大小端,"字节序"
2 字节序
2.1 字节
字节(Byte)作为计算机世界的计量单位,和大家手中的人民币多少多少“元”一个意思。反正,到了计算机的世界,说字节就对了,使用人家的基本计量单位,这是入乡随俗。
比如,一个电影是1G个字节(1GB),一首歌是10M个字节(10MB),一张图片是1K个字节(1KB)。
2.2 字节序
一元钱可以干嘛?啥也干不了,公交都不够坐的。一个字节可以干嘛?至少可以存一个字符。
当数据太大,一个字节存不下的时候,我们就得使用多个字节了。比如,我有两个分别需要4个字节存储的整数,为了方便说明,使用16进制表示这两个数,即0x12345678和0x11223344。有的人采用以下方式存储这个两个数字:

这个方案看起来不错,但是,又有人采用了以下方式:

蒙圈了吧,到底该用哪一种方式来存!两种方案虽有不同,但也有共识,即依次存储每一个数字,即先存0x12345678,再存0x11223344。大家的分歧在于,对于某一个要表示的值,因为只能一个字节一个字节的存嘛,我是把值的低位存到低地址,还是把值的高位存到低地址。前者使用的是“小端(Little endian)”字节序,即先存低位的那一端(两个数字的最低位分别是0x78、0x44),如上图中的第一个图;后者使用的是“大端(Big endian)”字节序,即先存高位的那一端(两个数字的最高位分别是0x12、0x11),如上图中的第二个图。
由此也引发了计算机界的大端与小端之争,不同的CPU厂商并没有达成一致:
- x86,MOS Technology 6502,Z80,VAX,PDP-11等处理器为Little endian。
- Motorola 6800,Motorola 68000,PowerPC 970,System/370,SPARC(除V9外)等处理器为Big endian。
- ARM, PowerPC (除PowerPC 970外), DEC Alpha, SPARC V9, MIPS, PA-RISC and IA64的字节序是可配置的。
大端也好,小端也罢,就权当是个人爱好吧,只要你不影响别人就行,对不?
2.3 网络字节序
前面的大端和小端都是在说计算机自己,也被称作主机字节序。其实,只要自己能够自圆其说是没啥问题的。问题是,网络的出现使得计算机可以通信了。通信,就意味着相处,相处必须得有共同语言啊,得说普通话,要不然就容易会错意,下了一个小时的小电影发现打不开,理解错误了!
但是每个计算机都有自己的主机字节序啊,还都不依不饶,坚持做自己,怎么办?
TCP/IP协议隆重出场,RFC1700规定使用“大端”字节序为网络字节序,其他不使用大端的计算机要注意了,发送数据的时候必须要将自己的主机字节序转换为网络字节序(即“大端”字节序),接收到的数据再转换为自己的主机字节序。这样就与CPU、操作系统无关了,实现了网络通信的标准化。突然觉得,TCP/IP协议好任性啊有木有!
为了程序的兼容,你会看到,程序员们每次发送和接受数据都要进行转换,这样做的目的是保证代码在任何计算机上执行时都能达到预期的效果。
这么常用的操作,BSD Socket提供了封装好的转换接口,方便程序员使用。包括从主机字节序到网络字节序的转换函数:htons、htonl;从网络字节序到主机字节序的转换函数:ntohs、ntohl。当然,有了上面的理论基础,也可以编写自己的转换函数。
下面的一段代码可以用来判断计算机是大端的还是小端的,判断的思路是确定一个多字节的值(下面使用的是4字节的整数),将其写入内存(即赋值给一个变量),然后用指针取其首地址所对应的字节(即低地址的一个字节),判断该字节存放的是高位还是低位,高位说明是Big endian,低位说明是Little endian。
#include <stdio.h>
int main ()
{
unsigned int x = 0x12345678;
char *c = (char*)&x;
if (*c == 0x78) {
printf("Little endian");
} else {
printf("Big endian");
}
return 0;
}
2.4 身边的字节序
字符编码方式UTF-16、UTF-32同样面临字节序的问题,因为他们分别使用2个字节和4个字节编码Unicode字符,一旦某个值用多个字节表示,就必须要考虑存储的顺序了。于是,采用了最简单粗暴的方式,给文件头部写几个字符,用来表示是大端呢还是小端:
头部的字符 编码 字节序 FF FE UTF-16/UCS-2 Little endian FE FF UTF-16/UCS-2 Big endian FF FE 00 00 UTF-32/UCS-4 Little endian 00 00 FE FF UTF-32/UCS-4 Big-endian
这里不得不提一下UTF-8啊,明明人家是单个字节的,不存在什么字节序的问题。微软为了统一UTF-X,硬生生给他的头部也加了几个字符!是的,这几个字符就是BOM(Byte Order Mark),这就是Windows下的UTF-8。
相信很多人都被UTF-8的BOM给坑过,多了这个BOM的UTF-8文件,会导致很多问题啊。比如,写的Shell脚本,内容为#!/usr/bin/env bash,在UTF-8有BOM和UTF-8无BOM的编码下,对应的16进制为:
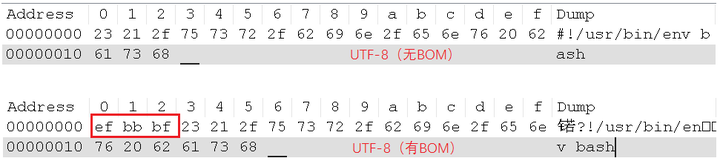
所以,有BOM的话,Shell解释器就报错啦。原因在于,解释器希望遇到#!/usr/bin/env bash,而使用UTF-8有BOM进行编码的内容会多了3个字节的EF BB BF。
对于UTF-8和UTF-8无BOM两种编码格式,我们更多的使用UTF-8无BOM。
大小端,"字节序"的更多相关文章
- 从inet_pton()看大小端字节序
#include<stdio.h> #include<netinet/in.h> #include<stdlib.h> #include<string.h&g ...
- [C/C++]大小端字节序转换程序
计算机数据存储有两种字节优先顺序:高位字节优先(称为大端模式)和低位字节优先(称为小端模式). 大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿 ...
- linux kernel如何处理大端小端字节序
(转)http://blog.csdn.net/skyflying2012/article/details/43771179 最近在做将kernel由小端处理器(arm)向大端处理器(ppc)的移植的 ...
- 大端字节序&小端字节序(网络字节序&主机字节序)
大端字节序:整数的高位字节存储在内存的低地址处,低字节存储在内存的高地址处. 小端字节序:整数的高位字节存储在内存的高地址处,低字节存储在内存的低地址处. 一般pc大多采用小端字节序,也称为主机字节序 ...
- 写一个c程序辨别系统是大端or小端字节序
字节序有两种表示方法:大端字节序(big ending),小端字节序(little ending) 看一个unsigned short 数据,它占2个字节,给它赋值0x1234.若采用的大端字节序, ...
- C语言 大小端 字节对齐
参考:http://www.cnblogs.com/graphics/archive/2011/04/22/2010662.html 1. 大端序:数据的高位字节存放在地址的低端,低位字节存放在地址的 ...
- c/c++字节序转换(转)
字节序(byte order)关系到多字节整数(short/int16.int/int32,int64)和浮点数的各字节在内存中的存放顺序.字节序分为两种:小端字节序(little endian)和大 ...
- linux的大小端、网络字节序问题 .
1.80X86使用小端法,网络字节序使用大端法. 2.二进制的网络编程中,传送数据,最好以unsigned char, unsigned short, unsigned int来处理, unsigne ...
- linux网路编程:字节序(大端、小端、网络、主机)
字节序:就是数据在内存中的存放顺序,也可称之为端模式. 大端模式和小端模式的定义 1) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端. 2) Big-End ...
随机推荐
- poj3190
一.题意:有n头牛,每头牛需要占用一个时间段的时间来挤奶,且必须有机器.问最少需要多少个机器 二.思路:区间贪心.把尽量多的牛放在一个棚子里,这样就可以使得用到的棚子数最少.只要任意两头牛的挤奶时间不 ...
- jmeter发送邮件的模板
<hr/> (本邮件是程序自动下发的,请勿回复!)<br/><hr/> 项目名称:$PROJECT_NAME<br/><hr/> 构建编号: ...
- python_学生信息管理实例
"""提示:代码中的内容均被注释,请参考,切勿照搬""" """注意:代码切勿照搬,错误请留言指出" ...
- spark ALS 推荐算法参数说明
- (转)expfilt 命令
expfilt 命令 原文:https://www.ibm.com/support/knowledgecenter/zh/ssw_aix_72/com.ibm.aix.cmds2/expfilt.ht ...
- 案例46-crm练习客户登录
1 login.jsp代码 <%@ page language="java" contentType="text/html; charset=UTF-8" ...
- HDU 5289——Assignment——————【RMQ+优化求解】
Assignment Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total ...
- BNU7538——Clickomania——————【区间dp】
Clickomania Time Limit: 10000ms Memory Limit: 32768KB 64-bit integer IO format: %I64d Java clas ...
- HDU 1698——Just a Hook——————【线段树区间替换、区间求和】
Just a Hook Time Limit:2000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Submit ...
- 精简版LINUX系统---wdOS
wdOS是一个基于CentOS版本精简优化过的Linux服务器系统,网站服务器系统并集成nginx,apache,php,mysql等web应用环境及wdcp管理系统,安装完系统,所有的都安装完成装好 ...