Redis数据结构详解(2)-redis中的字典dict
前提知识
字典,又被称为符号表(symbol table)或映射(map),其实简单地可以理解为键值对key-value。
比如Java的常见集合类HashMap,就是用来存储键值对的。
字典中的键(key)都是唯一的,由于这个特性,我们可以根据键(key)查找到对应的值(value),又或者进行更新和删除操作。

字典dict的实现
Redis的字典使用了哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,每个节点也保存了对应的键值对。
Redis的字典dict结构如下:

typedef struct dict {
//类型特定函数
//是一个指向dictType结构的指针,可以使dict的key和value能够存储任何类型的数据
dictType *type;
//私有数据
//私有数据指针,不是讨论的重点,暂忽略
void *privdata;
//哈希表
dictht ht[2];
//rehash 索引
//当 rehash 不在进行时,值为 -1
int rehashidx;
}
我们重点关注两个属性就可以:
- ht 属性:
可以看到ht属性是一个 size为2 的 dictht哈希表数组,在平常情况下,字典只用到 ht[0],ht[1] 只会在对 ht[0] 哈希表进行rehash时才会用到。
- rehashidx 属性:
它记录了rehash目前的进度,如果现在没有进行rehash,那么它的值为-1,可以理解为rehash状态的标识。
下图就是一个普通状态下的字典:
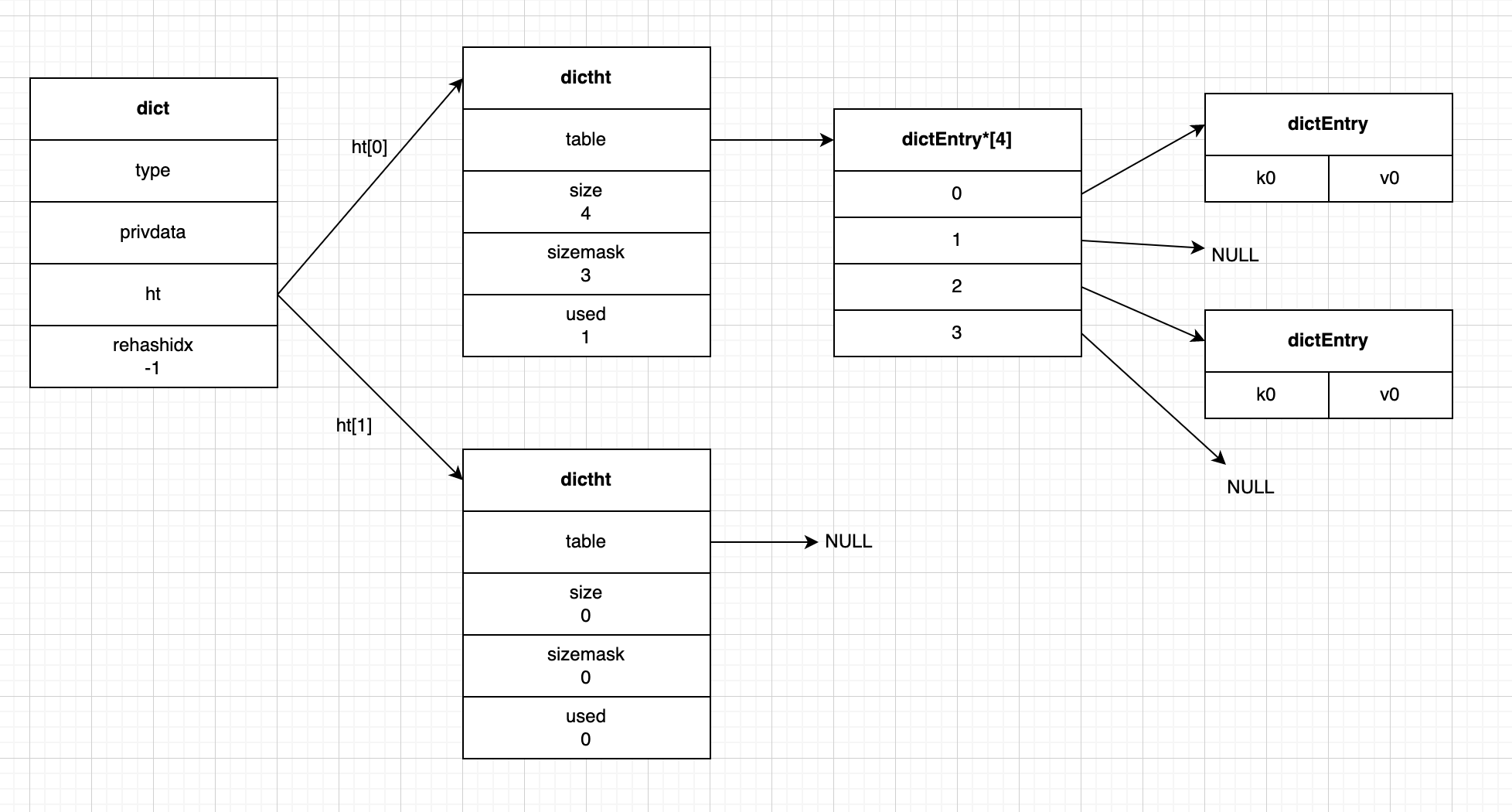
实际的数据在 ht[0] 中存储;ht[1] 起辅助作用,只会在进行rehash时使用,具体作用包括rehash的内容我们会在后面进行详细介绍。

哈希算法定位索引
PS:如果你有HashMap的相关知识,知道如何计算索引值,那么你可以跳过这一部分。
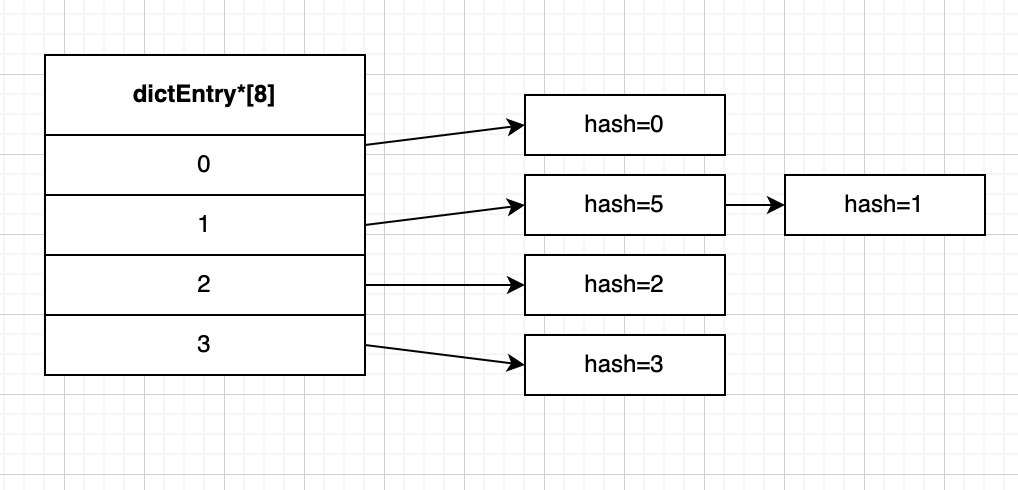
假如我们现在模拟将 hash值从0到5的哈希表节点 放入 size为4的哈希表数组 中,也就是将包含键值对的哈希表节点放在哈希表数组的指定索引上。
对应索引的计算公式:
index = hash & ht[x].sizemask
看不懂没关系,可以简单的理解为hash值对哈希表数组的size值求余;
比如上面 hash值为0的节点,0 % 4 = 0,所以放在索引0的位置上,
hash值为1的节点,1 % 4 = 1,所以放在索引1的位置上,
hash值为5的节点,5 % 4 = 1,也等于1,也会被分配在索引1的位置上,并且因为dictEntry节点组成的链表没有指向链表表尾的指针,所以会将新节点添加在链表的表头位置,排在已有节点的前面。
我们把上面索引相同从而形成链表的情况叫键冲突,而且因为形成了链表!那么就意味着查找等操作的复杂度变高了!
例如你要查找hash=1的节点,你就只能先根据hash值找到索引为1的位置,然后找到hash=5的节点,再通过next指针才能找到最后的结果,也就意味着键冲突发生得越多,查找等操作花费的时间也就更多。

如果解决键冲突?rehash!
其实rehash操作很好理解,可以简单地理解为哈希表数组扩容或收缩操作,即将原数组的内容重新hash放在新的数组里。
比如还是上面的数据,我们这次把它们放在 size等于8的哈希表数组 里。
如下图,此时size = 8,hash为5的键值对,重新计算索引:5 % 8 = 5,所以这次会放在索引5的位置上。
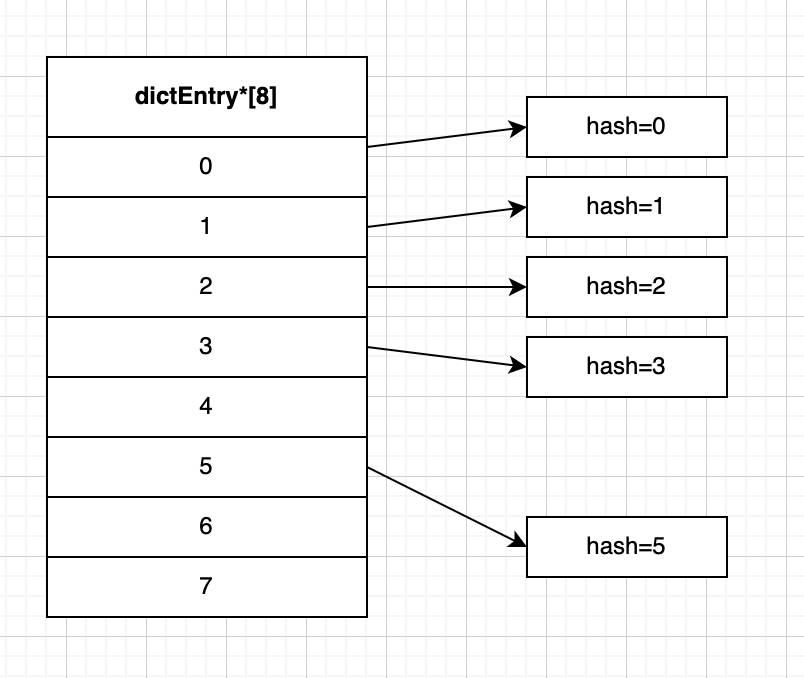
那么假如我们还要找hash=1的节点,因为没有键冲突,自然也没有链表,我们可以直接通过索引来找到对应节点。
可以看到,因为rehash操作数组扩容的缘故,键冲突的情况少了,进而我们可以更高效地进行查找等操作。
触发rehash操作的条件
首先我们先引入一个参数,叫做负载因子(load_factor),要注意的是:它与HashMap中的负载因子代表的含义不同;在HashMap里负载因子loadFactor作为一个默认值为0.75f的常量存在,而在redis的dict这里,它是一个会动态变化的参数,等于哈希表的 used属性值/size属性值,也就是 实际节点数/哈希表数组大小。假如一个size为4的哈希表有4个哈希节点,那么此时它的负载因子就是1;size为8的哈希表有4个哈希节点,那么此时它的负载因子就是0.5。
满足下面任一条件,程序就会对哈希表进行rehash操作:
- 扩容操作条件:
- 服务器目前没有执行 BGSAVE 或者 BGREWRITEAOF 命令,负载因子大于等于1。
- 服务器目前正在执行 BGSAVE 或者 BGREWRITEAOF 命令,负载因子大于等于5。
- 收缩操作条件:
- 负载因子小于0.1时。
BGSAVE 和 BGREWRITEAOF 命令可以统一理解为redis的实现持久化的操作。
- BGSAVE 表示通过fork一个子进程,让其创建RDB文件,父进程继续处理命令请求。
- BGREWRITEAOF 类似,不过是进行AOF文件重写。
渐进式rehash?rehash的过程是怎么样的?
首先我们知道redis是单线程,并且对性能的要求很高,但是rehash操作假如碰到了数量多的情况,比如需要迁移百万、千万的键值对,庞大的计算量可能会导致服务器在一段时间里挂掉!
为了避免rehash对服务器性能造成影响,redis会分多次、渐进式地进行rehash,即渐进式rehash。
(可以理解粗略地理解为程序有空闲再来进行rehash操作,不影响其他命令的正常执行)
对哈希表进行渐进式rehash的步骤如下:
- 首先为 ht[1] 哈希表分配空间,size的大小取决于要执行的操作,以及 ht[0] 当前的节点数量(即ht[0]的used属性值):
- 扩展操作,ht[1]的size值为第一个大于等于ht[0].used属性值乘以2的 2^n
- 收缩操作,ht[1]的size值为第一个小于ht[0].used属性值的 2^n
(有没有很熟悉,其实跟Java中的HashMap、ConcurrentHashMap操作类似)
- 将哈希表的rehashidx值从-1置为0,表示rehash工作开始。
- 节点转移,重新计算键的hash值和索引值,再将节点放置到ht[1]哈希表的对应索引位置上。
- 每次rehash工作完成后,程序会将rehashidx值加一。
(这里的每次rehash就指渐进式rehash)
- 当ht[0]的所有节点都转移到ht[1]之后,释放ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白的hash表,等待下次rehash再用到。(其实就是数据转移到ht[1]后,再恢复为 ht[0]储存实际数据,ht[1]为空白表的状态)
- 最后程序会将rehashidx的值重置为-1,代表rehash操作已结束。
进行渐进式rehash的时候会影响字典的其他操作吗?
因为在进行渐进式rehash的时候,字典会同时用到ht[0]和ht[1]这两个哈希表,所以在这期间,字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表进行;而进行添加操作时,会直接插入到ht[1]。
比如查找一个键时,程序会先在ht[0]里面查找,没找到的话再去ht[1]里进行查找。
搜资料的时候还看到好多评论,都对逻辑产生了疑问,还举了例子说有问题,但我仔细看了下,其实都是忽略了删除和更新都会在两个哈希表进行的前提条件。

写在最后的最后
我是苏易困,大家也可以叫我易困,一名Java开发界的小学生,文章可能不是很优质,但一定会很用心。
距离上次更新都过去了好久,一是因为上海的疫情有点严重,一直没静下心来好好整理知识,还有就是发现自己得先很好地消化完知识才能够整理出来,不然其实各方面收获不大;所以后面也会自己先认真消化后再整理分享,不会追求速度,但会认真总结整理。
因为疫情要一直封到4月1号,我们小区还有1例阳性,更不知道到什么时候了,每天早上也要定闹钟抢菜,但还抢不到,因为没有绿叶菜的补给,我感觉已经得口腔溃疡了,还好买到了维C泡腾片,感觉可以稍微缓缓。
疫情掰扯这么多,其实我和大家一样,我有想吃的美食,有想去的地方,更有马上想见到的人,所以最后还是希望疫情能够赶紧好起来~

Redis数据结构详解(2)-redis中的字典dict的更多相关文章
- 5种Redis数据结构详解
本文主要和大家分享 5种Redis数据结构详解,希望文中的案例和代码,能帮助到大家. 转载链接:https://www.php.cn/php-weizijiaocheng-388126.html 2. ...
- Redis数据结构详解之List(二)
序言 思来想去感觉redis中的list没什么好写的,如果单写几个命令的操作过于乏味,所以本篇最后我会根据redis中list数据类型的特殊属性,同时对比成熟的消息队列产品rabbitmq,使用red ...
- Redis数据结构详解,五种数据结构分分钟掌握
redis数据类型分为:字符串类型.散列类型.列表类型.集合类型.有序集合类型.redis这么火,它运行有多块?一台普通的笔记本电脑,可以在1秒钟内完成十万次的读写操作.原子操作:最小的操作单位,不能 ...
- redis 数据类型详解 以及 redis适用场景场合
1. MySql+Memcached架构的问题 实际MySQL是适合进行海量数据存储的,通过Memcached将热点数据加载到cache,加速访问,很多公司都曾经使用过这样的架构,但随着业务数据量的 ...
- 【Redis】Redis事务详解,Redis事务支持回滚(不支持悲观锁)
1.redis事物参考:https://baijiahao.baidu.com/s?id=1613631210471699441&wfr=spider&for=pc (php操作red ...
- redis 数据类型详解 以及 redis适用场景场合(滴滴)
滴滴的面试官问了个问题关于redis的: 我现在想服务器每分钟接收一个用户的请求小于60个,如何处理: 答:使用Redis 缓存服务器,可以设置key=用户ID value不停地加一到了60就停止,然 ...
- Redis数据结构详解(1)-redis中的字符串(SDS)
前提知识 我们先从百科上摘下Redis的解释: Redis是一个使用ANSI C编写的开源.支持网络.基于内存.分布式.可选持久性的键值对存储数据库. (不用过多在意ANSI,它只是一个标准,你可以理 ...
- redis数据结构详解之Hash(四)
序言 Hash数据结构累似c#中的dictionary,大家对数组应该比较了解,数组是通过索引快速定位到指定元素的,无论是访问数组的第一个元素还是最后一个元素,所耗费的时间都是一样的,但是数组中的索引 ...
- Redis数据结构详解之Zset(五)
序言 Zset跟Set之间可以有并集运算,因为他们存储的数据字符串集合,不能有一样的成员出现在一个zset中,但是为什么有了set还要有zset呢?zset叫做有序集合,而set是无序的,zset怎么 ...
随机推荐
- Solution -「BJWC 2018」「洛谷 P4486」Kakuro
\(\mathcal{Description}\) Link. 有一个 \(n\times m\) 的网格图,其中某些格子被主对角线划成两个三角形,称这样的格子为特殊格:初始时,除了一些障碍格 ...
- Spring 控制反转和依赖注入
控制反转的类型 控制反转(IOC)旨在提供一种更简单的机制,来设置组件的依赖项,并在整个生命周期管理这些依赖项.通常,控制反转可以分成两种子类型:依赖注入(DI)和依赖查找(DL),这些子类型各自又可 ...
- JAVA8学习——从使用角度深入Stream流(学习过程)
Stream 流 初识Stream流 简单认识一下Stream:Stream类中的官方介绍: /** * A sequence of elements supporting sequential an ...
- 自助式BI工具怎么选?这款用过都说好!
随着大数据时代的到来,很多公司的业务数据量不断增长,公司必须集中精力管理数据,并在BI工具的帮助下进行数据分析,以便从过去的数据中获得洞察力,预测未来的发展.近年来,随着企业对数据的关注度的增加,企业 ...
- Linux性能优化实战CPU篇之软中断(三)
一.软中断 1,中断的定义 a>定义 举例:你点了一份外卖,在无法获知外卖进度的情况下,配送员送外卖是不等人的,到了发现没人取会直接走,所以你只能苦苦等着,时不时去门口看送到没有,无法干别的事情 ...
- 【C# 异常处理】调试器 管理异常
装载自:https://docs.microsoft.com/zh-cn/visualstudio/debugger/managing-exceptions-with-the-debugger?vie ...
- Linux修改权限命令chmod用法示例
Linux公社 2020年10月13日 来自:Linux迷 网址:https://www.linuxmi.com/linux-chmod.html Linux中的Chmod命令用于更改或分配文件和目录 ...
- ImageNet2017文件介绍及使用
ImageNet2017文件介绍及使用 文件说明 imagenet_object_localization.tar.gz包含训练集和验证集的图像数据和地面实况,以及测试集的图像数据. 图像注释以PAS ...
- 人工智能之深度学习-初始环境搭建(安装Anaconda3和TensorFlow2步骤详解)
前言: 本篇文章主要讲解的是在学习人工智能之深度学习时所学到的知识和需要的环境配置(安装Anaconda3和TensorFlow2步骤详解),以及个人的心得体会,汇集成本篇文章,作为自己深度学习的总结 ...
- 阿里云 elk 搭建
1.logstash通过redis收集日志. logstash > redis>logstash >es k8s日志挂载 tong sudo umount -t glusterfs ...