MapRudecer
MapReducer基本概念

Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
基本结构
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、mapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程
MR运行流程图
1、 一个mr程序启动的时候,最先启动的是MRAppMaster,MRAppMaster启动后根据本次job的描述信息,计算出需要的maptask实例数量,然后向集群申请机器启动相应数量的maptask进程
2、 maptask进程启动之后,根据给定的数据切片范围进行数据处理,主体流程为:
a) 利用客户指定的inputformat来获取RecordReader读取数据,形成输入KV对
b) 将输入KV对传递给客户定义的map()方法,做逻辑运算,并将map()方法输出的KV对收集到缓存
c) 将缓存中的KV对按照K分区排序后不断溢写到磁盘文件
3、 MRAppMaster监控到所有maptask进程任务完成之后,会根据客户指定的参数启动相应数量的reducetask进程,并告知reducetask进程要处理的数据范围(数据分区)
4、 Reducetask进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台maptask运行所在机器上获取到若干个maptask输出结果文件,并在本地进行重新归并排序,
然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算,并收集运算输出的结果KV,然后调用客户指定的outputformat将结果数据输出到外部存储
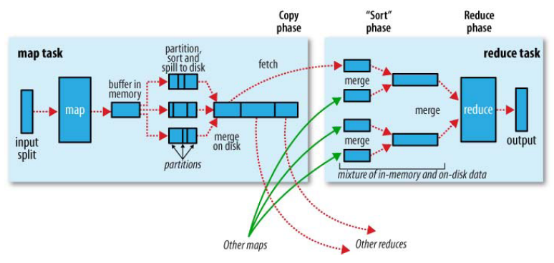
MapTask
详见:org.apache.hadoop.mapred.MapTask
- 每一个切片都会分配一个Mapper任务,Mapper任务结束后产生<K2,V2>的输出,这些输出先存放在缓存中,每个map有一个环形内存缓冲区(org.apache.hadoop.mapred.MapTask.MapOutputBuffer),用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。(注意:map过程的输出是写入本地磁盘而不是HDFS,但是一开始数据并不是直接写入磁盘而是缓冲在内存中,缓存的好处就是减少磁盘I/O的开销,提高合并和排序的速度。又因为默认的内存缓冲大小是100M(当然这个是可以配置的),所以在编写map函数的时候要尽量减少内存的使用,为shuffle过程预留更多的内存,因为该过程是最耗时的过程。)
- 写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。(注意:在写磁盘的时候采用压缩的方式将map的输出结果进行压缩是一个减少网络开销很有效的方法!)
ReducerTask
- Copy阶段:Reducer通过Http方式得到输出文件的分区。
- 从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
- Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中。(注意:当Reducer的输入文件确定后,整个Shuffle操作才最终结束。之后就是Reducer的执行了,最后Reducer会把结果存到HDFS上。)
Shuffle
mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle;
shuffle: 洗牌、发牌——(核心机制:数据分区,排序,缓存);
具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;
Shuffle整体来看,分为3个操作:
1、分区partition
2、Sort根据key排序
3、Combiner进行局部value的合
Combiner
(1)combiner是MR程序中Mapper和Reducer之外的一种组件
(2)combiner组件的父类就是Reducer
(3)combiner和reducer的区别在于运行的位置:
Combiner是在每一个maptask所在的节点运行
Reducer是接收全局所有Mapper的输出结果;
(4) combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量
MapTask并行度
一个job的map阶段并行度由客户端在提交job时决定
而客户端对map阶段并行度的规划的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每一个split分配一个mapTask并行实例处理
FileInputFormat中默认的切片机制
a) 简单地按照文件的内容长度进行切片
b) 切片大小,默认等于block大小
c) 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
|
file1.txt 320M file2.txt 10M |
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
|
file1.txt.split1-- 0~128 file1.txt.split2-- 128~256 file1.txt.split3-- 256~320 file2.txt.split1-- 0~10M |
FileInputFormat中切片的大小的参数配置
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize)); 切片主要由这几个值来运算决定
|
minsize:默认值:1 配置参数: mapreduce.input.fileinputformat.split.minsize |
|
maxsize:默认值:Long.MAXValue 配置参数:mapreduce.input.fileinputformat.split.maxsize |
|
blocksize |
因此,默认情况下,切片大小=blocksize
maxsize(切片最大值):
参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值
minsize (切片最小值):
参数调的比blockSize大,则可以让切片变得比blocksize还大
选择并发数的影响因素:
1、运算节点的硬件配置
2、运算任务的类型:CPU密集型还是IO密集型
3、运算任务的数据量
ReducerTask并行度
reducetask的并行度同样影响整个job的执行并发度和执行效率,但与maptask的并发数由切片数决定不同,Reducetask数量的决定是可以直接手动设置:
//默认值是1,手动设置为4
job.setNumReduceTasks(4);
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意: reducetask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reducetask
尽量不要运行太多的reduce task。对大多数job来说,最好rduce的个数最多和集群中的reduce持平,或者比集群的 reduce slots小。这个对于小集群而言,尤其重要。
MapRudecer的更多相关文章
随机推荐
- AndroidStudio 添加 AndroidAnnotations
1.添加对apt的依赖 buildscript { repositories { mavenCentral() } dependencies { classpath 'com.neenbedankt. ...
- winform 实现彩票功能
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/MrTraum/article/details/32702319 watermark/2/text/a ...
- 【PHP后台】接入支付宝
我使用PHP主要是为客户端做后台使用,并不会做前端网页. 这两天因为公司项目需要,必须接入支付功能,而支付宝当然首当其冲,考虑迭代版本的需要,首先接入支付宝功能,其他的支付功能以后迭代版本的时候 ...
- 优雅的QSignleton (四) 通过属性器实现MonoSingleton
大家都出去过周六了,而我却在家写代码T.T... 接下来介绍通过属性器实现MonoSingleton. 代码如下: MonoSingletonProperty.cs namespace QFr ...
- Oracle中with关键字的使用
open p_cr1 for with sqla as (select d.*, (select c.STATICMONTH from ly_zg_jzfbtstatic c where c.ID = ...
- python之selectors
selectors是select模块的包装器,ptython文档建议大部分情况使用selectors而不是直接使用selectors 样例代码如下 # -*- coding: utf-8 -*- __ ...
- 关于对连接数据库时出现1130-host “**” is not allowed to connect to this MySql/mariadb server 的错误解决方法
在完成mariadb的搭建后,在端口与防火墙均为正常的情况下,出现了1130- Host xxx is not allowed to connect to this MariaDb server 的情 ...
- 【c学习-13】
/*库函数 1:数学函数库:math.h abs():绝对值; acos(),asin(),atan():cos,sin,tan的倒数 exp():指数的次幂 pow(x,y):x的y次幂 log() ...
- JS如何给ul下的所有li绑定点击事件,点击使其弹出下标和内容
这是一个非常常见的面试题,出题方式多样,但考察点相同,下面我们来看看这几种方法:方法一: var itemli = document.getElementsByTagName("li&quo ...
- c# WebBrowser开发参考资料--杂七杂八
c# WebBrowser开发参考资料 http://hi.baidu.com/motiansen/blog/item/9e99a518233ca3b24aedbca9.html=========== ...