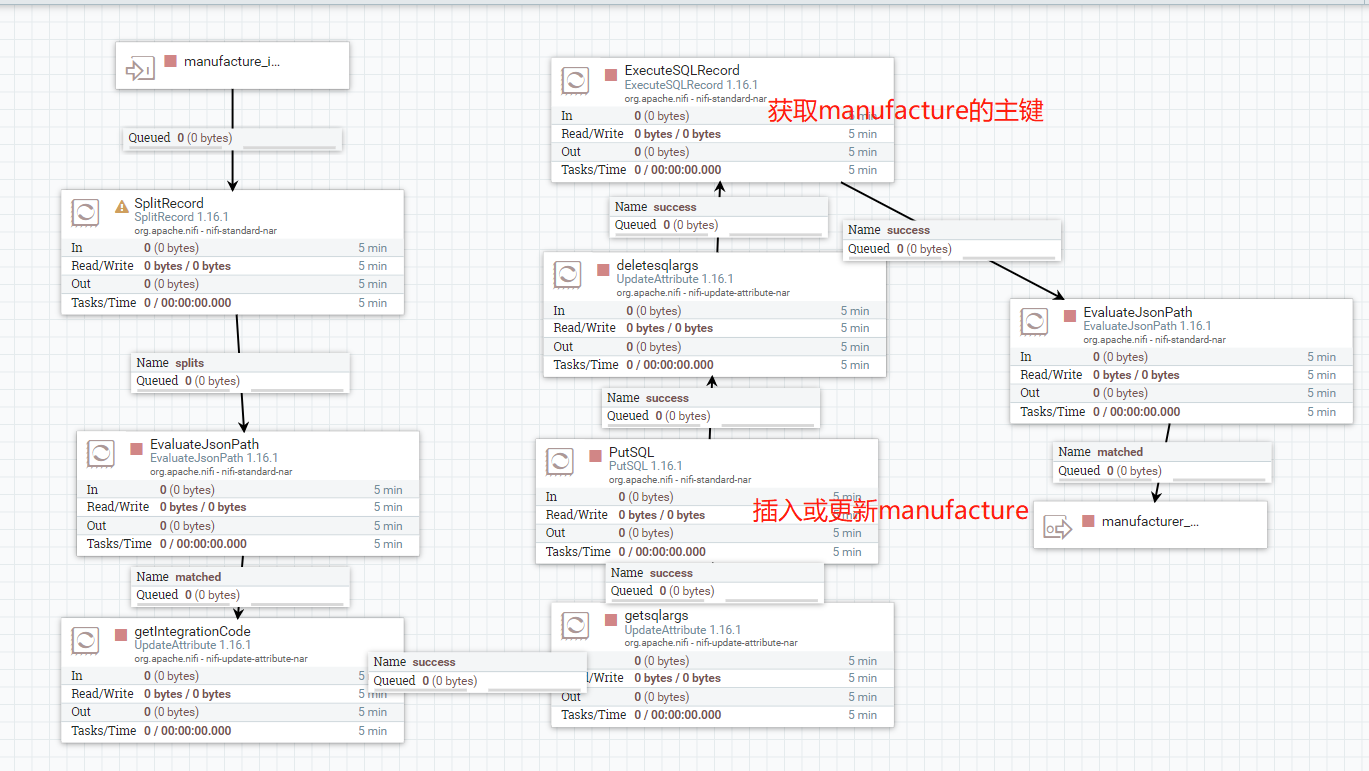
整个流程上要用的processor和controller service差不多就是上面这些,剩下的就是大家按需求组合了。
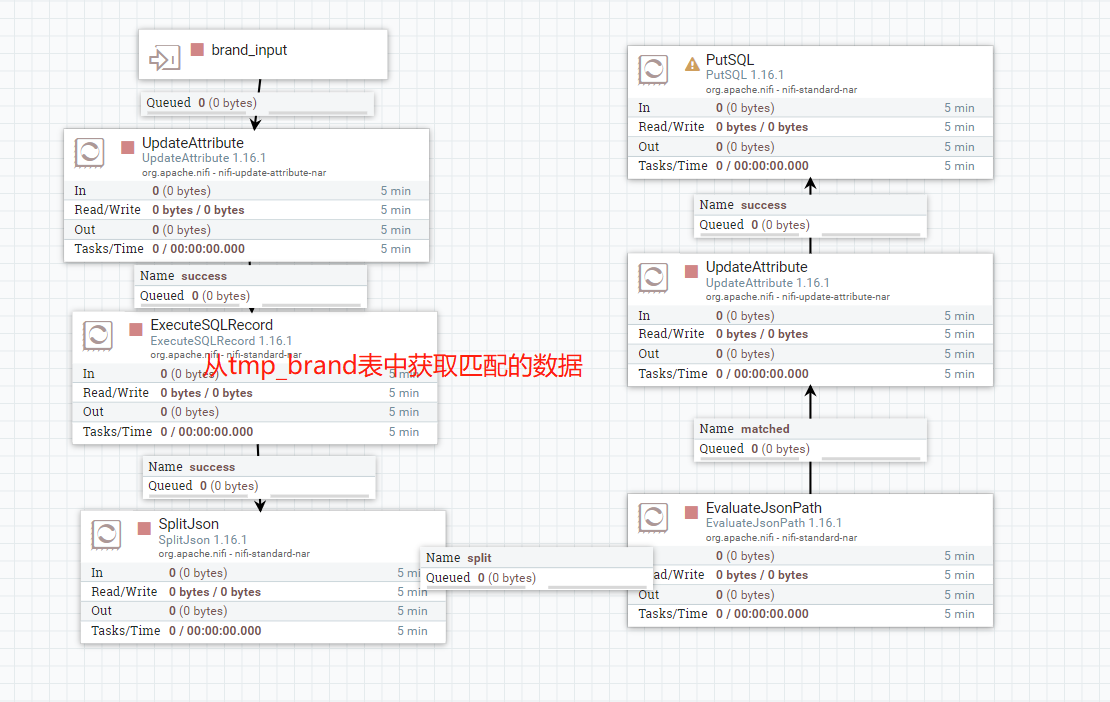
我剩下两个group里的流程是这样的。
还有一个很重要的,就是nifi所用的表达式,大家可以参考一下官方文档
好了,至此,我们的流程就已经画完了。接下来就是运行调试了。下篇再见!
nifi从入门到实战(保姆级教程)——flow的更多相关文章
- ElasticSearch入门篇(保姆级教程)
本章将介绍:ElasticSearch的作用,搭建elasticsearch的环境(Windows/Linux),ElasticSearch集群的搭建,可视化客户端插件elasticsearch-he ...
- RocketMQ保姆级教程
大家好,我是三友~~ 上周花了一点时间从头到尾.从无到有地搭建了一套RocketMQ的环境,觉得还挺easy的,所以就写篇文章分享给大家. 整篇文章可以大致分为三个部分,第一部分属于一些核心概念和工作 ...
- 保姆级教程——Ubuntu16.04 Server下深度学习环境搭建:安装CUDA8.0,cuDNN6.0,Bazel0.5.4,源码编译安装TensorFlow1.4.0(GPU版)
写在前面 本文叙述了在Ubuntu16.04 Server下安装CUDA8.0,cuDNN6.0以及源码编译安装TensorFlow1.4.0(GPU版)的亲身经历,包括遇到的问题及解决办法,也有一些 ...
- 自建本地服务器,自建Web服务器——保姆级教程!
搭建本地服务器,Web服务器--保姆级教程! 本文首发于https://blog.chens.life/How-to-build-your-own-server.html. 先上图!大致思路就是如此. ...
- Eclipse for C/C++ 开发环境部署保姆级教程
Eclipse for C/C++ 开发环境部署保姆级教程 工欲善其事,必先利其器. 对开发人员来说,顺手的开发工具必定事半功倍.自学编程的小白不知道该选择那个开发工具,Eclipse作为一个功能强大 ...
- 强大博客搭建全过程(1)-hexo博客搭建保姆级教程
1. 前言 本人本来使用国内的开源项目solo搭建了博客,但感觉1核CPU2G内存的服务器,还是稍微有点重,包括服务器内还搭建了数据库.如果自己开发然后搭建,耗费时间又比较多,于是乎开始寻找轻量型的博 ...
- nifi从入门到实战(保姆级教程)——环境篇
背景: 公司领导决定将各种基础数据的导入从代码中分离出来,用Apache Nifi替换.使开发者们更关注在业务上,而不用关心基础的由来. Apache Nifi对于整个团队都是一个全新的工具,之前大家 ...
- nifi从入门到实战(保姆级教程)——身份认证
上一篇我们搭建好了nifi的运行环境了 但是每次登陆那一串随机字符串的用户名和密码是不是让人很头疼,那是人类能记住的吗?当然不是!!!! 那么今天我们就来消灭这些难看又难记的字符串. windows( ...
- 保姆级教程!手把手教你使用Longhorn管理云原生分布式SQL数据库!
作者简介 Jimmy Guerrero,在开发者关系团队和开源社区拥有20多年的经验.他目前领导YugabyteDB的社区和市场团队. 本文来自Rancher Labs Longhorn是Kubern ...
随机推荐
- Anaconda下安装Tensorflow、keras问题及解决办法
这两天一直在跟tensorflow的错误日志作斗争!安装过程中出现各种问题,找资料,采坑,终于装好了,做个小总结! keras需要在TensorFlow之上才能运行,所以需要先安装TensorFlow ...
- css 动画 (2)
1. html 结构 <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- 使用 GO-CQHttp或mirai框架 搭建QQ的机器人
我的博客 Go-CQHttp搭建QQ机器人 官方文档在这-->ATRU官方文档 Go-CQHttp + Atri 使用Linux系统部署 需求 服务器一台/带有Linux的机器 Python环境 ...
- 一文学会text-justify,orientation,combine文本属性
大家好,我是半夏,一个刚刚开始写文的沙雕程序员.如果喜欢我的文章,可以关注 点赞 加我微信:frontendpicker,一起学习交流前端,成为更优秀的工程师-关注公众号:搞前端的半夏,了解更多前端知 ...
- k8s client-go源码分析 informer源码分析(1)-概要分析
k8s informer概述 我们都知道可以使用k8s的Clientset来获取所有的原生资源对象,那么怎么能持续的获取集群的所有资源对象,或监听集群的资源对象数据的变化呢?这里不需要轮询去不断执行L ...
- python matplotlib在mac os x 中如何显示中文,完美解决
一. 下载相关的中文字体 simhei 文件: 下载地址 二.通过以下代码查找matplotlib的数据存放位置: import matplotlib print(matplotlib.matplot ...
- Water 2.6.3 发布,一站式服务治理平台
Water(水孕育万物...) Water 为项目开发.服务治理,提供一站式解决方案(可以理解为微服务架构支持套件).基于 Solon 框架开发,并支持完整的 Solon Cloud 规范:已在生产环 ...
- 一、全新安装搭建redis主从集群
前言· 这里分为三篇文章来写我是如何重新搭建redis主从集群和哨兵集群的及原本服务器上有单redis如何通过升级脚本来实现redis集群.(redis结构:主-从(备)-从(备)) 至于为什么要搭建 ...
- 运维:DevSecOps
什么是DevSecOps DevSecOps 是一场关于 DevOps 概念实践或艺术形式的变革.DevOps之父Patrick Debios 强调:"DevOps2.0时代应首先解决人的问 ...
- 在Vmware虚拟机(win10)中安装逍遥安卓模拟器遇到的问题及解决办法
0x00 下载正确的安装包 逍遥模拟器官网:逍遥安卓模拟器下载官网 (xyaz.cn) 为什么要强调下载正确的安装包? 因为我在第一次下载的时候就下错了,下的是 逍遥模拟器 - 电脑玩手游神器 (me ...